




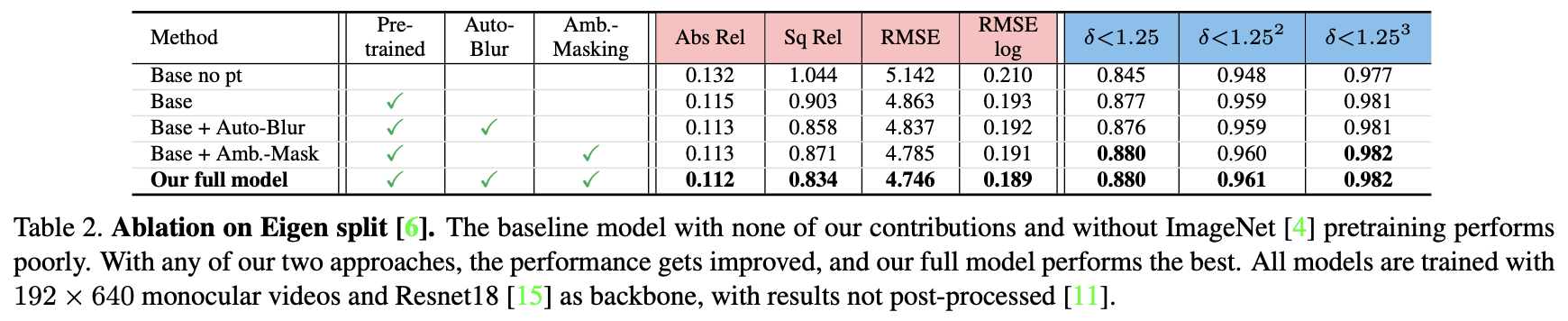
 本文探讨了自监督深度估计算法中的光度重构误差问题,尤其是在高频区域的不确定性。为解决这一问题,文章提出了Ambiguity-Masking和Auto-Blur策略。Ambiguity-Masking通过梯度权重因子减少高频区域的歧义,而Auto-Blur则使用低通滤波器平滑边缘,改善损失函数的反馈。实验表明这两种方法能有效提升深度估计的准确性。
本文探讨了自监督深度估计算法中的光度重构误差问题,尤其是在高频区域的不确定性。为解决这一问题,文章提出了Ambiguity-Masking和Auto-Blur策略。Ambiguity-Masking通过梯度权重因子减少高频区域的歧义,而Auto-Blur则使用低通滤波器平滑边缘,改善损失函数的反馈。实验表明这两种方法能有效提升深度估计的准确性。
参考代码:freq-aware-depth
1. 概述
介绍:在自监督深度估计算法中采用光度重构误差作为约束函数,但是这个约束函数却是存在不足的,也就是损失的大小在某些区域不能真实反应深度预测的误差大小,如图像中的高频区域,从而给整体算法Loss带来歧义(深度估计误差于光度重构误差的比例不正相关)。对于这个问题文章提出了两种策略去缓解高频区域处不确定性带来的歧义:1)Ambiguity-Masking:通过感知图像中的高频信息分布(图像梯度变化),给光度重构误差增加一个权重因子,从而缓解高频信息处Loss的不确定性。2)Auto-Blur:在图像梯度的指引下设计一个低通的高斯滤波器,用于平滑图像中的边缘区域,使得损失更能真实反馈重构的质量。
在自监督深度估计中,对图像中物体的边缘细节放大,并与对应的Loss分布可视化得到下图:

在上图(b)中可以看到loss倾向于在边缘区域产生更大的损失,这也表达了边缘处的损失并不能很好反应实际深度预测的质量。将图像中目标对应边缘进行放大得到图(c),可以看到由于分辨率的问题,其在边缘位置处的一些像素并不是能很准确进行区域划分,这也就导致了对应高频区域上loss存在歧义。这篇文章也对此提出了两点对应的策略用于缓解该问题。
2. 方法设计
2.1 整体pipeline
