



 本文深入探讨ElasticSearch,一种基于RESTful的全文搜索和分析引擎,覆盖其架构、核心概念、常用操作及深入理解,适合希望掌握ElasticSearch核心技术的读者。
本文深入探讨ElasticSearch,一种基于RESTful的全文搜索和分析引擎,覆盖其架构、核心概念、常用操作及深入理解,适合希望掌握ElasticSearch核心技术的读者。
1. ElasticSearch简介
ElasticSearch是一个基于RESTful web接口并且构建在Apache Lucene之上的高度可伸缩的开源全文搜索和分析引擎。它允许你以近实时的方式快速存储、搜索和分析大量的数据。它通常被用作基础的技术来赋予应用程序复杂的搜索特性和需求。
同时ES还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,能够横向扩展至数以百计的服务器存储以及处理PB级的数据。可以在极短的时间内存储、搜索和分析大量的数据。通常作为具有复杂搜索场景情况下的核心发动机。

1. Gateway是es用于存储索引的文件系统,支持多种文件类型,如图所示。
2. Gateway往上就是分布式的Lucene框架,ES底层的API是由这一层提供的,每个节点都有一个Lucene引擎的支持。
3. Lucene往上是Elasticsearch的模块,包括索引模块、搜索模块、映射解析模块等。River相当于第三方插件,用来导入第三方数据源,在2.x之后不再使用。
4. ES模块之上是Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要消息通信,集群内部选主master都是通过Discovery来做。Scripting用来支持JavaScript、Python等多语言,可以在查询语句中嵌入。
5. 再往上是传输模块和JMX。传输模块支持Thrift、Memcached、HTTP,默认HTTP传输。JMX是java的管理框架。
6. 再往上是ES提供给用户的接口,通过RESTful API和ES集群进行交互。
2. ElasticSearch核心概念
-
近实时(NRT)
ElasticSearch是一个接近实时的搜索平台,从索引一个文档直到这个文档能够被搜索到有一个很小的延时(通常是1s)。
-
集群(cluster)
集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ES是去中心化的,也就是没有中心节点,这是对于集群外部来说的,因为从外部来看ES集群,在逻辑上是一个整体,与任何一个节点的通信和与整个ES集群通信是等价的。
-
节点(node)
节点属于集群中的单台服务器,存储数据并参与集群的索引和搜索功能。一个节点由一个名称来标识。
可以将节点配置为按集群名称加入特定集群。默认情况下,每个节点都设置为加入一个名为elasticsearch的集群,如果启用网络中的多个节点并假设他们可以互相发现,他们将自动形成并加入名为elasticsearch的集群。
在一个集群中,可以拥有任意数量的节点。如果网络上没有其他节点正在运行,则启动单个节点后将组成单节点集群。
-
分片(shard)
一台服务器,无法存储大量的数据,为了解决这个问题,ES提供了分片的功能,把index分成多个shard,分布式存储在各个服务器上。在定义一个index时,可以简单定义想要的分片的数量,每个分片本身是一个全功能的完全独立的”index“,可以部署在集群中的任何节点上。一个分片是如何被分配以及文档是如何被聚集起来以完成搜索请求,这些是由ES完全管理的,并且对用户透明。
