






〔更多精彩AI内容,尽在 「魔方AI空间」 公众号,引领AIGC科技时代〕
本文作者:猫先生
AIGCmagic社区知识库(免费访问)
原文地址: 开源实操 | 腾讯VTA-LDM:让你的视频自动生成完美音效
简介
根据视频输入生成语义和时间对齐的音频内容已成为研究人员的焦点,特别是在文本到视频生成方面取得了显著突破之后。
在这项工作中,VTA-LDM目标是提供对视频到音频生成范例的见解,重点关注三个关键方面:视觉编码器、辅助嵌入和数据增强技术。
VTA-LDM 是由腾讯人工智能实验室开发的一项新技术,其主要作用是利用AI自动给视频生成符合视频内容的音效!比如视频里是海浪拍打沙滩,它就能生成哗啦哗啦的海浪声;要是视频里是热闹的街市,它就能生成嘈杂的人声和车声。
方法概述
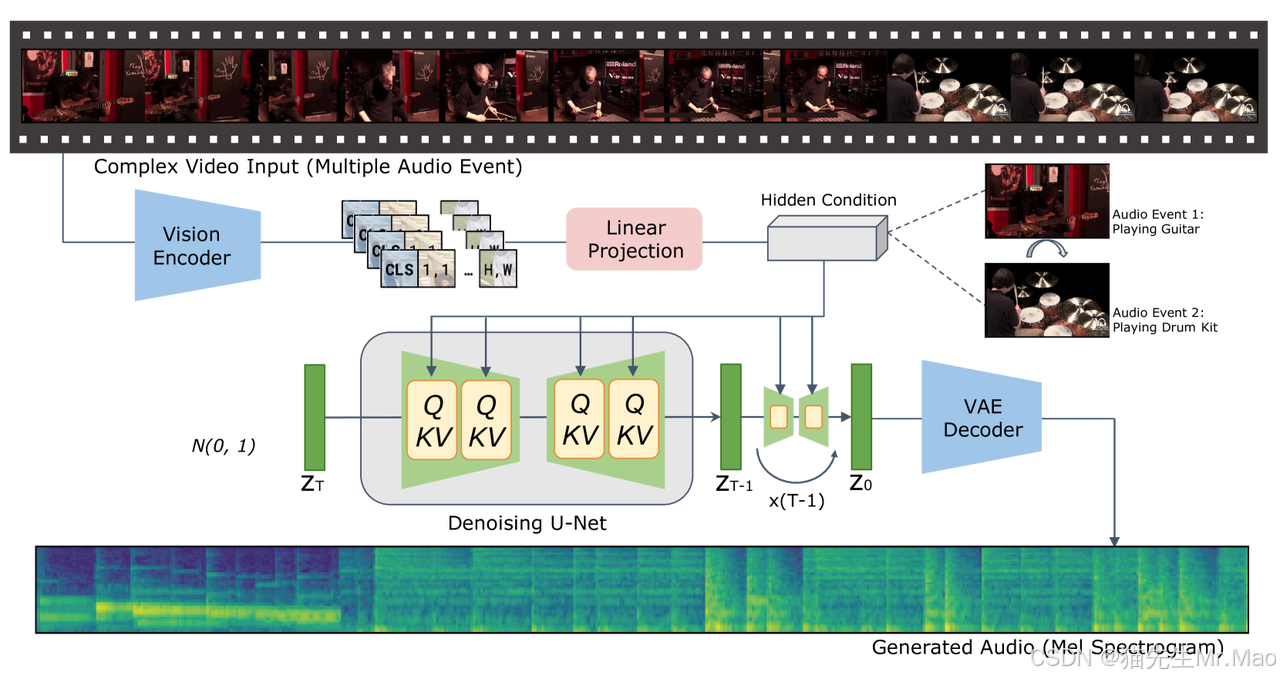
图 1:VTA-LDM 框架概述。给定无声视频,该模型会生成语义相关且时间对齐的音频,准确对应于视觉事件。该框架基于以编码视觉特征作为生成条件的LDM。
从之前的TTA工作和多模态研究中汲取灵感,研究者开发了一个基本的VTA框架。VTA-LDM由几个关键组件组成:视觉编码器、条件LDM和梅尔频谱图/音频变分自动编码器(VAE)。
具体来说,利用从预先训练的视觉编码器中提取的视觉特征,并通过线性投影层将它们输入LDM作为生成条件。 LDM对梅尔频谱图的潜在音频表示进行操作。预训练的音频VAE有助于将去噪的潜在输出解码为梅尔频谱图,然后将其馈送到声码器以生成最终音频。
视觉编码器
视觉编码器不仅负责编码视频的语义 V,还有与生成的音频对齐所需的时间信息。采用预训练的视觉编码器 fV,例如 CLIP4CLIP,从输入视频中提取视觉特征。这些功能捕获基本的视觉信息,包括对象、动作和场景上下文。使用投影层 ϕ 将这些特征映射到扩散条件的所需维度。视觉编码器在训练过程中全部被冻结,而投影层将从头开始训练。
潜在扩散模型(LDM)
给定原始输入 x0 ,扩散模型遵循马尔可夫链扩散步骤,逐渐向数据添加随机噪声,直到其遵循高斯分布 N(0,I) ,代表为 xt 。然后模型学习反向去噪过程以恢复原始输入数据。为了提高计算效率, LDM结合了训练有素的感知压缩模型来对输入进行编码 x 进入低维潜在空间 Z 。在基于文本的生成任务中,生成条件通常是给定的文本描述。在VTA实现中,条件 c 是投影视频特征 ϕ(fV) 。为了执行顺序去噪,研究者训练一个网络 ϵθ 预测人工噪声,遵循以下目标:
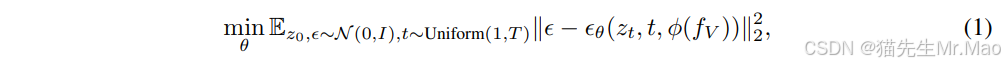
