






Redis的单线程主指网络IO和键值对读写是一个线程来完成的
备份/数据恢复
持久化混合备份:重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件 然后覆盖旧的
备份策略:
- crontab定时调度脚本,每小时copy一份rdb或aof 到指定目录,保留48h备份,将太旧的删除
- 每天保留当日数据,可保留一个月
- 每天将当前机器上的备份复制到其他机器上,以防机器损坏
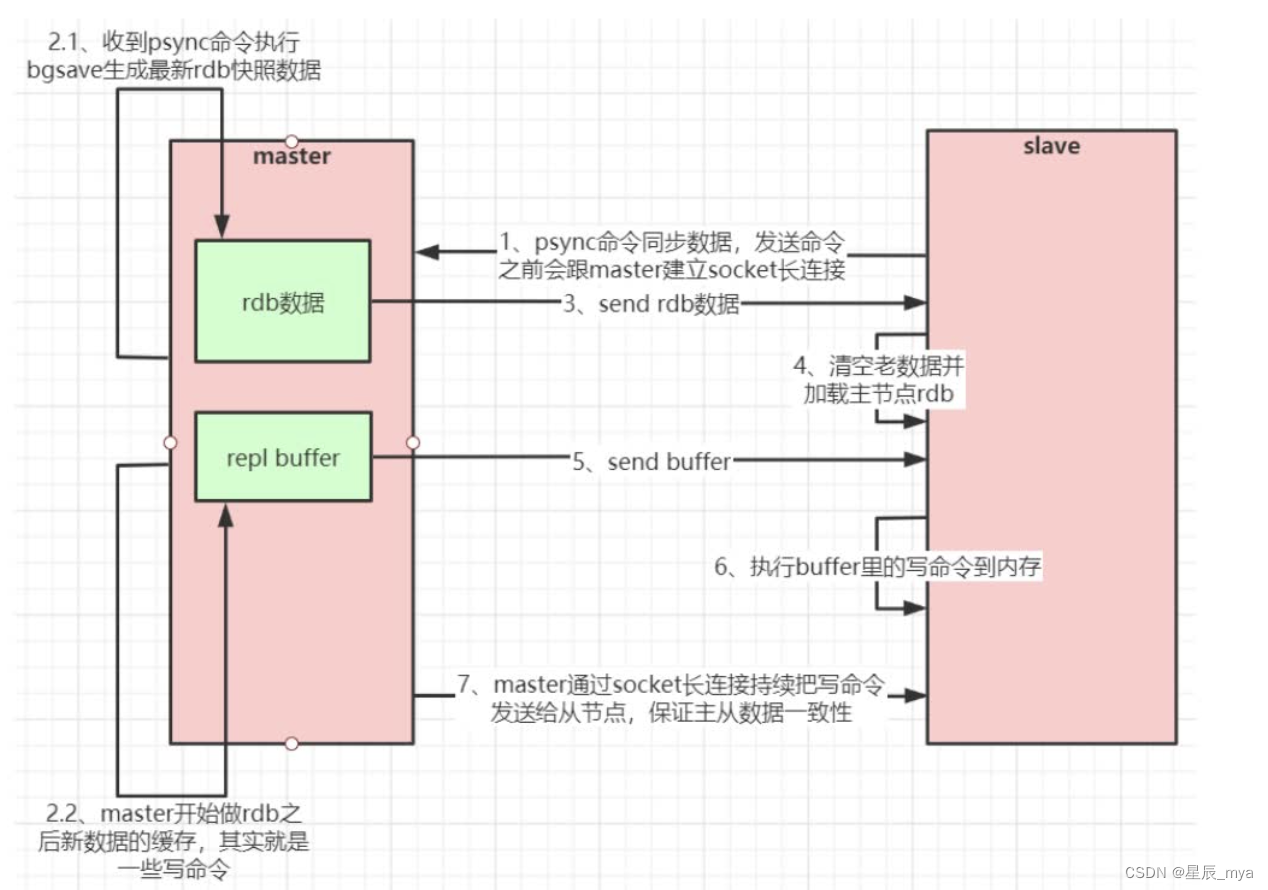
主从全量复制
数据结构
动态字符串SDS
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /*已保存的字节数 不含结束标识 header*/
uint8_t alloc; /*申请总的字节数,不含结束标识 header*/
unsigned char flags;/*不同sds头类型,控制sds头大小 header*/
char buf[];
}len:4 alloc:4 flags:1 数组 \0
sds可追加:动态扩容 减少内存分配次数 二进制安全
如新字符串<1m 新空间为扩展后字符串长度的两倍+1
如新字符串>1m 新空间为扩展后字符串长度+1m+1 内存预分配
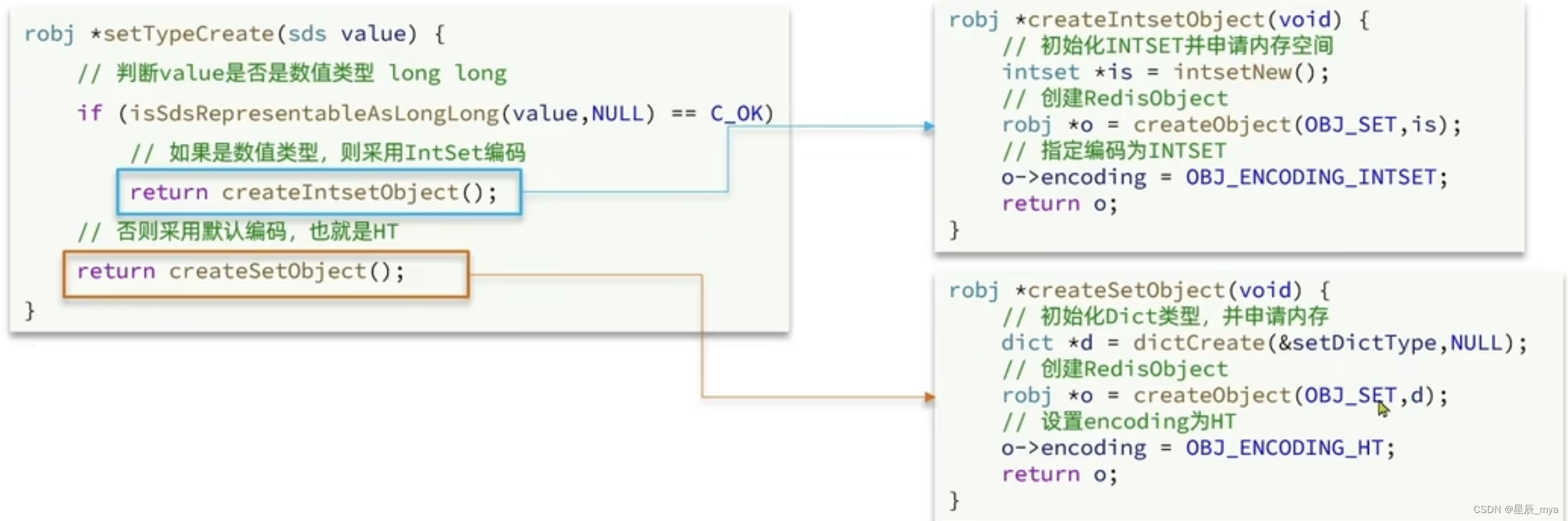
