




 本文详细介绍如何在Struts2框架下实现文件下载功能,包括Action类编写、struts.xml配置、请求参数编码处理及下载链接生成。通过具体示例展示文件下载的完整流程。
本文详细介绍如何在Struts2框架下实现文件下载功能,包括Action类编写、struts.xml配置、请求参数编码处理及下载链接生成。通过具体示例展示文件下载的完整流程。
编写Action类
package blog.csdn.net.mchenys.action;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import javax.servlet.http.HttpServletRequest;
import org.apache.commons.io.FileUtils;
import org.apache.struts2.ServletActionContext;
import com.googlecode.sslplugin.annotation.Secured;
import com.opensymphony.xwork2.ModelDriven;
import blog.csdn.net.mchenys.domain.User;
import blog.csdn.net.mchenys.utils.UploadUtils;
public class TestAction extends ActionSupport{
private static final long serialVersionUID = 1L;
// 文件下载
private String fileName;// 文件名称
private String downloadPath;//文件下载路径
//属性驱动方式注入值
public void setFileName(String fileName) {
System.out.println("===setFileName==="+fileName);
this.fileName = fileName;
}
/**
* 返回文件名,对应struts.mlx中的<param name="contentDisposition">中的filename=${fileName}
* @return
*/
public String getFileName() {
System.out.println("===getFileName==="+fileName);
return fileName;
}
/**
* 返回InputStream,对应struts.mlx中的<param name="inputName">inputStream</param>
*
* @return
*/
public InputStream getInputStream() {
System.out.println("====getInputStream====");
try {
//转换格式,否则输出的文件名有中文时,浏览器不会显示
this.fileName=new String(fileName.getBytes(),"iso-8859-1");
//返回文件下载流
return new FileInputStream(new File(downloadPath));
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 文件下载
*
* @return
*/
public String download() {
System.out.println("====download====");
// 获取绝对路径
this.downloadPath = ServletActionContext.getServletContext().getRealPath("/download/"+fileName);
System.out.println("downloadPath:"+downloadPath);
/*try {
// 解决下载的文件名是中文的文件获取文件名时乱码问题,如果已经配置过编码拦截器的可以不需要处理
this.downloadPath = new String(downloadPath.getBytes("ISO-8859-1"), "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}*/
return "downloadOK";
}
}
编辑struts.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.3//EN"
"http://struts.apache.org/dtds/struts-2.3.dtd">
<struts>
<package name="test" extends="struts-default" namespace="/test">
<interceptors>
<interceptor name="encoding"
class="blog.youkuaiyun.com.mchenys.intercept.EncodingIntereptor" />
<!-- 定义拦截器栈 -->
<interceptor-stack name="myStack">
<!-- 引入自定义的拦截器 -->
<interceptor-ref name="encoding" />
<!-- 引入默认的拦截器 -->
<interceptor-ref name="defaultStack" />
</interceptor-stack>
</interceptors>
<action name="*" class="blog.youkuaiyun.com.mchenys.action.TestAction" method="{1}">
<!-- 引入拦截器栈 -->