-
副本(replica)
在分布式集群中,难免会有一台或多台服务器宕机,为了保证数据的安全,引入了replica的概念。replica的出现将shard分为primary shard和replica shard,通常,primary shard提供读写功能,而replica仅提供读功能。
总结:主分片和复制分片的数量可以在索引被创建时指定,索引被创建后,可以随时动态修改复制分片的数量,但是不能修改主分片的数量。默认情况下,ES中的每个index被分配5个主分片和一份拷贝,因此,如果集群中至少有两个节点,索引将会有5个主分片和5个复制分片,共10个分片。主分片和复制分片不会出现在同一台机器上,就是拥有相同数据的分片不会出现在同一个节点上面,当集群中只有一个节点时,ES不会吧复制分片存在这个节点上,当有新节点加入时,会自动在新节点上创建之前分片的副本。
-
索引(index)
ES将数据存储在一个或多个索引中,索引类似于SQL中的数据库,可以进行文档的写入和读取。
-
类型(type)
类型用来定义数据结构,一个index下面可以有一个或多个type,类似于SQL中的一张表。
注意:类型在6.0以后版本中被弃用。
-
文档(document)
ES中的主要实体,是ES中的最小数据单元,可以认为一个文档就是一条记录,类似于SQL中数据表中的一条数据。
-
字段(field)
关系型数据库中列的概念,一个document由一个或多个field组成。
3. ElasticSearch常用操作
ES提供了非常全面和强大的REST API,可以通过API与集群进行交互,API可以完成如下的功能:
- 检查集群,节点和索引的健康状况,状态和统计数据;
- 管理集群,节点和索引的数据和原数据;
- 执行CRUD(增删改查)操作,依靠索引进行搜索;
- 执行高级的搜索操作,比如分页,排序,过滤,脚本化,聚集等。
3.1 查看集群健康状态
GET _cat/health
Result:1570620061 11:21:01 my-application yellow 1 1 3 3 0 0 1 0 - 75.0%
集群健康状态有三种取值:
- Green:一切运行正常,(集群功能齐全);
- Yellow:所有数据都是可以获取的,但一些复制还没有被分配(集群功能齐全)
- Red:一些数据因为一些原因获取不到(集群部分功能不可用)。
注意:当一个集群处于red状态时,它会通过可用的分片继续提供搜索服务,但是当有未分配的分片时,需要尽快修复。
3.2 管理集群
- 获取集群中所有index
GET _cat/indices
Result:
green open .kibana_task_manager ViPIRzczQzqUtBStFFqL0A 1 0 2 0 12.7kb 12.7kb
yellow open myindices G5gdedKfRFm2Q2Q4OAgmtQ 1 1 1 0 3.7kb 3.7kb
green open .kibana_1 q-cawcrLQCa-Tk6Cm3VwnA 1 0 5 0 39.3kb 39.3kb
3.3 CURD操作
PUT类似于SQL中的增
DELETE类似于SQL中的删
POST类似于SQL中的改
GET类似于SQL中的查
- 增加索引
PUT /indicestest1
