




 本文深入解读《Generalized Focal Loss V1》论文,探讨如何将目标检测边界框回归问题转化为概率分布,通过QFL、DFL、GFL改进定位准确性,实现端到端的联合学习,提升模糊和歧义场景下的检测效果。
本文深入解读《Generalized Focal Loss V1》论文,探讨如何将目标检测边界框回归问题转化为概率分布,通过QFL、DFL、GFL改进定位准确性,实现端到端的联合学习,提升模糊和歧义场景下的检测效果。
参考代码:GFocal
这篇文章会探讨将目标检测中边界框的回归问题转换为概率分布的问题,因而需要从传统的边界框范数与IoU回归思想转换到边界框的概率分布上来。对此,对这方面内容不是很理解的朋友可以参考下面这篇文章的内容,从而对加深这篇文章提出GFocal优化方法的理解:
REF:一文了解目标检测边界框概率分布
同时,这篇文章的作者也有对这篇文章进行了说明,详见:大白话 Generalized Focal Loss
1. 概述
导读:让目标检测网络实现对检测质量的感知,是之前一些检测算法努力追求的目标。总结之前的工作,文章对于目标检测质量感知和边界框定位中存在的问题归纳为如下两点:
1)在之前的工作中有IoUNet使用IoU predictor,以及Focos使用Center-ness作为额外检测质量评估的参考维度之一。但是它们存在的共性都是在训练的时候单独进行训练,但是在测试的时候却联合起来,这并不是端到端的,因而其中难免会存在gap;
2)在之前的工作中普遍使用范数或是IoU作为监督度量,通过这些监督度量能够在大多数的场景下取得不错的结果,但是一些模糊或是存在歧义的场景下就会存在问题,导致定位不准确;
对此,文章的方法对检测质量感知的改进是通过将目标的类别与IoU预测结合起来作为检测质量评价,并带入网络进行联合学习。对于检测定位的过程中存在歧义的问题通过引入4个回归变量的概率分布进行表示,从而提升对于这些情况下的定位准确度,并且文章越策概率分布的时候并没有引入YOLO-Gaussian那样的强先验,从而增加了对于复杂概率分布建模的能力和灵活性。在优化的层面上文章引入Focal Loss中的优化策略,将原本离散的 { 0 , 1 } \{0,1\} {0,1}Focal loss问题转化为连续的 [ 0 , 1 ] [0,1] [0,1]通用优化,从而构建对于目标检测框质量(QFL:Quality Focal Loss)和定位概率分布 (DFL:Distribution Focal Loss)的有效优化。并在它俩的基础上提出了一种具有统一泛化特性的Focal Loss形式,也即是文章中提到的GFL(Generalized Focal Loss)。