IntSet
set集合实现方式,整数数组 长度可变 有序(升序)
typedef struct intset {
uint32_t encoding;/*编码方式 支持存放16 32 64位*/
uint32_t length; /*元素个数*/
int8_t contents[];/*整数数组 保存集合数据*/
}encoding:iniset_enc_int16(四字节) length:3(四字节) contents[] (地址)
intset_enc_int32 32位 4字节 ; intset_enc_int16 16位2字节
自动升级编码encoding
升级:编码升级 倒序依次将数组元素拷贝到扩容后到正确位置(所占字节数)
元素唯一 支持类型升级 节省内存空间 二分查找元素
dict:哈希表 哈希节点 字典组成
向dict添加键值对,先key计算hash值h,利用h & sizemask计算元素存储到数组中索引位置
与运算:同1则1 否则0 真真则真and
//哈希表
typedef struct dictht {
dictEntry **table ;//数组 指向entry到指针
unsigned long size;//哈希表大小 2的n次方
unsigned long sizemask;//哈希表大小的掩码 size-1
unsigned long used;//entry个数
}dictnt;
//节点
typedef struct dictEntry{
void *key;//键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
}v;//值
//下一个entry指针
struct dictEntry *next;
}dictEntry;
字典dict
typedef struct dict {
dictType *type;//类型,内置不同的hash函数
void *privdata;//私有数据,特殊hash运算时用
dictht ht[2];//两个哈希表,当前数据 另个一般为空 rehash使用
long rehashidx;//rehash进度 -1未进行
int16_t pauserehash;//rehash是否暂停 1暂停0继续
}元素较多 哈希冲突多 链表长 查询效率降低
扩缩
扩容
负载因子 loadFactor >= 1 未执行bgsave/bgrewriteaof等
或者loadFactor > 5
收缩
删除,loadFactor<0.1

ziplist 节省内存 双端链表 连续内存 O(1)
通过记录上一节点本节点长度来寻址,内存占用低
![]()