Result:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "indextest1"
}
- 删除索引
DELETE /indextest2
Result:
{
"acknowledged" : true
}
- 索引中增加文档
PUT /indextest1/doc1/1
{
"name": "张三",
"age": 20
}
- 查询文档
GET /indextest1/doc1/1
Result:
{
"_index" : "indextest1",
"_type" : "doc1",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三",
"age" : 20
}
}
- 修改文档
POST /indextest1/doc1/1
{
"name": "张三",
"age": 23
}
Result:
{
"_index" : "indextest1",
"_type" : "doc1",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
- 索引中删除文档
DELETE indextest/doc1/1
4. ElasticSearch深入理解
-
4.1 CURD原理
-
(1)路由算法
shard = hash(routing) % number_of_primary_shards
1. shard是指document通过该路由算法会落到那个shard上;
2. number_of_primary_shards指的是创建时指定的primary shard数量;
3. 每次增删改查的一个document的时候,会带过来一个routing number,默认就是这个document的id(可能是自动生成,也可能是创建document的时候指定生成),routing值也是可以手动指定的,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的。如下指定routing值为userid
put /index/type/id?routing=user_id
注意:手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的。
-
(2)增删改原理
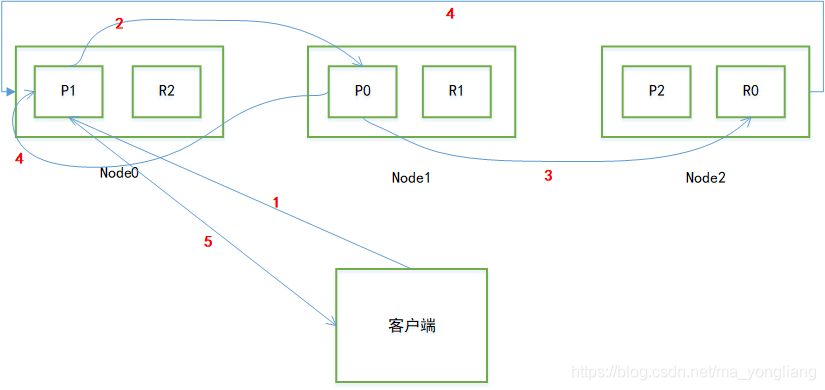
ES增删改的处理流程:增删该的请求一定作用在主分片上。
假如我们es集群有3个node,每个node上一个主分片一个复制分片。
1. 客户端发起一个PUT请求,假如该请求被发送到第一个node节点,那么该节点将成为协调节点(coordinating node),如图P1所在的节点就是协调节点。他将根据该请求的路由信息计算,该document将被存储到哪个分片;
2. 通过计算发现该document被存储到p0分片,那么就将请求转发到node1节点;
3. P0根据请求信息创建document,和相应的索引信息,创建完毕后将信息同步到自己的副本节点R0上;
4. P0和R0将通知我们的协调节点,任务完成情况;
5. 协调节点响应客户端最终的处理结果。
-
(3)查询原理
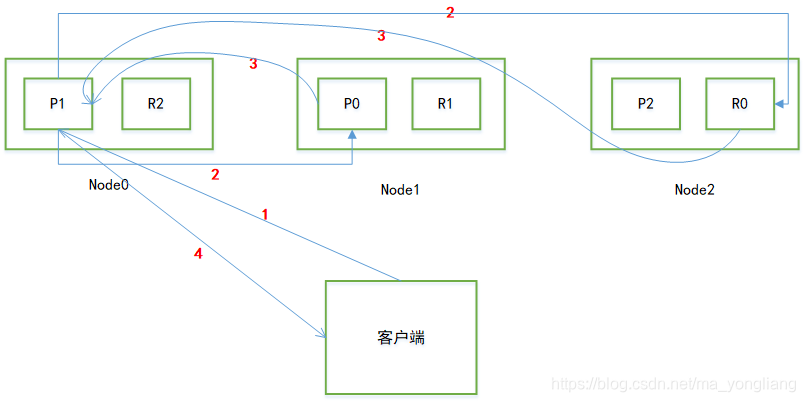
1. 客户端发送读器请求到协调节点(coordinate node);