文章对于算法改进的Insight主要是基于如下的两点观察:
- 1)在使用IoU预测的网络中,会存在IoU预测值很大但是其分类置信度比较低的情况,也就是下图中的图a,对分类置信度和IoU预测值进行分布可视化得到图b:

从上图中可以看出在IoU预测值和分类置信度组合并不是一个严格的线性关系的,因而就存在一些低质量的预测结果存在与最后的检测算法输出结果中(组合起来的置信度使用NMS不能将其排除)。而这样的架构使用的IoU和分类分支是相互独立训练的,只是在测试的时候将其组合起来,其流程见下图a图。对此,文章将两者组合起来,这样端到端完成训练(见图b),排除训练与预测的gap;

- 2)在下图中一些目标边界模糊和歧义的场景下检测的边界并不是很好确定,对此文章将边界的回归问题转换为边界概率分布的估计问题,从边界概率分布的角度实现更加准确的目标边界预测;

2. 方法设计
2.1 整体pipline
下图左图中展示了常见的目标检测回归机制,边界框定位使用的是Dirac分布,类别是用的是one-hot形式,并没有与边界框的质量进行联合感知。

而上图的右图是文章提出的方案,对于边界框定位使用任意概率分布的形式拟合,并且在类别预测中添加了对IoU的感知能力,从而构造soft one-hot标签。
2.2 Focal Loss属性的实现与统一
2.2.1 QFL
按照文章的内容这部分是在原有分类任务的基础上添加对于检测质量(IoU)的感知,对此需要将分类与IoU度量组合起来。从值域来讲分类是
{
0
,
1
}
\{0,1\}
{0,1}的离散变量,而IoU是
[
0
,
1
]
[0,1]
[0,1]的连续变量,则将其组合之后其值域也是
[
0
,
1
]
[0,1]
[0,1]的连续变量。参考原有Focal loss的范式:
F
L
(
p
)
=
−
(
1
−
p
t
)
γ
l
o
g
(
p
t
)
FL(p)=-(1-p_t)^\gamma log(p_t)
FL(p)=−(1−pt)γlog(pt)
其中,
p
t
=
{
p
,
if y=1
1
−
p
,
if y=0
p_t = \begin{cases} p, & \text{if y=1} \\ 1-p, & \text{if y=0} \end{cases}
pt={p,1−p,if y=1if y=0