文章的整体pipeline见下图所示:

从上图可以看出文章在原本自监督深度估计方法的基础上,增加Ambiguity-Masking用于缓解高频区域loss歧义带来的影响,增加Auto-Blur缓解图像高频区域带来的损失跳变和歧义。
这里令网络
t
t
t时刻估计出的深度为
D
t
D_t
Dt,到时刻
t
+
n
t+n
t+n的位姿关系为
T
t
→
t
+
n
T_{t\rightarrow t+n}
Tt→t+n,对应的相机内参为
K
K
K,则图像的冲投影采样描述为:
⊗
=
p
r
o
j
(
D
t
,
T
t
→
t
+
n
,
K
)
\otimes=proj(D_t,T_{t\rightarrow t+n},K)
⊗=proj(Dt,Tt→t+n,K)
对于图像在X和Y方向上梯度描述为:
∇
u
±
(
i
,
j
)
=
I
(
i
,
j
)
−
I
(
i
±
1
,
j
)
\nabla_{u\pm}(i,j)=I(i,j)-I(i\pm1,j)
∇u±(i,j)=I(i,j)−I(i±1,j)
∇
v
±
(
i
,
j
)
=
I
(
i
,
j
)
−
I
(
i
,
j
±
1
)
\nabla_{v\pm}(i,j)=I(i,j)-I(i,j\pm1)
∇v±(i,j)=I(i,j)−I(i,j±1)
在Auto_Blur中使用两个方向的梯度:
∇
±
(
i
,
j
)
=
∣
∣
∇
u
±
(
i
,
j
)
,
∇
v
±
(
i
,
j
)
∣
∣
2
\nabla_{\pm}(i,j)=||\nabla_{u\pm}(i,j),\nabla_{v\pm}(i,j)||_2
∇±(i,j)=∣∣∇u±(i,j),∇v±(i,j)∣∣2
在Ambiguity-Masking中使用合成梯度:
∇
(
i
,
j
)
=
∣
∣
∇
u
+
(
i
,
j
)
−
∇
u
−
(
i
,
j
)
2
,
∇
v
+
(
i
,
j
)
−
∇
v
−
(
i
,
j
)
2
∣
∣
2
\nabla(i,j)=||\frac{\nabla_{u+}(i,j)-\nabla_{u-}(i,j)}{2},\frac{\nabla_{v+}(i,j)-\nabla_{v-}(i,j)}{2}||_2