2. 协调节点(coordinate node)根据请求信息对document进行路由计算,将请求转发到对应的node0,node1 或者node2。 此时会使用round-robin随机轮询算法,在primary shard以及其所有replica(副本)中随机选择一个,让读请求负载均衡;
3. 相应接收到请求的节点(node1或者node2)将处理结果返回给协调节点(coordinate node);
4. 协调节点将最终的结果反馈给客户端。
注意:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时请求如果作用到replica shard上可能会导致无法读取到document信息。但是document完成索引建立之后,primary shard和replica shard就都有了。
-
4.2 集群扩容问题
(1)性能扩容
primary shard在创建的时候就已经固定了,不可以再修改,但是可以通过增加replica shard的方式来增大吞吐量,达到性能扩容。
(2)容量扩容
容量扩容分为垂直扩容和水平扩容。垂直扩容即更换集群中的服务器,换成性能更好的节点,比如将一台存储量为1T的节点换为存储量为5T的节点;水平扩容就是在集群中新增服务器。内存扩容的极限就是每个primary shard部署单台服务器,所以在创建的时候要注意primary shard的数量。
-
4.3 集群容错机制
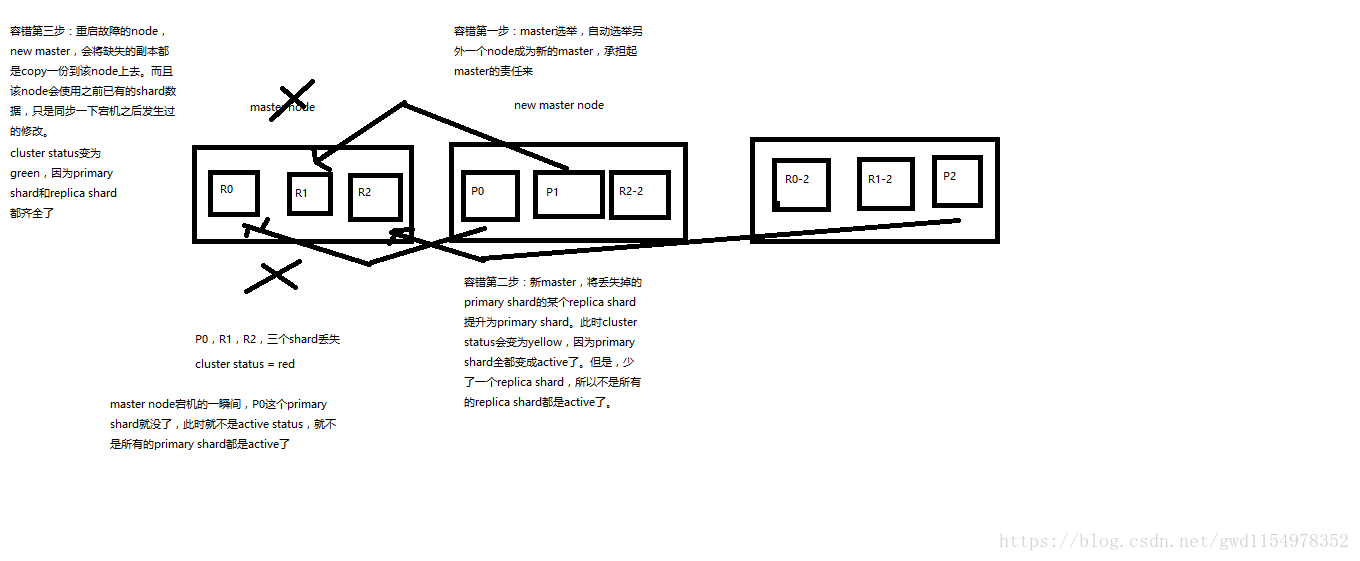
1. master node宕机后,会自动重新选举master,此时为red;
2. replica容错:新master是将replica提升为primary shard,此时为yellow(因为replica被升级为primary了,此时replica并不齐全);
3. 重启宕机node,master copy replica到该node,但是该node使用原有的shard并同步宕机后的修改(即仅同步宕机后丢失的数据),此时为green。
-
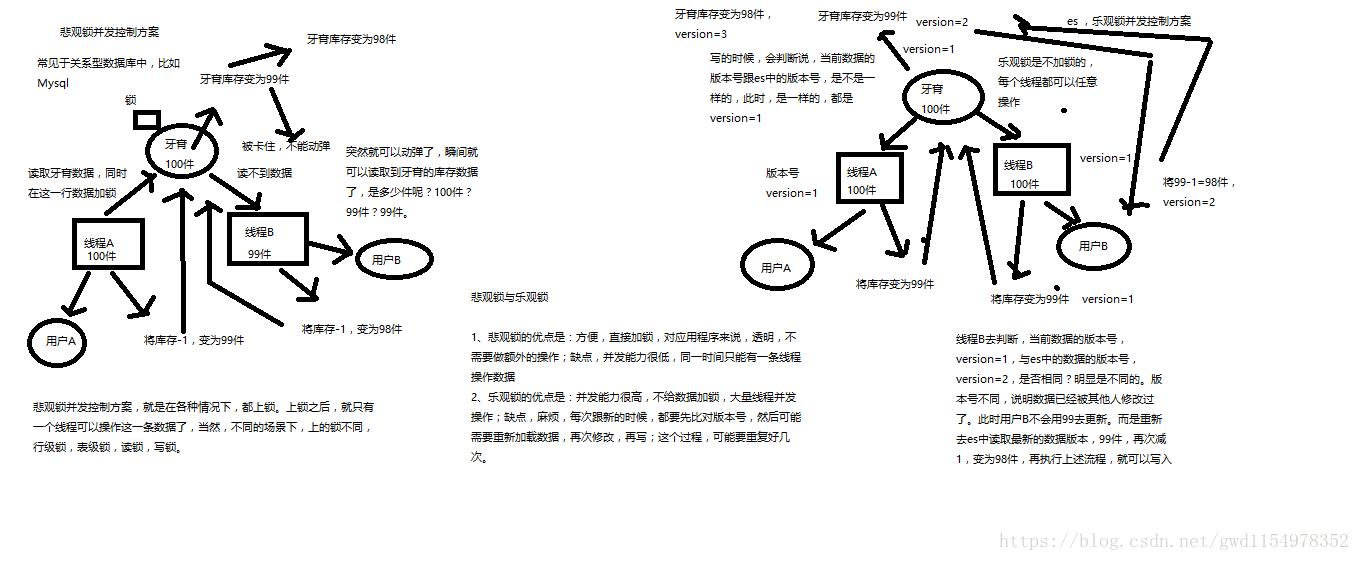
4.4 version之悲观锁与乐观锁
(1)悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,上锁之后就只有一个线程可以操作这条数据了,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
优点:方便,直接加锁,对应用程序来说比较透明,不需要额外的操作。
缺点:并发能力低,同一时间只能有一条线程操作数据。
(2)乐观锁
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
在ES中乐观锁主要通过版本号等数据来进行判定该数据是否有被修改过,如果发现版本version与自己不相同,那就说明数据是已经被修改过的,那么它会重新去es中读取最新的数据版本,然后再进行数据上的操作。
优点:并发能力高,不给数据加锁,可大量线程并发操作。
缺点:麻烦,每次更新的时候,都要先比对版本号,然后可能需要重新加载数据,再次修改,再次更改……这个过程可能需要重复多次。
-
4.5 倒排索引
-
4.6 mapping详解

















 5489
5489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









