




 LOMO算法通过DR、IRM和SEM模块,解决了长文本和任意形状文本的检测问题。DR生成初步四边形框,IRM进行迭代优化,SEM学习中心线和边界偏移,提升检测准确性。
LOMO算法通过DR、IRM和SEM模块,解决了长文本和任意形状文本的检测问题。DR生成初步四边形框,IRM进行迭代优化,SEM学习中心线和边界偏移,提升检测准确性。
代码地址:暂无
1. 概述
导读:这篇文章提出的文本检测算法(LOMO)主要致力于去解决极端长文本与任意形状的文本检测问题,这篇文章处理文本区域表达的时候会处理多次(体现于IRM模块),也对应文章标题的Look More Than Once。这篇文章的检测算法主要由直接回归单元(direct regressor,DR)(源于EAST)、迭代优化模块(iterative refinement module,IRM)与任意形状表达模块(shape expression module,SEM)三部分组成。DR生成一个文本区域的四边形检测框;IRM模块通过先前会对四边形检测框提取的特征块进行迭代优化,从而逐渐感知到整个长文本;SEM模块结合文本区域的几何特征在IRM模块的基础上重建更加精准的文本区域表达,包括文本的区域、文本中心线以及边界的偏移量;
现有的文本检测方法存在CNN感受野不足(实际感受野小于理论值)与文本区域表达存在限制的问题,具体见图1所示

在图1(a)中每个虚线网络代表的是对应点出的感受野,可以看出对于那种横贯整个图像的文本CNN是很难一次性全部捕获的,对此文章是从局部到整体逐步优化实现的。在图1(b)中展示的是文本表达能力的限制,扭曲形状更适合扭曲文本表达的形式。
对于上面提到的两个问题,文章中的算法通过IRM与SEM模块进行解决。对于长文本的检测,IRM会在DR四边形检测结果的基础上多次回归与GT对应的坐标,依赖于位置的attention机制,IRM可以感受这些位置信息,从而优化整个输入区域。
对于任意形状的文本,这里借鉴了Mask RCNN与TextSnake的机制使用文本中心线与对应偏移量的形式来表示一个文本。
文章的主要贡献:
- 1)提出了一个迭代优化模块IRM去优化长文本的检测;
- 2)提出了SEM模块适应任意形状的文本检测;
- 3)文章提出的检测算法是端到端的并且在现有的多个数据集上表现为state-of-the-art;
2. 方法设计
2.2 网络结构
文章的网络结构backbone选用的是ResNet-50,使用FPN将stage2~5的特征融合起来,得到分辨率为原始输入图尺寸
1
4
\frac{1}{4}
41的特征图,通道为128。

对于DR部分直接是参考EAST中的回归方法,由于感受野的关系得到的检测结果并不能很好包含文本区域,见图2(2)所示。之后IRM模块在DR输出的基础上进行迭代优化使得检测框与GT接近。之后SEM模块中去学习文本的中心线与边界的偏移,从而得到任意形状文本的检测结果。
文章的网络结构backbone选用的是ResNet-50,使用FPN将stage2~5的特征融合起来,得到分辨率为原始输入图尺寸 1 4 \frac{1}{4} 41的特征图,通道为128。
对于DR部分直接是参考EAST中的回归方法,由于感受野的关系得到的检测结果并不能很好包含文本区域,见图2(2)所示。之后IRM模块在DR输出的基础上进行迭代优化使得检测框与GT接近。之后SEM模块中去学习文本的中心线与边界的偏移,从而得到任意形状文本的检测结果。其网络结构见下图所示:

2.2 DR模块
在DR模块中将文本与非文本的二分类问题转换为了二值分割问题,并使用了尺度不变的dice-coefficient作为损失函数,其定义为:
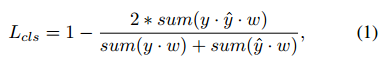
其中,
y
y
y是二值标注,
y
^
\hat{y}
y^是预测结果,
w
w
w是二维权值空间,其中对于正样本位置设置为值
l
=
64
l=64
l=64,负样本位置为1.0。
对于检测框的坐标值回归使用的是smooth L1损失函数,对于4个角点采用的是8个特征图进行预测。则对于这部分的损失函数为:
L
d
r
=
λ
L
c
l
s
+
L
l
o
c
L_{dr}=\lambda L_{cls}+L_{loc}
Ldr=λLcls+Lloc
这里
λ
=
0.01
\lambda=0.01
λ=0.01。
2.3 IRM模块
IRM模块的设计参考了基于区域的检测算法思路(其中的边界框回归任务),这里采用RoI transform layer去提取四边形proposal区域,这样的好处是保持长宽比例不变(所以并未采用RoI Pooling或RoI align Pooling),其输出的维度是
1
∗
8
∗
64
∗
128
1*8*64*128
1∗8∗64∗128。由于与文本区域角点接近的位置能够在相同感受野下获得更加精准的边界信息,这里使用Corner attention机制去回归相对每个角点的坐标偏移。
IRM模块的结构见下图所示:
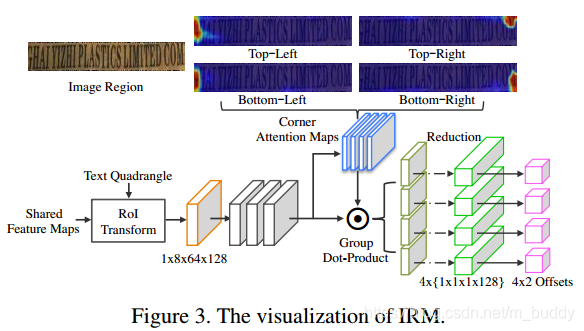
RoI transform layer的输出经过3个
3
∗
3
3*3
3∗3的卷积得到
f
r
f_r
fr,之后使用一个
1
∗
1
1*1
1∗1的卷积与sigmoid操作去学习4个角点的特征图
m
a
m_a
ma,之后将两个输出做分组点乘与sum reduce操作:
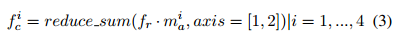
其输出结果为
f
c
i
f_c^i
fci代表的是第
i
i
i个角点回归特征,维度为
1
∗
1
∗
1
∗
128
1*1*1*128
1∗1∗1∗128。这样就可以得到4个角点的回归特征图。在训练的时候选择DR模块中的前
K
K
K个结果用于训练,则角点部分的损失函数被定义为:
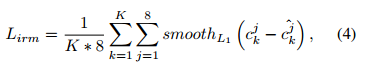
2.4 SEM模块
SEM模块中三个比较关键的部分是文本区域分割图、文本中心线以及文本区域的边界偏移。对于文本中心线是在原文本区域的基础上进行收缩得到的,而边界偏移是文本中心线在一个点上的法线与上下边界的角点,这里用4个特征图去回归。则整个SEM模块的结构见下图所示:
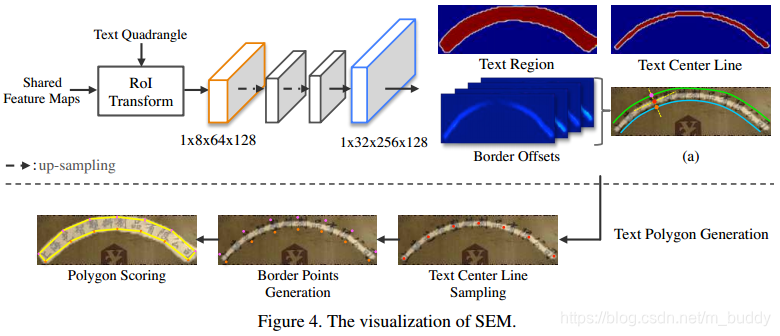
这里涉及到三个部分的回归损失,对于这三个部分的损失采用的是如下方式进行组合,其中
λ
1
=
λ
2
=
0.01
,
λ
3
=
1
\lambda_1=\lambda_2=0.01,\lambda_3=1
λ1=λ2=0.01,λ3=1
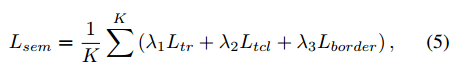
对于文中涉及到的3个部分的损失,这里是使用如下的方式进行组合(加权值都为1.0):
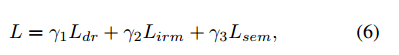
3. 实验结果
3.1 性能比较
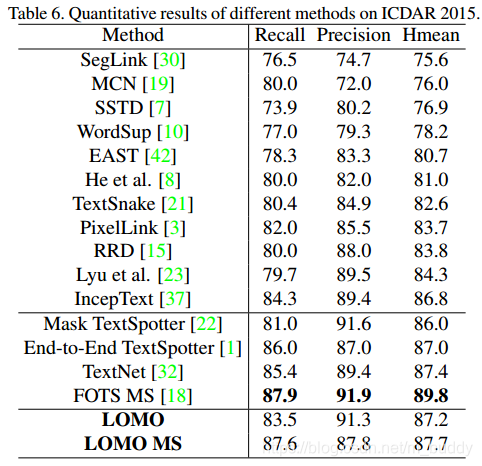
ICDAR 2015:
ICDAR 2017-MLT
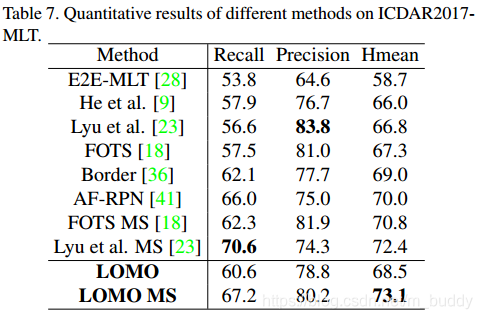
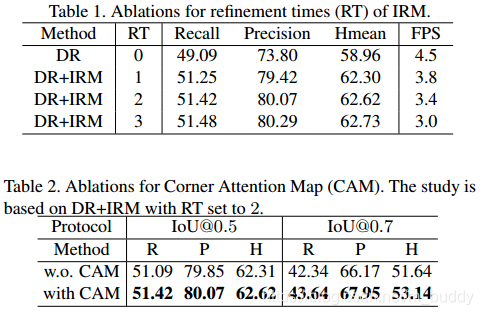
3.3 消融实验
IRM中迭代优化次数与角点注意力机制对性能的影响:
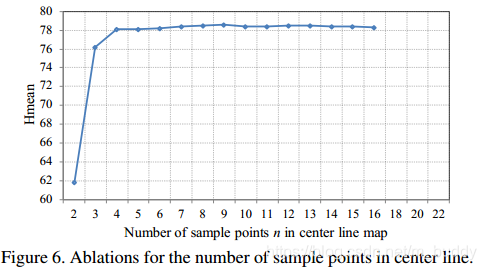
中心线上点的采样个数对性能的影响:
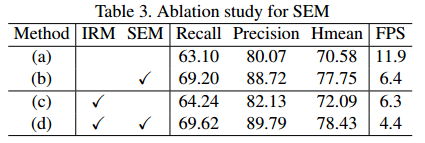
IRM与SEM对性能的影响:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