zlbytes(总字节数) zltail(尾偏移量|尾节点距压缩列表起始地址)zllen(节点个数65534)entry(头节点)……entry(尾节点)zlend(oxFF标记末端)
entry
previous_entry_length前节点长度
encoding编码属性记录数据类型及长度
contents保存节点的数据
优化:限制ziplist长度 entry大小 多个ziplist分片存储数据
quicklist 3.2 双端链表 节点上ziplist 压缩
list-max-ziplist-size
正数限制entry个数
-1内存不超4k -2不超8k默认 -3不超16k -4不超32k
list-compress-depth
0首尾不压缩 1首尾各1节点不压缩中间压 2首尾各2节点不压 其他压

skiplist 链表 升序排列存储
一个节点多个指针 跨度不同 多层指针

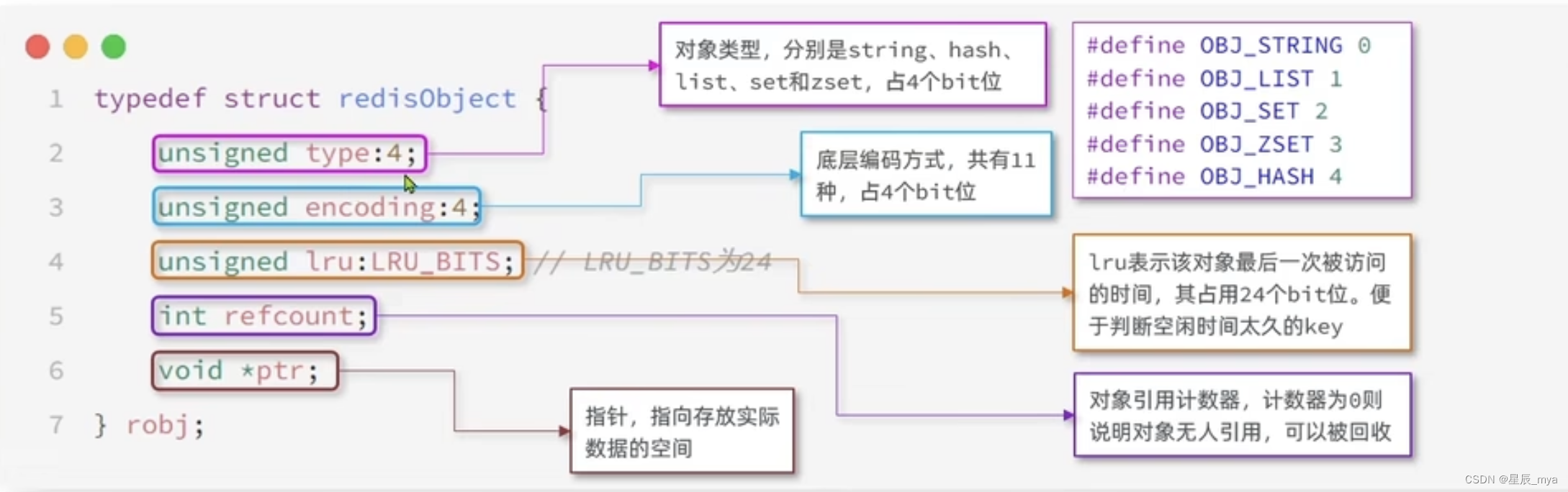
redisObject类型
底层编码
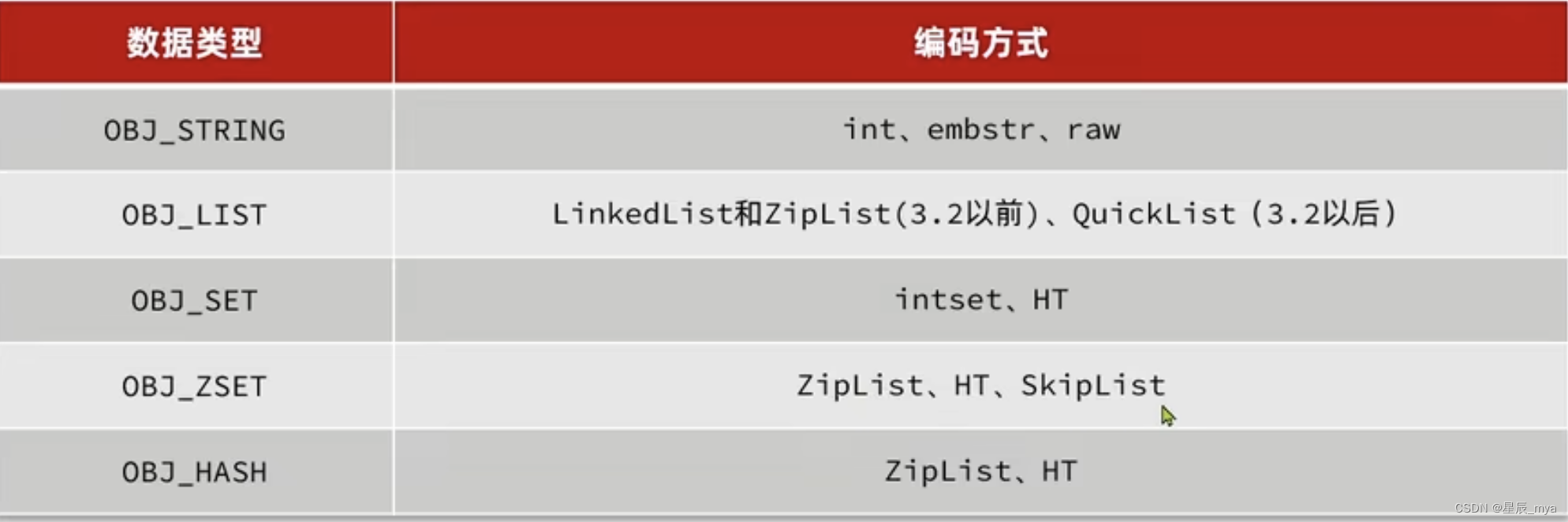
字符串:int embstr raw
sds 存储上限512m
长度小于44 embstr header与sds连续 空间 一次内存分配 64k不需要分片 效率高
list 首尾操作
ziplist压缩 双端访问 记录地址大小推算出 ,存储上限低
linkedlist 普通链表 双端访问 内存占用高 碎片多
