







目录
1.基础查询
判断是否为空查询 is null
is null (是否为空)
-
查询没有上级领导的编号,姓名,工资
select empno,ename,sal from emp Where mgr is null;2. 查询emp表中没有奖金(comm)的员工姓名,工资和奖金
Select comm,ename,sal from emp where comm is null;is not null (是否不为空)
查询emp表中有奖金的员工所有信息
Select * from emp
where comm is not null;去重查询 distinct
distinct去重复的数据
1.查询emp表中有奖金的员工所有信息
Select job from emp;----没有去除重复样图:
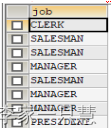
Select distinct job from emp;--去除重复后的样图:
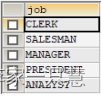
为字段起名查询
1. 查询emp中所有姓名,将ename显示成’姓名’
select ename as '姓名' from emp;
Select ename ‘姓名’ from emp;---建议的写法
Select ename 姓名 from emp;比较运算符
(>,<,>=,<=,=(相等),!=和<>)
1.查询工资小于等于1600的所有员工姓名和工资
Select ename,sal from emp where sal<=1600;2.查询部门编号是20的所有员工姓名,职位(job)和部门编号
select ename,job,deptno from emp where deptno=20;3.查询职位是manager的所有员工姓名和职位
Select ename,job from emp where job=’manager’;4.查询不是10号部门的所有员工姓名和部门编号使用两种方式实现:
Select ename,deptno from emp where deptno !=10;Select ename,deptno from emp where deptno <>10;逻辑运算符
and 和or
And 和java中的 && 效果一样
Or 和java中的 || 效果一
1.查询不是10号部门并且工资小于3000的员工信息
Select * from emp where deptno !=10 and sal<3000;2.查询部门编号为30或者上级领导为7698的员工姓名,职位,上级 ,领导和部门领导
Select ename,job,mgr,deptno from emp
where deptno =30 or mgr = 7698in 与between and
In(包含)后面是一个结果集
例如:
-
查询emp表中工资为5000,1500,3000的员工信息(两种方法)
Select *from emp where sal in(5000,1500,3000)
Select *from emp where sal=5000 or sal=1500 or 3000Between x and y(在x和y之间 包括x和y)
1.查询emp表中工资在2000至4000之间的员工信息
Select * from emp where sal between 2000 and 4000;模糊查询
_:代表单个任意未知字符
%:代表0个或多个任意未知字符
举例 :
包含字符a: %a%
以a开头:a%
以a结尾:%a
第二个字符是a:_a%
倒数第二个字符是a:%a_
第二个字符是a,最后一个字符是b:_a%b
例如
1.查询标题中包含(title包含记事本)记事本的商品标题
select title from t_item where title like'%记事本%'结果:

2.查询单价在50到200之间的得力商品的标题和单价
select price,title from t_item where price between 50 and 200 and title like'%得力%';3.查询单价低于100的记事本(title包含记事本)标题和单价
select title,price from t_item where price<100 and title like'%记事本%';4.查询所有 图片(image字段不能为空)的得力商品信息
select * from t_item where image is not null and title like '%得力%'| MYSQL练习 |
|---|
| 创建t_item表后,完成如下需求: |
| 1.查询分类(category_id)为238和971的商品信息 |
| select * from t_item where category_id in (238,971); |
| 2. 查询含有赠品的商品信息(sell_point中包含赠字) |
| Select sell_point from t_item where sell_point like ‘%赠%’; |
| 3.查询标题中不包括的得力的商品标题 |