那么要将IoU与分类组合起来,原有的softmax激活就适合了,需要将其置换为sigmoid激活函数,其输出标记为
σ
\sigma
σ,则将其按照Focal Loss的思想添加Focal属性便得到:
Q
F
L
(
σ
)
=
−
∣
y
−
σ
∣
β
(
(
1
−
y
)
l
o
g
(
1
−
σ
)
+
y
l
o
g
(
σ
)
)
QFL(\sigma)=-|y-\sigma|^\beta((1-y)log(1-\sigma)+ylog(\sigma))
QFL(σ)=−∣y−σ∣β((1−y)log(1−σ)+ylog(σ))
其中,
β
=
2
\beta=2
β=2是focal因子。
PS: 这里说到的组合是如下的形式:
y
i
=
{
I
o
U
(
b
p
r
e
d
,
b
g
t
)
,
if i=c
0
,
otherwise
y_i = \begin{cases} IoU(b_{pred},b_{gt}), & \text{if i=c} \\ 0, & \text{otherwise} \end{cases}
yi={IoU(bpred,bgt),0,if i=cotherwise
上面式子的含义是当样本为正样本的前提下,其原本分类的回归概率变为了与GT box类别一致(对应上式中的
i
=
c
i=c
i=c)预测框的IoU。
2.2.2 DFL
这里是将边界框的定位问题转换为概率分布问题,从传统的范数回归演化到这篇文章的任意概率分布回归,可以通过下图进行描述:
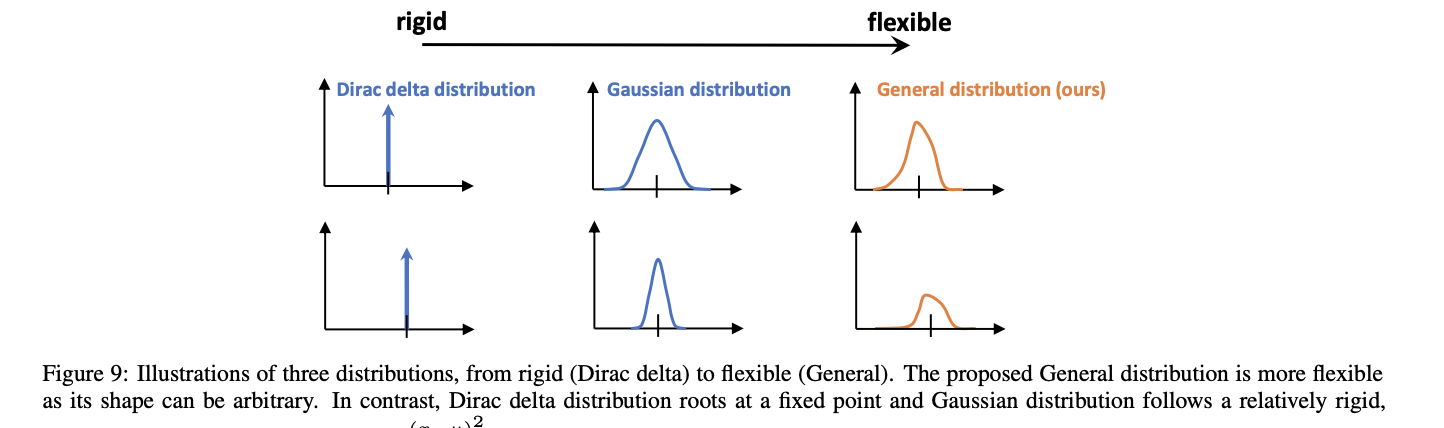
传统的范数回归可以看作是Dirac分布,其概率密度函数为
δ
(
x
−
y
)
\delta(x-y)
δ(x−y),那么将其转换为最后的预测结果输出是通过积分的形式:
y
^
=
∫
−
∞
∞
δ
(
x
−
y
)
x
d
x
\hat{y}=\int_{-\infty}^{\infty}\delta(x-y)x\ dx
y^=∫−∞∞δ(x−y)x dx
其中,
y
^
\hat{y}
y^是实际预测出来的边界框位置。原有的Dirac分布太过于单一,存在不灵活的问题,后期有引入Gaussian先验的形式,但是还是假设性太强。因而文章将其放宽约束为任意的分布,则对应的边界框位置也同样通过积分的形式得到:
y
^
=
∫
−
∞
∞
P
(
x
)
x
d
x
=
∫
y
0
y
n
P
(
x
)
x
d
x
\hat{y}=\int_{-\infty}^{\infty}P(x)x\ dx=\int_{y_0}^{y_n}P(x)x\ dx