quicklist:linkedlist+ziplist 双端访问 内存占用低 3.2
set 单列 无序 唯一 交并差集
hash(dict) key存元素value为null;
intset编码,省内存 数据都是整数 量不超过set-max-inset-entries
zset 可排序 score member
hashtable +skiplist 排序 :内存占用大
ziplist数据量不多:元素<zset_max_ziplist_entries 128,元素<zset_max_ziplist_value 64
hash 键值存储 键唯一
ziplist 节省内存 相邻的entry分别存储field和value
hash:数据量大 num>hash_max_ziplist_entries512 & entry>hash_max_ziplist_value64
网络模型
用户空间 内核空间
进程寻址空间
用户空间:受限的命令ring3,不直接调用系统资源 通过内核接口访问
内核空间:调用一切资源 特权命令
阻塞io与非阻塞
阻塞io:阻塞等待数据
非阻塞io:反复调用recvfrom,二阶段阻塞等待 处理数据返回成功标识
io多路复用:
文件描述符file descriptor,从0开始递增无符号整数,关联linux文件
io多路复用:单个线程同时监听多个fd,在某个fd可读 可写时得到通知 利用cpu资源
通知方式:
select/poll:会通知用户进程fd就绪,但是不确定哪个fd,一次询问谁准备好了

select 每次都需要将fd_set用户到内核,结束在拷贝回用户
不知道具体哪个fd就绪,监听的fd数量<1024
poll:

epoll:通知用户进程谁准备就绪了
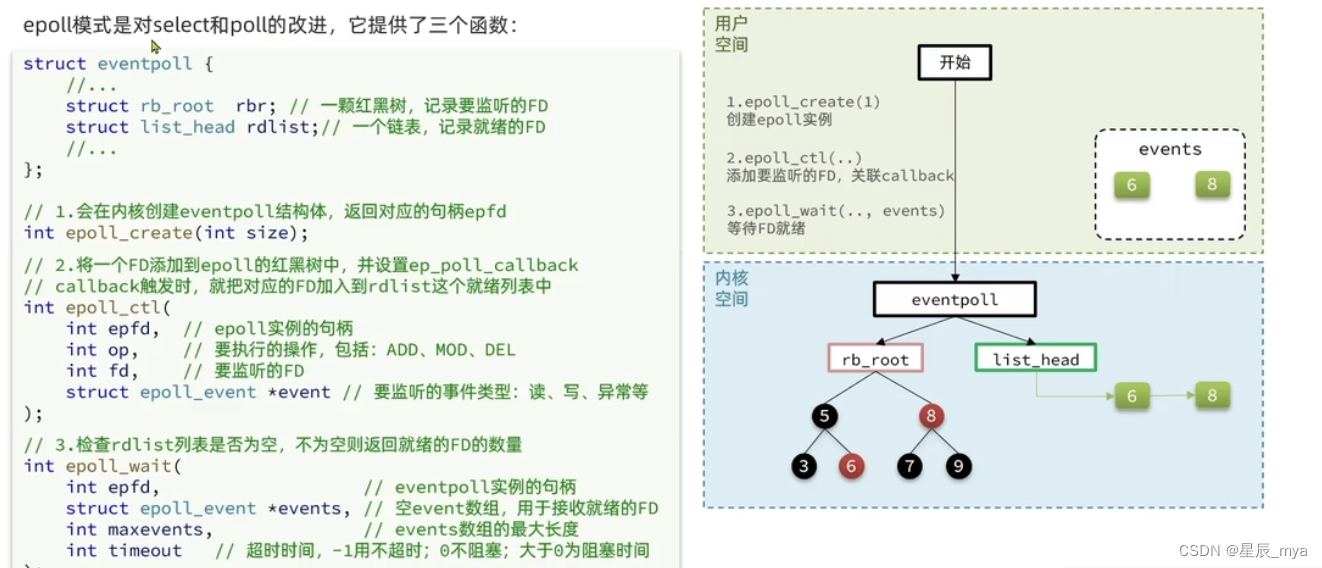
事件通知事件
fd有数据 epoll_wait 可得到通知 但是事件通知的模式:
levelTriggered:有数据可读 重复通知多次 直到数据处理完成 epoll默认模式
edgetriggered:有数据可读,只通知一次
网络模型
命令处理 单线程
4.0引入多线程异步处理一些耗时较长的任务,异步删除命令unlink
6.0核心网络模型引入多线程 多核CPU利用率
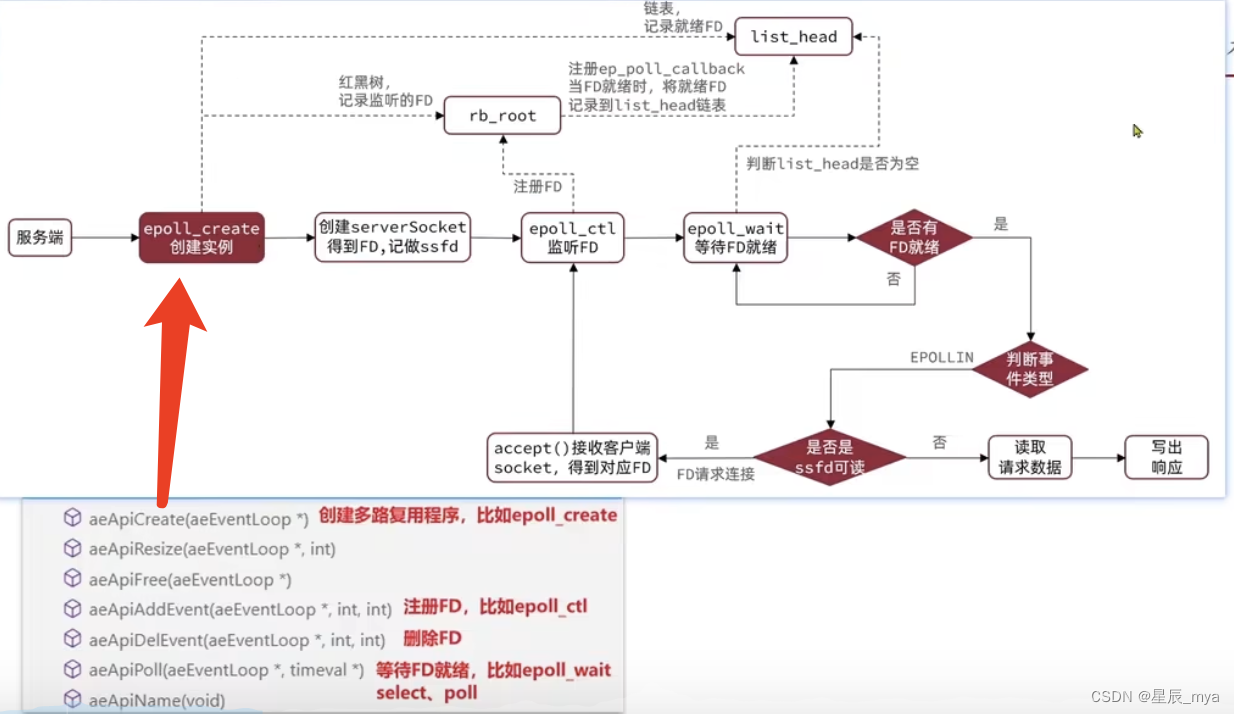
redis网络模型
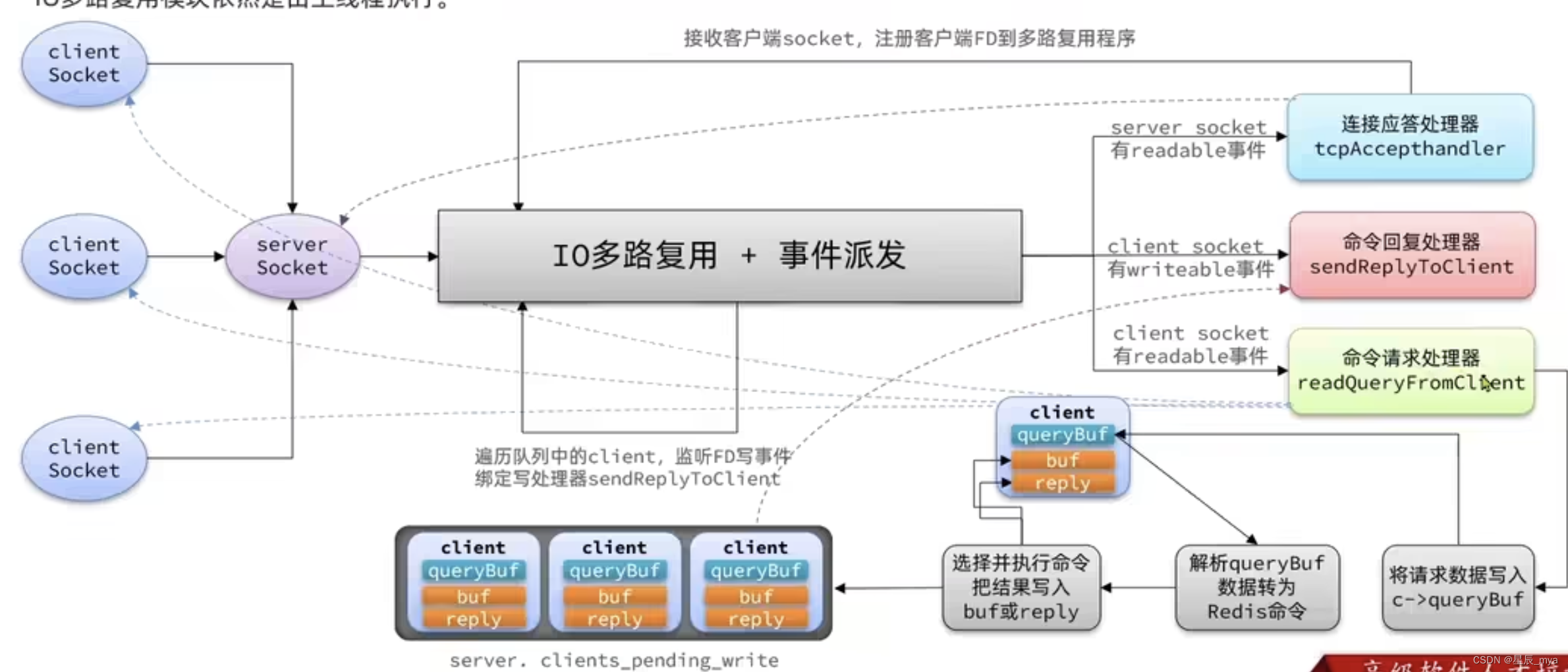 通信规范
通信规范
resp:CS架构的软件 通信一般分两步(不含pipeline和pubsub)
client 向 server 发送一条命令
服务端解析并执行命令,返回响应给客户端
数据类型:
单行字符串 首字节+ 后跟单行字符串 crlf结尾(\r\n)