| Select title from t_item where title not like ‘%得力%’ |
| 4. 查询价格介于50~200之外的商品信息 |
| Select * from t_item where price not between 50 and 200; |
2.排序(order by)
order by 写在where后面,没有where写在最后,by后面写字段名称
默认排序方式是升序(从小到大),也可以手动置顶(asc 升序(默认),desc 降序)
案例
1.查询所有员工的姓名和工资,按照工资将排序
select ename,sal from emp order by sal desc结果:
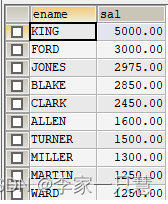
2.查询所有dell商品,按单价降序排序
select price from t_item where title like'%dell%' order by price desc结果:
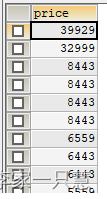
3.查询所有员工信息按照部门编号升序排序,工资降序排序
select * from emp order by deptno asc,sal desc3.分页查询
(limit 跳过数量,每页数量)
计算公式 (limit(页数-1)*每页条数,每页条数
1.查询所有商品,按照单价升序排序,显示第二页,每页7条数据
select * from t_item order by price asc limit 7,7结果:

2.(1)查询工资前三名的信息
select * from emp order by sal desc limit 0,3(2)查询工资前三名的名字
Select ename from emp order by sal desc limit 0,3;4.数值计算
数值计算 + - * / 7%2 等效 Mod(7,2)
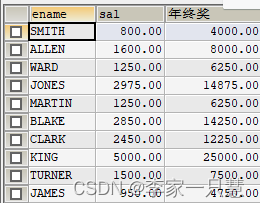
1.查询员工姓名,工资,及年终奖信息(年终奖=工资*5)
select ename,sal,sal*5 年终奖 from emp结果:
2.查询t_item表中商品单价,库存和总金额(总金额=单价*库存)
select price,num,price*num 总金额 from t_item5.日期相关的函数(方法)
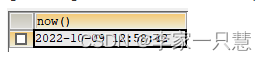
1.获取当前系统日期+时间 : now()
select now();结果:
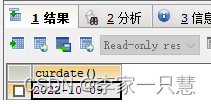
2.获取当前的日期 current : curdate()
Select curdate();结果:
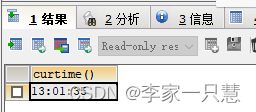
3.获取当前时间 current : curtime()
Select curtime();结果:
4.从年月日时分秒钟(now ())中提取年月日(date(时间))和提取时分秒time(时间)*
Select date (now());
Select time(now());结果:

5. 从年月日时分秒中,提取年,月,日,时,分,秒(extract())
Select extract (year from now());
Select extract (month from now());
Select extract (day from now());
Select extract (hour from now());
Select extract (minute from now());
Select extract (second from now());6.日期格式化函数(date_format(时间,格式))
Format:
%Y 四位的年,%y两位年,%m 两位月,%c 一位月,%d 日,
%H 24小时,%h 12小时,%i 分,%s秒
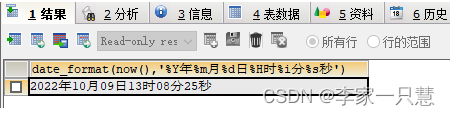
将now()转换成2022年05月27日 10时58分34秒
Select date_format(now(),'%Y年%m月%d日%H时%i分%s秒');结果:
7.把非标准的时间转成标准的格式(str_to_date(非标准格式的时间,格式)*
把14.08.2008 08:00:00转成标准格式
Select str_to_date('14.08.2008 08:00:00','%d.%m.%y %H:%i:%s');6. if null函数
Age = if null(x,y),如果x的值不为null 则age =x,如果age的值为null,age的值为y
SELECT IFNULL(1,0); -- returns 1 IFNULL(1,0)返回1,因为1不为NULL。
7.聚合函数
聚合函数
对多行数据进行统计
一般在select 后添加聚合函
求和
求和 :sum(字段名)
#emp表中工资的总和
Select sum(sal) 工资总和 from emp平均值
平均值 :avg(字段名)
#emp表中工资的平均值
Select avg(sal) 平均工资 from emp;最大值