∇(i,j)=∣∣2∇u+(i,j)−∇u−(i,j),2∇v+(i,j)−∇v−(i,j)∣∣2
2.2 Ambiguity-Masking
记使用的梯度为
F
t
\mathcal{F}_t
Ft,使用二值掩膜
u
u
u表示在水平和垂直方向上梯度相反的高频区域:
u
=
[
∇
u
+
⋅
∇
u
−
<
0
∨
∇
v
+
⋅
∇
v
−
<
0
]
,
[
⋅
]
i
s
I
v
e
r
s
o
n
b
r
a
c
k
e
t
u=[\nabla_{u+}\cdot\nabla_{u-}\lt0\ \vee\ \nabla_{v+}\cdot\nabla_{v-}\lt0], [\cdot] is\ Iverson\ bracket
u=[∇u+⋅∇u−<0 ∨ ∇v+⋅∇v−<0],[⋅]is Iverson bracket
之后得到在时刻
t
t
t下的不确定性图:
A
t
=
u
⊙
F
t
\mathcal{A}_t=u\odot\mathcal{F}_t
At=u⊙Ft
对于在时刻
t
+
n
t+n
t+n重构得到的图像其不确性图经过采样之后描述为:
A
ˉ
t
+
n
=
⟨
A
t
+
n
,
⊗
t
+
n
⟩
\bar{\mathcal{A}}_{t+n}=\langle\mathcal{A}_{t+n},\otimes_{t+n}\rangle
Aˉt+n=⟨At+n,⊗t+n⟩
最后将上述两者取最大值得到最后的不确定性图:
A
t
m
a
x
=
m
a
x
(
A
ˉ
t
+
n
,
A
t
)
\mathcal{A}^{max}_t=max(\bar{\mathcal{A}}_{t+n},\mathcal{A}_t)
Atmax=max(Aˉt+n,At)
之后得到于光度重构误差加权的权重二值mask:
A
t
p
e
=
[
A
t
m
a
x
<
δ
]
\mathcal{A}^{pe}_t=[\mathcal{A}^{max}_t\lt\delta]
Atpe=[Atmax<δ]
其中,
δ
=
0.3
\delta=0.3
δ=0.3。同时可以使用下面指数的形式计算权重:
A
t
p
e
=
e
−
