




 本文介绍了《Background Matting V2:Real-Time High-Resolution Background Matting》论文,该方法在V1基础上,针对4K和HD分辨率实现了高效的背景抠图,达到30FPS和60FPS的实时处理。通过基础网络Gbase和优化网络Grefine,以及路径选择策略,专注于处理复杂区域,提升了高分辨率下的运算效率。同时,论文提供了VideoMatte240K和PhotoMatte数据集,用于训练和评估网络性能。
本文介绍了《Background Matting V2:Real-Time High-Resolution Background Matting》论文,该方法在V1基础上,针对4K和HD分辨率实现了高效的背景抠图,达到30FPS和60FPS的实时处理。通过基础网络Gbase和优化网络Grefine,以及路径选择策略,专注于处理复杂区域,提升了高分辨率下的运算效率。同时,论文提供了VideoMatte240K和PhotoMatte数据集,用于训练和评估网络性能。
主页:background-matting-v2
参考代码:BackgroundMattingV2
1. 概述
导读:这篇文章在之前V1版本(在512*512输入的情况下只能跑到8FPS)的基础上针对高分辨率(HD,4K画质)提出了一种设计巧妙的matting方法,文章将其称之为之前方法的V2版本。该方法中将整个pipeline划分为两个部分:base和refine部分,前一个部分在缩小分辨率的输入下生成粗略的结果输出,其主要用于提供大体的区域位置定位(coarse predcition)。后一个网络在该基础上通过path selection选取固定数量的path(这些区域主要趋向于选择头发/手等难分区域)进行refine,之后将path更新之后的结果填充回原来的结果,从而得到其在高分辨率下的matting结果。整个pipeline下来文章的方法能在4K分辨率下跑到30FPS,在HD分辨率下跑到60FPS。当然文章使用的数据集(VideoMatte240K,PhotoMatte 13K/85)对最后结果的提升贡献了不少。
文章的方法设计的很巧妙,通过类似困难样本挖掘的方式排除了很大部分的简单区域,从而能够更好聚焦那些困难的区域,从而提升在高分辨率下的运算表现,文章的效果可以参考下图所示:

出了方法设计带来的运算速度提升之外,文章还提供了很多的matting数据集:
- 1)VideoMatte240K:包含了384段的4K视频数据和100段的高清数据;

- 2)PhotoMatte13K/85:其中包含了13665的高质量图片数据;

这些数据对最后网络性能的影响见下表所示:

2. 方法设计
2.1 整体pipeline与basic网络部分
假设输入的图片/背景图/alpha图/前景图分别使用
I
,
B
,
α
,
F
I,B,\alpha,F
I,B,α,F进行表示,那么将原来的背景替换之后得到的新图片描述为:
I
‘
=
α
F
+
(
1
−
α
)
B
‘
I^{‘}=\alpha F+(1-\alpha)B^{‘}
I‘=αF+(1−α)B‘
不同于之前直接预测前景,文章是通过预测前景的残差
F
R
=
F
−
I
F^R=F-I
FR=F−I,这样的改动文章指出可以提升训练的效果,使得可以将前景预测放置在较低的分辨率网络下。对于最后前景图的结果通过下面的方式得到:
F
=
max
(
min
(
F
R
+
I
,
1
)
,
0
)
F=\max(\min(F^R+I,1),0)
F=max(min(FR+I,1),0)
其实在matting的过程中绝大部分的像素都是在
[
0
,
1
]
[0,1]
[0,1]上取值的,这就使得可以在低分辩网络下预测这些像素,而在高分辨下预测那些之间的像素(也就是文章说到的困难部分),对此文章是通过采样的方式进行path select,之后对path进行优化,可参考下图所示:

这里将文章的pipeline划分为两个部分
G
b
a
s
e
G_{base}
Gbase和
G
r
e
f
i
n
e
G_{refine}
Grefine:
- 1)基础网络 G b a s e G_{base} Gbase:该网络用ResNet-50作为backbone,后面嫁接DeepLab-V3系列网络的部分结构,再通过双线性采样操作构建一个编解码结构。它的输入是下采样的原始图和背景图 I c , B c I_c,B_c Ic,Bc,其中 c c c是下采样的stride值,该网络预测 出 α c \alpha_c αc,前景信息 F c R F_c^R FcR,alpha预测错误图 E c E_c Ec,网络隐层特征(32个channel) H c H_c Hc;
- 2)优化网络 G r e f i n e G_{refine} Grefine:该网络使用 H c , I , B H_c,I,B Hc,I,B去优化 α c , F c R \alpha_c,F_c^R αc,FcR,被选中去优化的部分便是 E c E_c Ec中值比较大的部分。之后生成与原图像大小一致的alpha图和前景图;
文章的整体pipeline见下图所示:
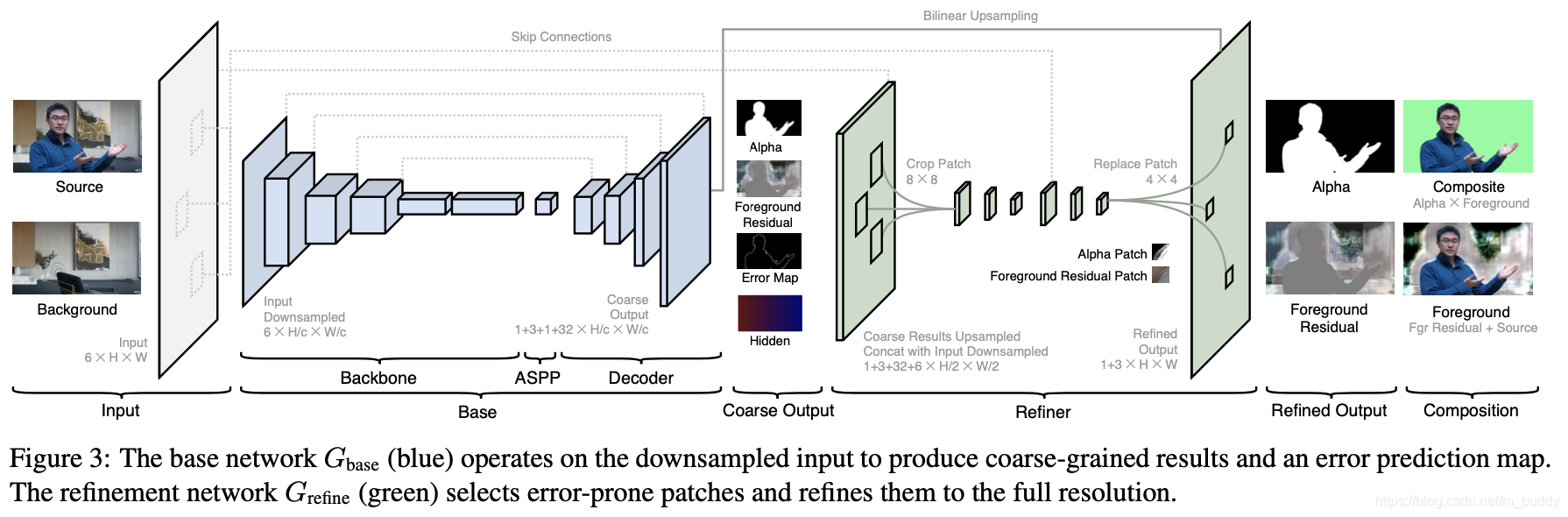
2.2 优化网络部分
前面简单说到了基础网络 G b a s e G_{base} Gbase是由ResNet-50和DeepLab-V3构成的编解码网络结构,输出得到的结果是原始输入尺寸的 1 c \frac{1}{c} c1,这个参数回根据输入尺寸的变化而变化,如,对于4K的分辨率取值为8。
得到上述的粗略优化结构之后文章将预测错误图 E c E_c Ec采样到原始输入尺寸的 1 4 \frac{1}{4} 41,从而对于预测错误图 E c E_c Ec就变成了 E 4 E_4 E4,之后按照错误信息的值选择 k k k个错误最大的区域( k k k的取值需要在效率与结果中进行权衡),因而选中的像素代表的便是去优化原图中的 16 ∗ ( 4 ∗ 4 ) 16*(4*4) 16∗(4∗4)大小的patch。
接下来便是分为两个阶段对粗糙的结果进行优化:
- 1)将 α c , F c R , H c , I , B \alpha_c,F_c^R,H_c,I,B αc,FcR,Hc,I,B采样到原始输入尺寸的 1 2 \frac{1}{2} 21,并将这些输入concat起来,之后在预测错误图 E 4 E_4 E4上选中位置处抠取 8 ∗ 8 8*8 8∗8大小的patch(在),之后经过两个卷积之后分辨率变成 4 ∗ 4 4*4 4∗4,之后又将它采样到 8 ∗ 8 8*8 8∗8与 B , I B,I B,I对应位置处抠取的 8 ∗ 8 8*8 8∗8数据concat,之后经过两个卷积分辨率 4 ∗ 4 4*4 4∗4(这里已经和 E 4 E_4 E4所在分辨率一致),会预测出对应的alpha和前景信息;
- 2)将 α c , F c R \alpha_c,F_c^R αc,FcR上采样到输入的分辨率,之后将patch优化的结果与粗糙的结果进行替换,从而得到最后优化之后的结果;
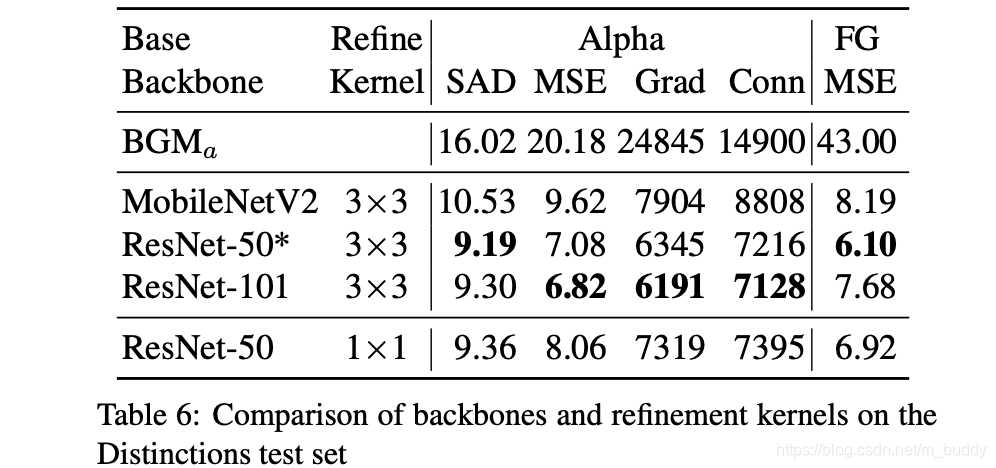
两个网络对于最后性能的影响见下表所示:

2.3 训练过程
对于数据增广采用了随机替换高清背景,仿射变换/水平翻转/亮度对比度饱和度调整/滤波/锐化/随机噪声等方式,而且对前景和背景都是分别处理的。
对于损失函数主要是去监督alpha图像和前景信息。对于alpha图(
α
\alpha
α是预测结果,
α
∗
\alpha^{*}
α∗是GT,后续带星的以此类推),其损失描述为:
L
α
=
∣
∣
α
−
α
∗
∣
∣
1
+
∣
∣
∇
α
−
∇
α
∗
∣
∣
1
L_{\alpha}=||\alpha-\alpha^{*}||_1+||\nabla_{\alpha}-\nabla_{\alpha^{*}}||_1
Lα=∣∣α−α∗∣∣1+∣∣∇α−∇α∗∣∣1
对于前景部分损失函数为:
L
F
=
∣
∣
(
α
∗
>
0
)
∗
(
F
−
F
∗
)
∣
∣
1
L_F=||(\alpha^{*}\gt 0)*(F-F^{*})||_1
LF=∣∣(α∗>0)∗(F−F∗)∣∣1
对于预测错误图的GT描述为
E
∗
=
∣
α
−
α
∗
∣
E^{*}=|\alpha-\alpha^{*}|
E∗=∣α−α∗∣,其预测损失函数为:
L
E
=
∣
∣
E
−
E
∗
∣
∣
2
L_{E}=||E-E^{*}||_2
LE=∣∣E−E∗∣∣2
结合base和refine网络的输入与输出则两个网络的损失函数描述为:
L
b
a
s
e
=
L
α
c
+
L
F
c
+
L
E
c
L_{base}=L_{\alpha_c}+L_{F_c}+L_{E_c}
Lbase=Lαc+LFc+LEc
L
r
e
f
i
n
e
=
L
α
+
L
F
L_{refine}=L_{\alpha}+L_F
Lrefine=Lα+LF
对于参数初始化ResNet-50部分使用ImageNet的预训练模型参数,DeepLab-V3中的参数使用Pascal VOC上训练的参数,选择
c
=
4
,
k
=
5
k
c=4,k=5k
c=4,k=5k与Adam优化器。一阶段中使用学习率为
[
1
e
−
4
,
5
e
−
4
,
5
e
−
4
]
[1e-4,5e-4,5e-4]
[1e−4,5e−4,5e−4]作为编码器/ASPP/解码器的学习率,之后加入refine网络,对应的学习率变为了
[
5
e
−
5
,
5
e
−
5
,
1
e
−
4
,
3
e
−
4
]
[5e-5,5e-5,1e-4,3e-4]
[5e−5,5e−5,1e−4,3e−4],使用的数据集为Video Matte 240K,训练完成之后在使用PhotoMatte 13K。
3. 实验结果

















 5556
5556








 到【灌水乐园】发言
到【灌水乐园】发言