错误errors,首字符- crlf结尾
数值:首字节: + 数字格式的字符串 crlf结尾
多行字符串:首字节$ 最大支持512m,=0空字符串$0\r\n\r\n. =-1不存在$-1\r\n
数组 首字节* 后面跟上 数组元素个数 再跟上元素
key过期
两个dict记录key-value和key-ttl
过期策略:
惰性删除:每次查找先判断是否过期
周期删除:定时任务 周期性抽样部分过期key 删除
skiw:默认1s10次,周期100ms,遍历db多bucket 取20key是否过期 一删除,执行清理耗时不超过一次执行周期短25%
fast:两次间隔不低于2ms,清理耗时不超过1ms,逐个遍历db多bucket 取20key是否过期,
淘汰策略
processCommand尝试做内存淘汰
noeviction:不淘汰 内存满不写数据
volatile-ttl设置了ttl的key,比较key的剩余ttl值越小越先被淘汰
allkeys-random全体key 随机淘汰 db->dict
allkeys-lru lru算法 最少最近使用 当前时间减去最后一次访问时间 大则先淘汰
volatile-lru:设置了ttl的key lru淘汰
allkeys-lfu:全体key 基于lfu算法淘汰
volatile-lfu设置了ttl的可以 基于lfi算法进行淘汰