最大值 := max(字段名)
#emp表中工资中最高的人的姓名和工资
select max(sal) 工资最高的人 ,ename,sal from emp;最小值
最小值 min(字段名)
#emp表中工资中最低的人的姓名和工资
select min(sal) 工资最低的人 ,ename,sal from emp;
---min(sal) 工资最低的人-->起别名统计数量
统计数量: count(*)
#统计工资小于100的人数
select count(*) 人数 from emp where sal<10008.字符串相关函数
1.字符串的拼接(concat(s1,s2))
举例:
查询emp表中员工姓名和工资,工资后有但单位 "元"
Select ename,concat(sal,'元') from emp;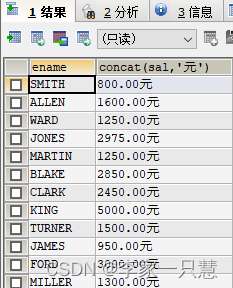
2.获取字符串的长度= (char_length(字符串))
举例:
#查询员工姓名的名字的长度
Select ename,char_length(ename) 员工名字的长度 from emp ; 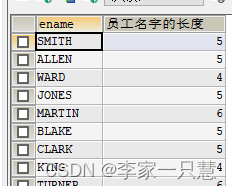
3.获取字符串在另外一个字符串中出现的位置(从1开始)
(insert(str,substr)) ,locate(substr,str))
方式一举例
Select instr ('abcdefg','d');
方式二举例
Select locate('d','abcdefg');
4.插入字符串,位置从1开始.* (格式insert(原字符,从几开始,插入长度,插入的字符串))
举例:
select insert ('abcdefg',3,2,'m');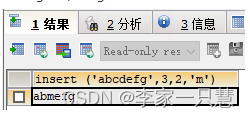
5,转大写和转小写 (upper,大写)(lower,小写)
举例:
select upper ('NBa'),lower('NBA'); 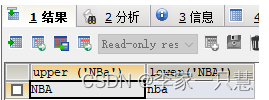
6.从左边截取,和从右边截取left(str,count) right(str,count)
举例:
select left('abcdefg',2);
Select right('abcdefg',3); 
7.去掉字符串两端的空格(格式:trim(字符串))
举例
select trim(' abcd ');8. 截取字符串(substring(原字符串,截取位置)
举例:
select substring('abcdefg',2);(在下标2的位置截取后面所有数)
select substring('abcdefg',2,4);(在下标2的位置截取4个)
9. 重复repeat(格式:repeat(字符串,重复几次))
举例 :
select repeat('a,b',3) 10.替换(replace(str, old,new))
举例:
select repeat('a,b',3) 
11. 翻转reverse
举例:
select reverse('abc');9.数字相关函数
1. 向下取整(floor(num))
举例:
select floor(3.84)://值为32.四舍五入(round(num))
举例:
select round(3.84)//值为43.四舍五入 设置小数位数(round(num , m)m代表小数位数)
举例:
select round(23.869,2);//23.874.非四舍五入(truncate(num ,m));
举例:
select truncate(23.869,2)//23.865.随机数(rand( )产生0-1之间的随机数)
举例:
select rand();
#获取3-8的随机数
select floor(rand()*6)+3;
10.分组查询(group by)
分组查询通常和聚合函数结合使用
一般情况下以 每个部门(职位,分类),就以部门(职位,分类)作为分组条件
可以有多个分组条件
1.查询每个部门的最高工资
举例:
select deptno,max(sal) from emp group by deptno;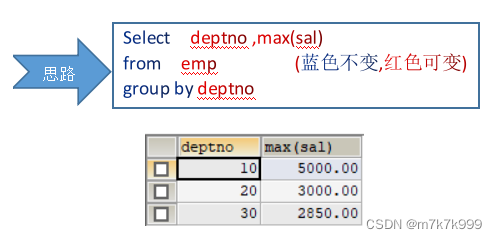
2.查询每个职位(job的平均工资)
举例:
Select job ,avg(sal) From emp Group by job3.查询每个部门下每个主管手下的人数
举例:
select deptno,mgr,count(*) from emp group by deptno,mgr;Group by 存在的位置 : select* from 表名 where...group by ..order by..limit
4.查询每个部门的平均工资,要求平均工资大于2000
举例:
SELECT AVG(sal),deptno
FROM emp
GROUP BY deptno
HAVING AVG(sal)>2000使用having解决聚合函数的条件过滤问题,having要写在group by后面,
Where 后面写普通字段的过滤条件,having后面写聚合函数的过滤条件
5.查询每个分类商品的库存总量高于199999的库存总量?