γ
A
t
m
a
x
,
γ
=
3
\mathcal{A}^{pe}_t=e^{-\gamma\mathcal{A}^{max}_t},\ \gamma=3
Atpe=e−γAtmax, γ=3
2.3 Auto_Blur
记使用的梯度也为
F
t
\mathcal{F}_t
Ft,则定义高频掩膜(阈值
λ
=
0.2
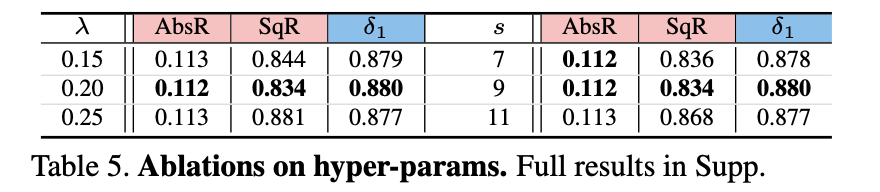
\lambda=0.2
λ=0.2):
M
i
s
−
h
f
−
p
i
x
e
l
(
p
)
=
[
F
t
(
p
)
>
λ
]
\mathcal{M}_{is-hf-pixel}(p)=[\mathcal{F}_t(p)\gt\lambda]
Mis−hf−pixel(p)=[Ft(p)>λ]
依据上述高频掩膜定义,在大小为
s
=
9
s=9
s=9的区域上确定高频区域(阈值为
η
=
60
\eta=60
η=60):
M
i
s
−
h
f
−
p
i
x
e
l
a
v
g
(
p
)
=
1
s
∗
s
∑
q
∈
N
s
∗
s
(
p
)
M
i
s
−
h
f
−
p
i
x
e
l
(
q
)
\mathcal{M}_{is-hf-pixel}^{avg}(p)=\frac{1}{s*s}\sum_{q\in N_{s*s}(p)}\mathcal{M}_{is-hf-pixel}(q)
Mis−hf−pixelavg(p)=s∗s1q∈Ns∗s(p)∑Mis−hf−pixel(q)
M
i
s
−
h
f
−
a
r
e
a
(
p
)
=
[
M
i
s
−
h
f
−
p
i
x
e
l
a
v
g
(
p
)
>
η
%
]
\mathcal{M}_{is-hf-area}(p)=[\mathcal{M}_{is-hf-pixel}^{avg}(p)\gt\eta\%]
Mis−hf−area(p)=[Mis−hf−pixelavg(p)>η%]
对于一张图像的高斯模糊,其数学表达定义为:
I
t
g
b
=
∑
q
∈
N
(
p
)
w
g
b
(
q
)
I
t
(
q
)
I_t^{gb}=\sum_{q\in N(p)}w^{gb}(q)I_t(q)