lru算法 最少最近使用 当前时间减去最后一次访问时间 大则先淘汰
lfu最少频率使用,统计key访问频率,值越小淘汰优先级越高
集群
slave发现master=fail状态,failover 期待成为新的master
将自己记录的集群currentEpoch+1,广播filover_auth_request
master收到判断合法性,发送failover_auth_ack
slave收到超过半数master,自己变成新master,pong广播给其他集群节点
DELAY=500ms+random(0~500ms)+SLAVE_RANK*1000ms 发送failover_auth_request消息
slave_rank : slave从mastr复制的数据总量的rank,越小复制的数据越新
脑裂问题
分布式锁
lua脚本:
tryLockInnerAsync
减少网络开销,原子操作,代替事务操作
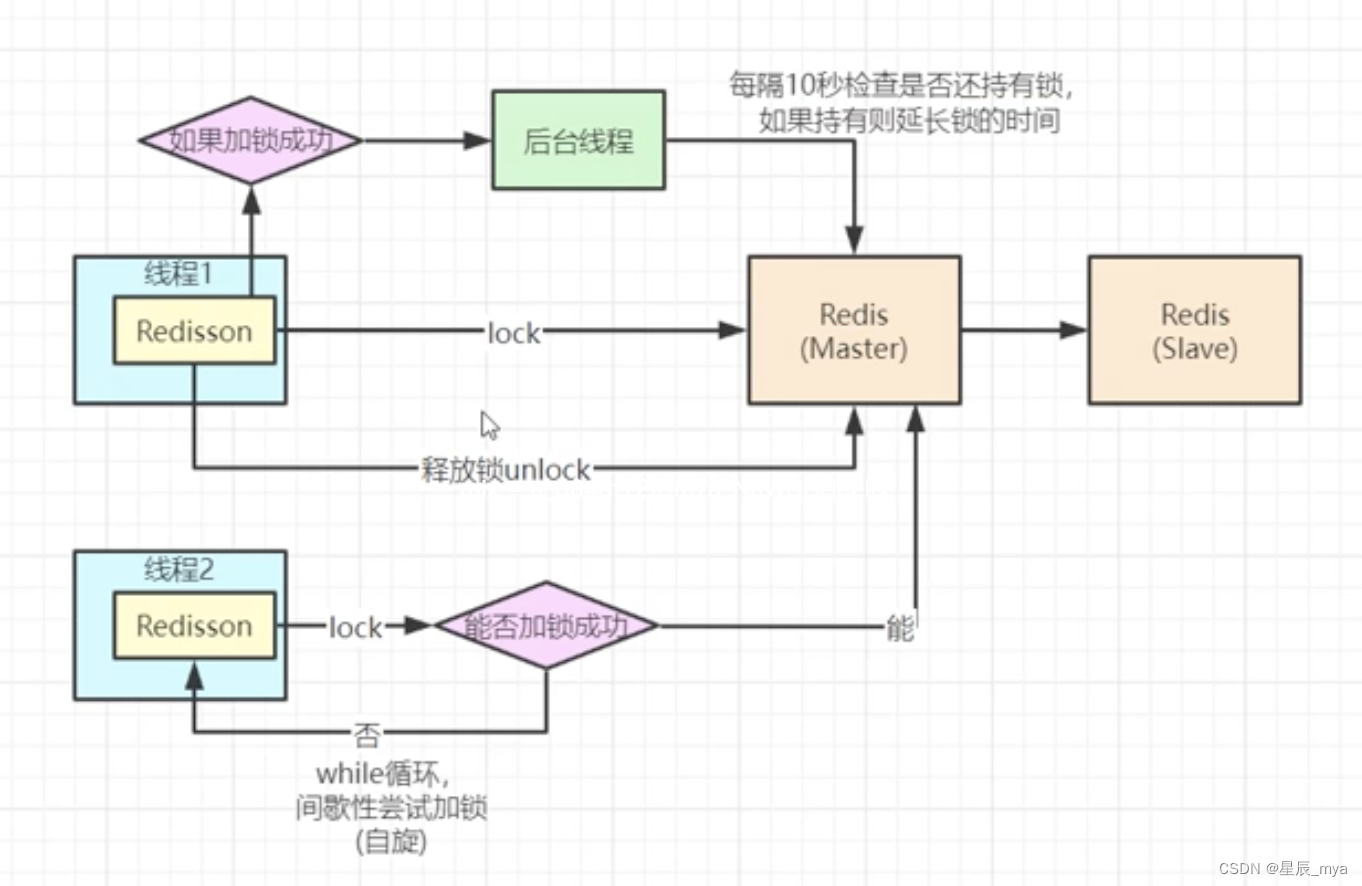
加锁自选:future 方法内循环延迟调用自身
监听queue,subscribe onMessage(redissonLockEntry)
tryLockInnerAsync



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