举例:
select category_id,sum(num) s
from t_item
group by category_id
having s>199999;6.查询每个分类商品所对应的平均单价,要求平均单价低于100?
Select Category_id,avg(price) p
From T_item
Group by category_id
Having P<100;7.查询分类id为238和917两个分类的平均单价
Select category_id ,avg(price)
From t_item
Where category_id in(238,917)
Group by category_id;8.查询emp表中每个部门的平均工资高于2000的部门编号,部门人数,平均工资,最后根据平均工资降序排序
Select deptno,count(*),avg(sal)
From emp
Group by deptno
Having avg(sal)>2000
Order by avg(sal) desc;9.查询emp表中工资在1000~3000之间的员工,每个部门的编号,工资总和,过滤掉平均工资低于2000的部门按照平均工资升序排序
SELECT deptno,SUM(sal)
FROM emp
WHERE sal BETWEEN 1000 AND 3000
GROUP BY deptno
HAVING AVG(sal)<2000
ORDER BY AVG(sal) ASC;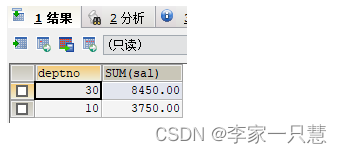
11.子查询(嵌套查询)

1.查询emp表中工资最高的员工信息
#---获取最高工资
select max(sal)
from emp;
#---基于最高工资查询员工信息
select *
from emp
where sal=(select max(sal)
from emp)2.查询emp表中工资超过平均工资的所有员工
#---获取平均工资
select svg(sal) from emp
#---基于平均工资查询员工信息
select * from emp where sal>(select svg(sal) from emp)3.查寻工资高于20号部门平均工资的员工信息
#---获取20号部门的平均工资
select avg(sal) from emp where deptno=20
#---基于平均工资查询员工信息
select* from emp where sal>(select avg(sal) from emp where deptno=20)4.查询和Jones相同工作的其他员工信息
#---查询jones的工作
select job from emp where ename='jones'
#---基于jones的工作查询员工信息
select * from emp where job=(select job from emp where ename='jones') and ename!='jones'5.查询工资最低的员工相同部门的员工信息
#---获取最低工资
select min(sal) from emp
#---基于最低工资获取部门编号
select deptno from emp where sal=(select min(sal) from emp)
#---基于部门编号查询员工信息
select *
from emp
where deptno=(select deptno from emp where sal=(select min(sal) from emp))6.查询最后入职的员工信息
select *
from emp
where hiredate=(select max(hiredate) from emp)7.查询姓名为King的部门编号和部门名称
SELECT deptno,dname
FROM dept
WHERE deptno=(SELECT deptno FROM emp WHERE ename='king')注! : 跨表查询
8.查询有商品的分类id和分类名称(有商品 就是在商品表中出现的分类 需要使用 t_item_category表)
#---先从商品表中得到所有的商品id
Select distinct category_id from t_item
#---再从分类表中查询id等于上面结果的分类信息
Select id,name
From t_item_category
Where id in (Select distinct category_id from t_item);9.查寻员工部门信息
Select*
From dept
Where deptno in(select distinct deptno from emp);10.查询平均工资最高的部门信息
#---查询最高平均工资
Select avg(sal) a
From emp
Group by deptno
Order by a desc
Limit0,1
#---通过最高的的平均工资获取部门编号
Select deptno
From emp
Group by deptno
Having avg(sal)=(Select avg(sal) a
From emp
Group by deptno
Order by a desc
Limit0,1)
#---通过部门编号得到部门信息
Select *
from dept
where deptno in( Select deptno From emp Group by deptno
Having avg(sal)=(Select avg(sal) a From emp Group by deptno
Order by a desc Limit0,1
)
)12.关联查询
同时查询多张表的数据称为关联查询
1.查询每一个员工的姓名和对应的部门名称
Select e.ename,d.dname
From emp e,dept d 找对应关系连立 deptno