<interceptor-ref name="myStack" />
<!-- 文件下载 -->
<!-- result类型是流(stream)类型 -->
<result name="downloadOK" type="stream">
<!-- inputName指向被下载文件的来源,对应Action中返回的InputStream -->
<param name="inputName">inputStream</param>
<!-- 指定文件下载的处理方式,内联(inline)和附件(attachment)两种方式,attachment会弹出文件保存对话框 -->
<param name="contentDisposition">attachment;filename=${fileName}</param>
<!--指定下载文件的缓冲大小 -->
<param name="bufferSize">4096</param>
</result>
</action>
</package>
</struts>
编写请求参数编码拦截器
这里我直接使用的是上一篇文章的拦截器,详情
编写下载链接
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
<style type="text/css">
h1{font-size: 30px;}
</style>
<script type="text/javascript">
</script>
</head>
<body>
<h1><a href="${pageContext.request.contextPath }/test/download?fileName=我看好你哦.jpg">我看好你哦.jpg</a></h1>
<h1><a href="${pageContext.request.contextPath }/test/download?fileName=c.mp4">c.mp4</a></h1>
</body>
</html>
添加下载资源
测试
在这里插入图片描述
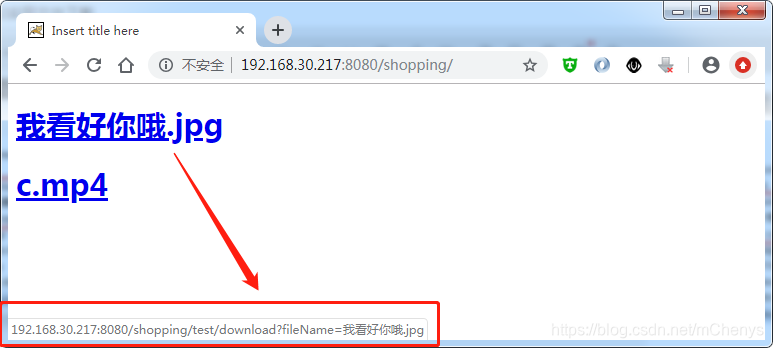
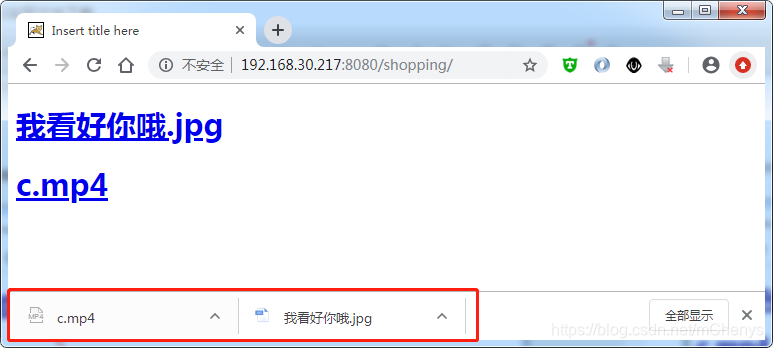
鼠标移动到链接上,可以看到完整的下载路径,点击下载后,也能正确的显示下载的文件名
查看控制台输出的内容,可以看出Action中那几个方法的调用顺序
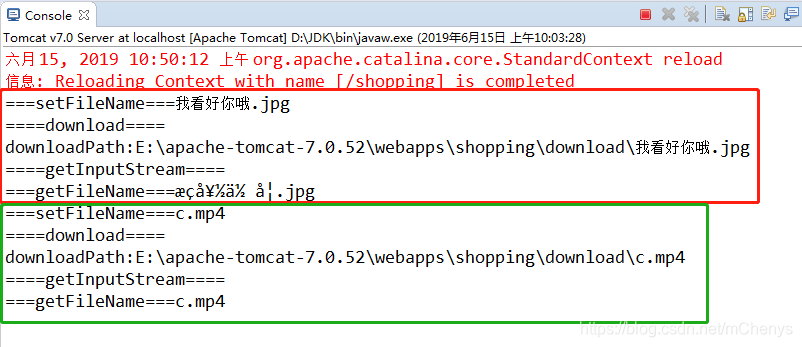
可以看到setFileName是最先执行的,因为请求参数注入fileName的时候会调用,然后是调用download方法,该方法是action的方法是必定执行的,接着是getInputStream方法获取文件读取流,也就是需要下载的文件,最后是getFileName,这个是文件下载后显示的名称,细心的你会发现中文显示了乱码,这个是因为getInputStream方法中我对文件名进行了编码,如果不这样处理的话,浏览器下载文件名显示不了中文,至于控制台输出是乱码,那是因为我的web项目的编码是utf-8的格式。
搞定~~
补充一点,如果要返回contentLength给客户端,可以在Action中添加多一个方法
private String contentLength;//文件下载的长度
/**
* 返回文件的长度,对应struts.xml中的<param name="contentLength">contentLength</param>
* @return
*/
public String getContentLength() {
System.out.println("===getContentLength==="+contentLength);
return contentLength;
}
修改download方法,设置文件长度
/**
* 文件下载
*
* @return
*/
public String download() {
System.out.println("====download====");
// 获取绝对路径
this.downloadPath = ServletActionContext.getServletContext().getRealPath("/download/"+fileName);
//指定文件长度
this.contentLength = String.valueOf(new File(downloadPath).length());
System.out.println("downloadPath:"+downloadPath);
/*try {
// 解决下载的文件名是中文的文件获取文件名时乱码问题,如果已经配置过编码拦截器的可以不需要处理
this.downloadPath = new String(downloadPath.getBytes("ISO-8859-1"), "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}*/
return "downloadOK";
}
修改struts.xml,在<result name="downloadOK" type="stream"></result>内指定文件长度
<param name="contentLength">contentLength</param>
这样,客户端就可以拿到contentLength,如下所示:
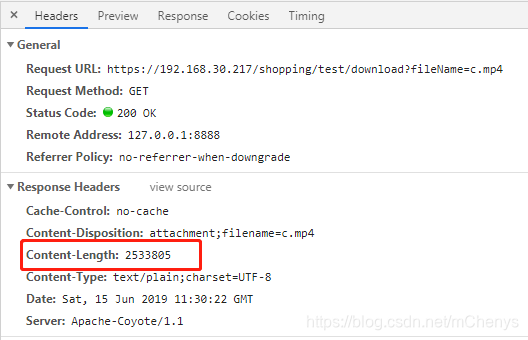
附上控制台输出log
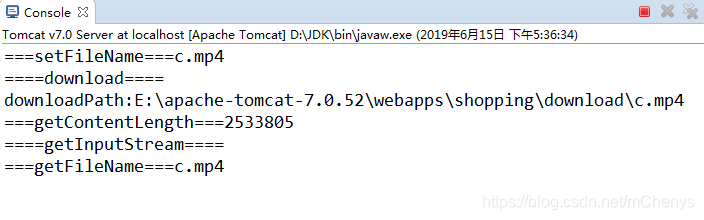
可见getContentLength是优先getInputStream方法执行的.

















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