y^=∫−∞∞P(x)x dx=∫y0ynP(x)x dx
上述提到的积分下界与上界指的是所有边界框回归的范围量,对此文章将边界框的回归范围量统计为下图c。因而这篇文章将积分的上下界描述为
[
y
0
,
y
n
]
=
{
y
0
,
y
1
…
,
y
n
}
[y_0,y_n]=\{y_0,y_1\dots,y_n\}
[y0,yn]={y0,y1…,yn},也就是划分成为了
n
+
1
n+1
n+1个bins。对于这些bins的预测是可以通过softmax(描述为
S
(
⋅
)
S(\cdot)
S(⋅))得到。然而这么多的bins会带来需求channel数量的提升,从而带来计算量开销的增大。
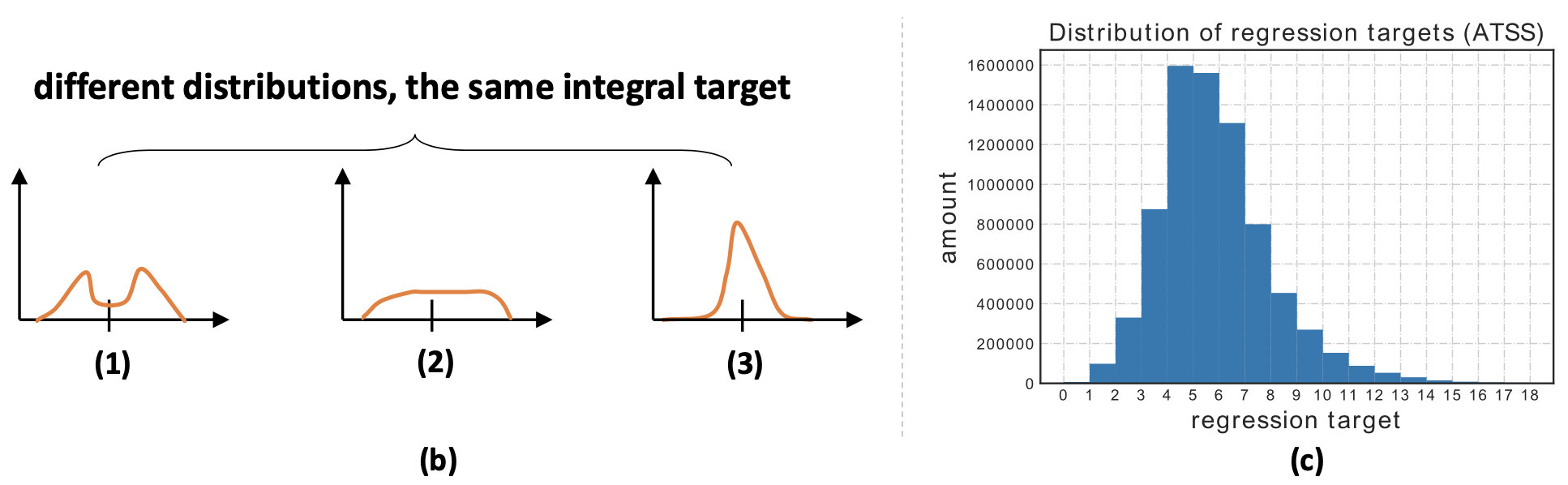
将分布空间划分为
n
+
1
n+1
n+1个bins之后,直接去回归它们的概率分布其实是很不高效的,因为存在相同积分值的概率分布太多了,如上图的b图所示。对此文章将所需求取的完整概率分布简化为相对真实坐标左右两个距离点
y
i
<
y
<
y
i
+
1
y_i\lt y\lt y_{i+1}
yi<y<yi+1的概率,则对应focal属性位置回归损失函数可以描述为
D
F
L
(
S
i
,
S
i
+
1
)
=
−
(
(
y
i
+
1
−
y
)
l
o
g
(
S
i
)
+
(
y
−
y
i
)
l
o
g
(
S
i
+
1
)
)
DFL(S_i,S_{i+1})=-((y_{i+1}-y)log(S_i)+(y-y_i)log(S_{i+1}))
DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))
其中,
S
i
S_i
Si代表的是回归距离为
y
i
y_i
yi的概率,则根据上述内容中对于最后回归值的估计,则该情况下最后回归之的计算可以描述为:
y
^
=
∑
j
=
0
n
P
(
y
j
)
y
j
=
S
i
y
i
+
S
i
+
1
y
i
+
1
\hat{y}=\sum_{j=0}^nP(y_j)y_j=S_iy_i+S_{i+1}y_{i+1}
y^=j=0∑nP(yj)yj=Siyi+Si+1yi+1
上述的Focal损失函数在
S
i
=
y
i
+
1
−
y
y
i
+
1
−
y
i
,
S
i
+
1
=
y
−
y
i
y
i
+
1
−
y
i
S_i=\frac{y_{i+1}-y}{y_{i+1}-y_i},S_{i+1}=\frac{y-y_i}{y_{i+1}-y_i}