Where d.deptno=e.deptno2.查寻在纽约工作的所有员工的信息
Select e.*
From emp e,dept d
Where d.deptno=e.deptno and d.loc='new york'13.笛卡尔积
关联查询如果不写关联关系,则查询结果为两张表的乘积,这个乘积称为<笛卡尔积>
笛卡尔积是一种错误的查询结果,工作中切记不要出现
14.等值连接和内连接
-
等值链接
Select * from A,B
Where A.x=B.x and A.age=18;
2.内连接(用的最多)
Select*
From A join B on A.x=B.x
Where A.age=18 
3.查询每个员工的姓名和对相应的部门名称
Select e.ename,d.dname
From emp e join dept d
On e.deptno=d.deptno练习:
1.每个部门的人数,根据人数排序
Select deptno,count(*)
From emp
Group by deptno
Order by count(*) desc
2.每个部门中,每个主管的手下人数
Select deptno, mgr,count(*)
From emp
Where mgr is not null
Group by deptno,mgr
3.每种工作的平均工资
Select job,avg(sal)
From emp
Group by job
4.每年的入职人数
Select extract(year from hiredate) year,count(*)
From emp
Group by year
5.少于等于3个人的部门信息
--先得到部门人数
Select deptno,count(*) From emp Group by deptno Having count(*)<=3
---子查询
select*from dept where deptno in(Select deptno,count(*) From emp Group by deptno
Having count(*)<=3)
---内连接
Select d.*
From emp e join dept d
On e.deptno=d.deptno
Group by e.deptno
Having count(*)<=315. union操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
UNION语法
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
UNION ALL 语法:
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;演示数据UNION
下面是选自 "Websites" 表的数据:
mysql> SELECT * FROM Websites; +----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | | 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND | +----+---------------+---------------------------+-------+---------+
下面是 "apps" APP 的数据:
mysql> SELECT * FROM apps; +----+------------+-------------------------+---------+ | id | app_name | url | country | +----+------------+-------------------------+---------+ | 1 | QQ APP | http://im.qq.com/ | CN | | 2 | 微博 APP | http://weibo.com/ | CN | | 3 | 淘宝 APP | https://www.taobao.com/ | CN | +----+------------+-------------------------+---------+ 3 rows in set (0.00 sec)
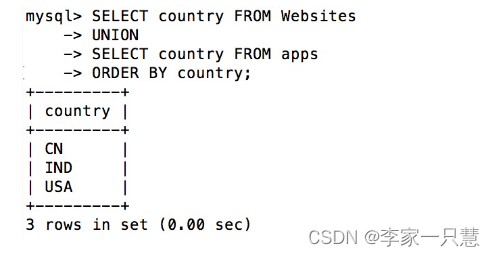
举例下面的 SQL 语句从 "Websites" 和 "apps" 表中选取所有不同的country(只有不同的值):
SELECT country FROM Websites
UNION
SELECT country FROM apps
ORDER BY country;执行以上 SQL 输出结果如下:
带有where的union all
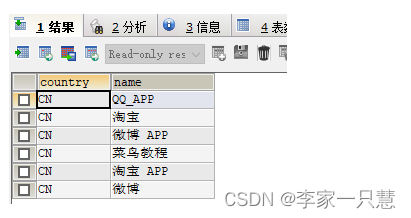
下面的 SQL 语句使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的中国(CN)的数据(也有重复的值)
SELECT country, name FROM Websites
WHERE country='CN'
UNION ALL
SELECT country, app_name FROM apps
WHERE country='CN'
ORDER BY country;执行以上 SQL 输出结果如下:
16.外连接
左外连接:以join左边表为主表显示所有数据右边交集数据

Select e.ename,d.dname
From emp e left join dept d
On e.deptno=d.deptno;
右外连接:以join右边为主表显示所有数据左边交集数据

Select e.*,d.dname
From emp e right join dept d
On e.deptno=d.deptno

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