在基于文本的生成中, ∅ 通常定义为 ϕ(” ”) 来表示空条件。在TTA任务中,使用零嵌入作为 ϕ(NULL) ,代表零视觉条件。
音频VAE和声码器
首先使用短时傅立叶变换(STFT) 将音频源传送到梅尔频谱图,然后传送到潜在表示 z 带有预先训练的音频VAE。研究者使用 AudioLDM 中预先训练的VAE。在相反的过程中,音频从潜在的恢复 z 使用 Hifi-GAN 声码器。
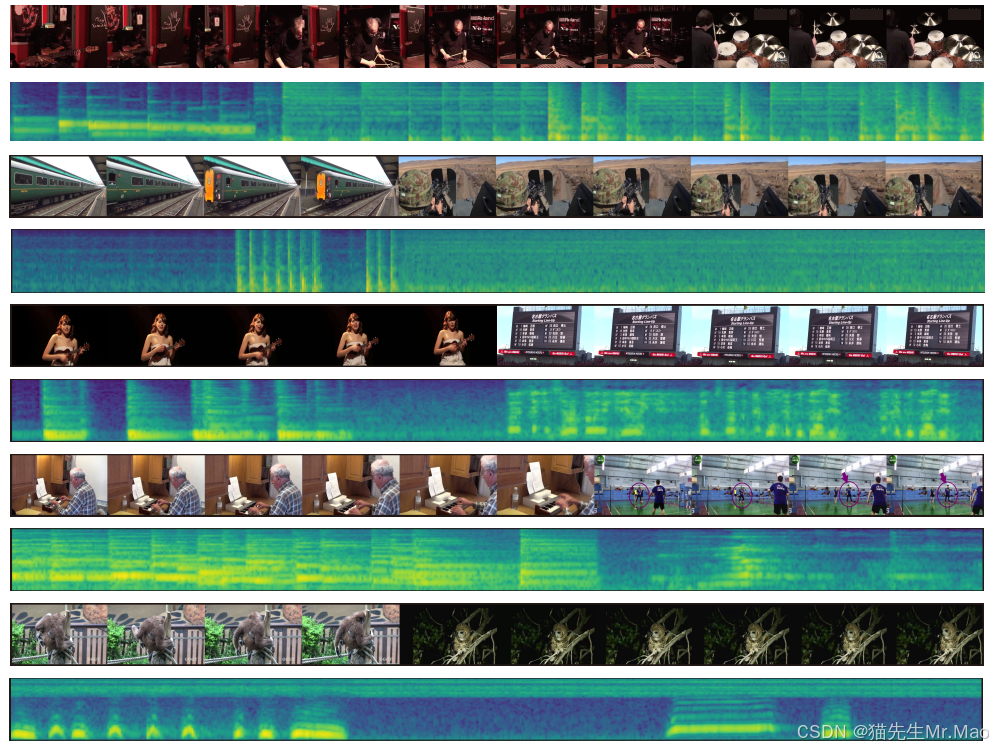
图 2:VTA生成的演示。给定无声视频,模型会生成语义相关且时间对齐的音频,准确对应于视觉事件。
实操部署
关于vta-ldm的代码和模型文件**,已打包好了,关注【魔方AI空间】,回复“222”即可领取!!
- 安装依赖
首先安装 python,建议使用 conda:
conda create -n vta-ldm python=3.10
conda activate vta-ldm
pip install -r requirements.txt
- 下载模型权重
从Huggingface下载模型,建议使用 git lfs:
mkdir ckpt && cd ckpt
git clone https://huggingface.co/ariesssxu/vta-ldm-clip4clip-v-large
# pull if large files are skipped:
cd vta-ldm-clip4clip-v-large && git lfs pull
按照以下文件夹结构放置预训练权重。
ckpt
└─── vta-ldm-clip4clip-v-large
- 运行推理
将视频片段放入data目录中。运行提供的推理脚本以从输入视频生成音频内容:
bash inference_from_video.sh
出现以下界面,则表示运行成功!

可以自定义超参数以满足您的个人需求。我们还提供了一个脚本,可以帮助基于 ffmpeg 将生成的音频内容与原始视频合并:
bash tools/merge_video_audio
出现如下界面,则合并成功!!
技术交流
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在 「魔方AI空间」,关注了解全栈式 AIGC内容!!


















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