Si=yi+1−yiyi+1−y,Si+1=yi+1−yiy−yi的时候达到最小,则可将其带入积分公式得到最后边界框的预测值。
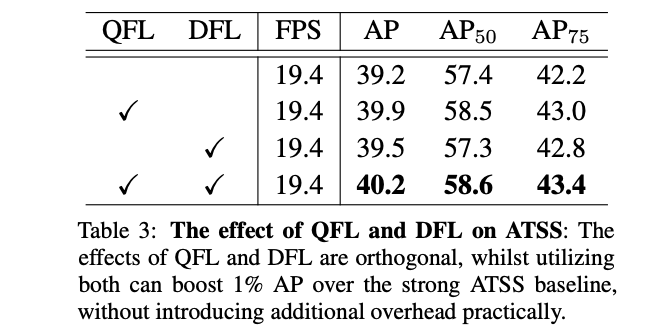
QFL与DFL对性能影响见下表所示:
2.2.3 GFL
从QFL和DFL基础上可以将focal的属性进行推广,从而适应更多的任务需求。这里假设模型输出2个点
y
l
,
y
r
y_l,y_r
yl,yr的概率
p
y
l
,
p
y
r
p_{y_l},p_{y_r}
pyl,pyr实现对真实回归量的估计:
y
^
=
y
l
p
y
l
+
y
r
p
y
r
\hat{y}=y_lp_{y_l}+y_rp_{y_r}
y^=ylpyl+yrpyr
因而,经过统一化之后的focal loss可以描述为:
G
F
L
(
p
y
l
,
p
y
r
)
=
−
∣
y
−
(
y
l
p
y
l
+
y
r
p
y
r
)
∣
β
(
(
y
r
−
y
)
l
o
g
(
p
y
l
)
+
(
y
−
y
l
)
l
o
g
(
p
y
r
)
)
GFL(p_{y_l},p_{y_r})=-|y-(y_lp_{y_l}+y_rp_{y_r})|^\beta((y_r-y)log(p_{y_l})+(y-y_l)log(p_{y_r}))
GFL(pyl,pyr)=−∣y−(ylpyl+yrpyr)∣β((yr−y)log(pyl)+(y−yl)log(pyr))
2.3 损失函数
文章的损失函数描述为:
L
=
1
N
p
o
s
∑
z
L
Q
+
1
N
p
o
s
1
{
c
z
∗
>
0
}
(
λ
0
L
B
+
λ
1
L
D
)
L=\frac{1}{N_{pos}}\sum_zL_Q+\frac{1}{N_{pos}}\mathcal{1}_{\{c_z^*\gt0\}}(\lambda_0L_B+\lambda_1L_D)
L=Npos1z∑LQ+Npos11{cz∗>0}(λ0LB+λ1LD)
其中,
L
Q
,
L
B
,
L
D
L_Q,L_B,L_D
LQ,LB,LD分别表示QFL、GIoU与DFL的损失。
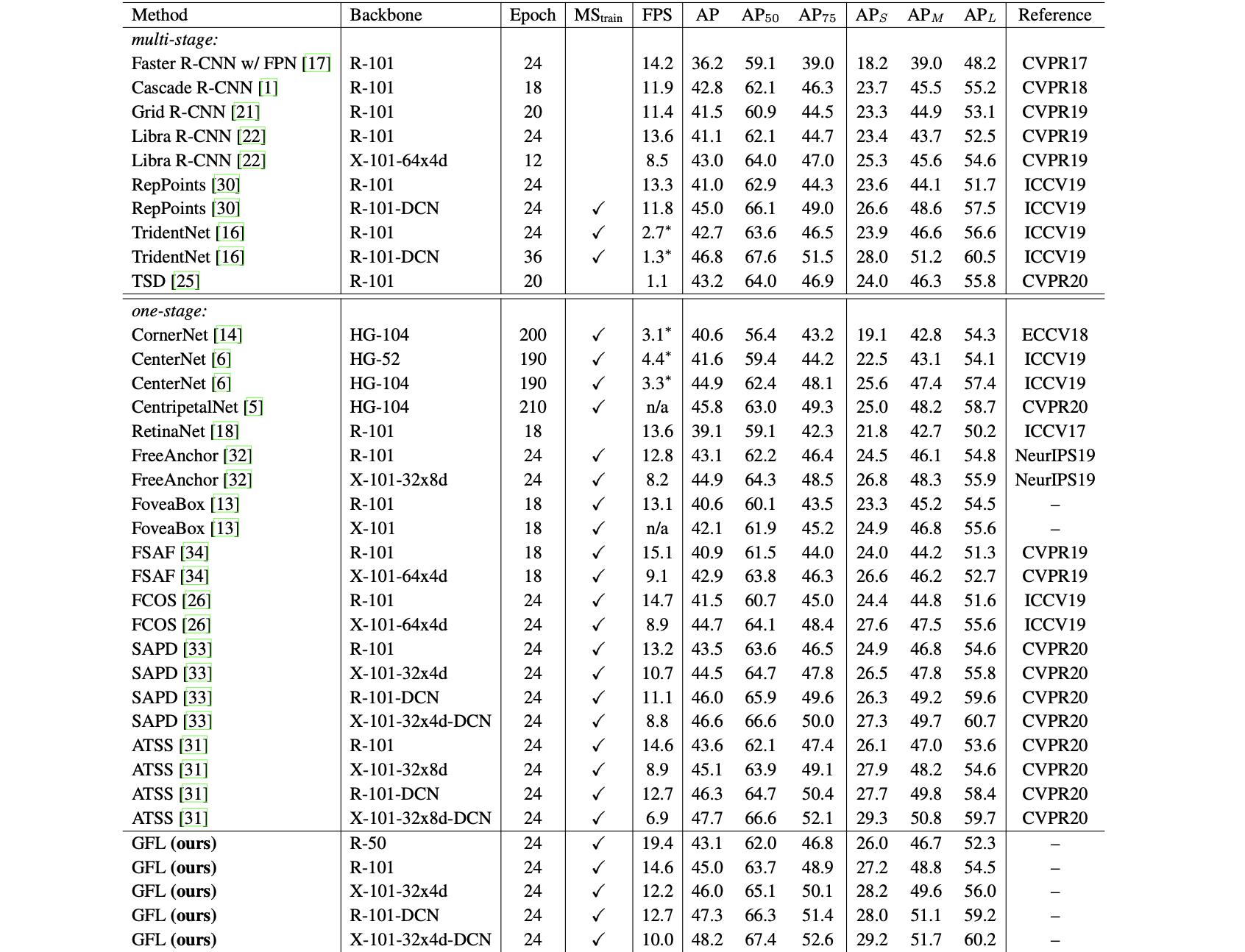
3. 实验结果


















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