Itgb=q∈N(p)∑wgb(q)It(q)
w
g
b
(
q
)
=
1
2
π
σ
e
−
Δ
x
2
+
Δ
y
2
2
σ
2
w^{gb}(q)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{\Delta_x^2+\Delta_y^2}{2\sigma^2}}
wgb(q)=2πσ1e−2σ2Δx2+Δy2
则添加图像高频信息因子,得到新的滤波函数:
I
t
a
b
(
p
)
=
w
b
l
u
r
(
p
)
I
t
g
b
(
p
)
+
(
1
−
w
b
l
u
r
(
p
)
)
I
t
(
p
)
I_t^{ab}(p)=w_{blur}(p)I_t^{gb}(p)+(1-w_{blur}(p))I_t(p)
Itab(p)=wblur(p)Itgb(p)+(1−wblur(p))It(p)
其中的加权因子为:
w
b
l
u
r
(
p
)
=
M
i
s
−
h
f
−
p
i
x
e
l
a
v
g
(
p
)
M
i
s
−
h
f
−
a
r
e
a
(
p
)
w_{blur}(p)=\mathcal{M}_{is-hf-pixel}^{avg}(p)\mathcal{M}_{is-hf-area}(p)
wblur(p)=Mis−hf−pixelavg(p)Mis−hf−area(p)
添加Auto-Blur之后深度误差曲线趋于于全监督曲线接近,达到对高频噪声的抑制作用,见下图所示:
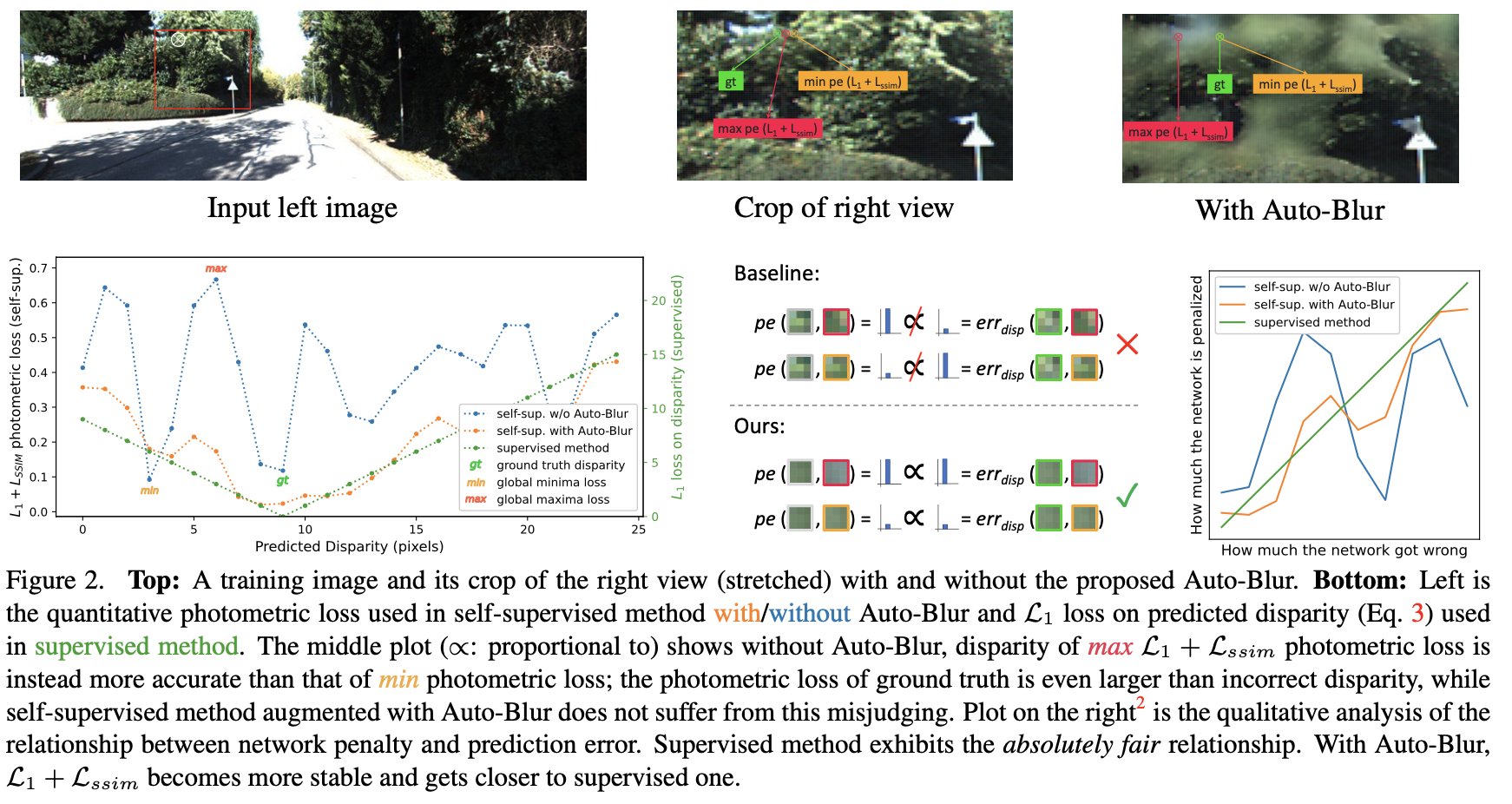
2.4 消融实验
上述两种高频信息处理策略对性能带来的影响:
其它一些超参数带来的影响:
3. 实验结果
在现有方法上带来的性能提升:
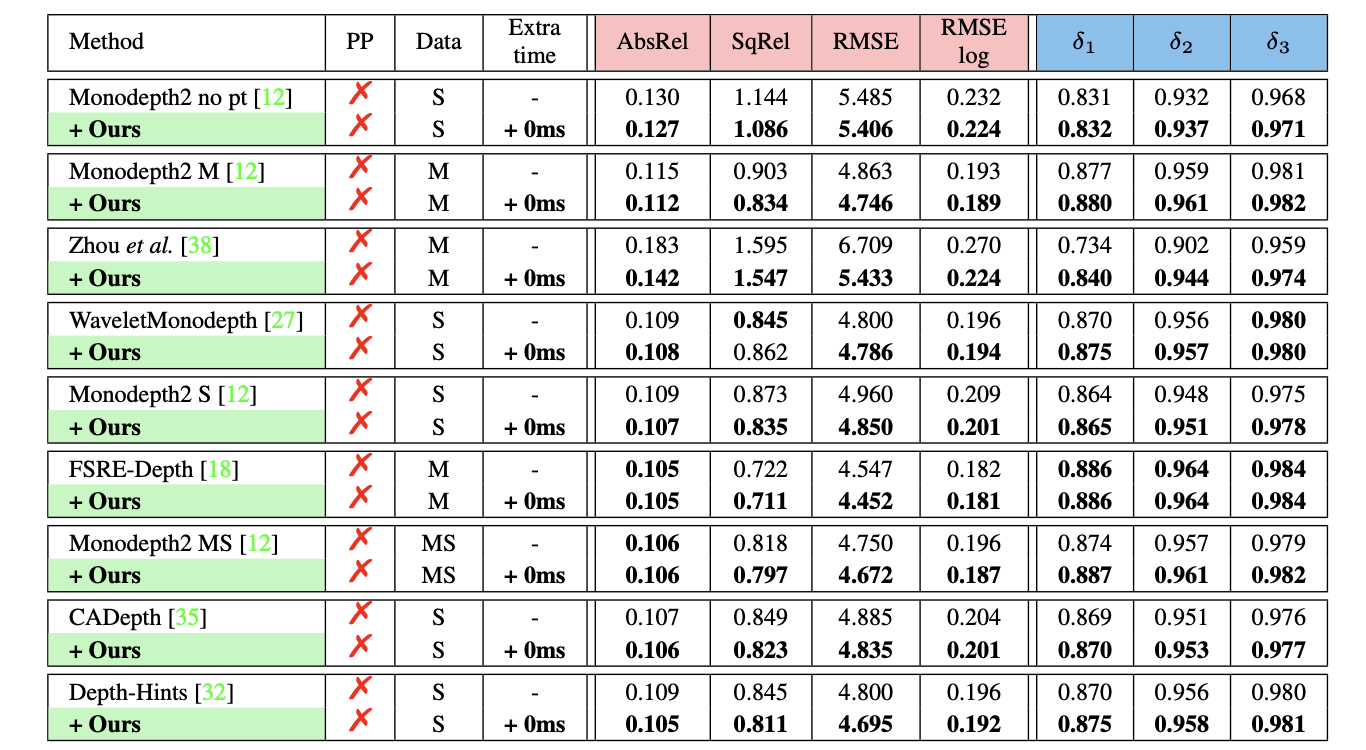
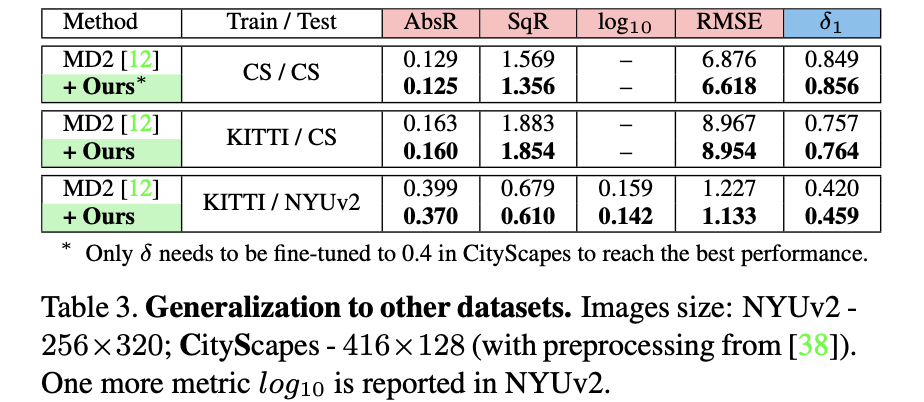
不同数据集下均表明文章方法的有效性:


















 2790
2790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









