






 本文介绍了数据库的基本概念,包括实体-联系图(E-R图)、事务控制语言(TCL)、数据导入导出方法、解决笛卡尔积效应的策略、索引的使用及优劣分析、事务的四大特性(ACID)、三大范式等内容。
本文介绍了数据库的基本概念,包括实体-联系图(E-R图)、事务控制语言(TCL)、数据导入导出方法、解决笛卡尔积效应的策略、索引的使用及优劣分析、事务的四大特性(ACID)、三大范式等内容。
目录
数据库
E-R图
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法。是通过图形描述实体集、实体属性和实体集之间联系的图形。
**长方形:表示实体。**实体是客观存在的事物。例如用户、商品、订单、供应商等。
**椭圆形:表示属性。**举例子:用户实体拥有属性【id、姓名、年龄、电话、身份证号】、商品实体拥有属性【id、商品名称、商品类型、商品价格、商品图片、商品描述、供应商名称】
菱形:表示关系。
**双实线长方形:表示弱实体。**如果一个实体依赖于某个实体而存在,那么前者是弱实体,后者为强实体。
**双实线椭圆形:表示多值属性。**例如一个用户可能拥有多个电话号码,所以电话号码可以作为多值属性。一个用户只能拥有一个身份证号码,所以身份证号不能作为多值属性。
**虚线椭圆形:表示派生属性。**例如一个用户的年龄我们可以作为派生属性,为什么?因为它可以通过身份证号推导出来。所以需要注意的是能推导出来的属性我们都可以作为派生属性。
**双实线菱形:表示弱关系。**弱关系一般是和弱实体一起使用的,只有弱实体才会用到弱关系。
单竖线倒三角形:表示概化。
双竖线倒三角形:表示全部概化。
作为主键的属性在文字下面加下划线

TCL
TCL事务控制语句,用于控制事务。主要的语句关键字有:commit、rollback、savepoint、set transaction。
Commit:用于提交事务。
Rollback:用于事务的回滚操作。
Savepoint:为回退而存在,个数没有限制,与虚拟机中快照类似。savepoint是事务中的一点。用于取消部分事务,当结束事务时,会自动的删除该事务中所定义的所有保存点。
Set transaction:设置事务的各种状态,比如只读、读/写、隔离级别。
数据导入导出MySQL
导出
mysqldump -h IP地址 -P 端口 -u 用户名 -p 数据库名 > 导出的文件名
导入
常用source 命令,进入mysql数据库控制台,
如mysql -u root -p
use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
source /wcnc_db.sql
文件路径: 注意!!!!路径中不要有中文!!!
笛卡尔积效应
笛卡尔积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
解决方法
- 去重 distinct
- 加条件过滤。 避免了笛卡尔积现象不会减少记录的匹配次数,匹配次数还是那么多只是对显示结果进行了过滤,只显示有效记录。
- 换另外一个具有唯一性的字段,得到正确内连接查询结果。
- 外连接。
索引
索引是帮助MySQL高效获取数据的数据结构。
索引的优势和劣势
可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些。
如果按照索引列的顺序进行排序,对应order by语句来说,效率就会提高很多。
索引会占据磁盘空间
索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
索引类型
索引列中的值必须是唯一的,不允许有空值。
MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值。
索引列中的值必须是唯一的,但是允许为空值。
只能在文本类型CHAR,VARCHAR,TEXT类型字段上创建全文索引。字段长度比较大时,如果创建普通索引,在进行like模糊查询时效率比较低,这时可以创建全文索引。 MyISAM和InnoDB中都可以使用全文索引。
在文本类型如CHAR,VARCHAR,TEXT类列上创建索引时,可以指定索引列的长度,但是数值类型不能指定。
-
单列索引
-
组合索引
组合索引的使用,需要遵循最左前缀匹配原则(最左匹配原则)。一般情况下在条件允许的情况下使用组合索引替代多个单列索引使用。
结构
缺点:顺序插入时,会形成一个链表,查询性能大大降低。大数据量情况下,层级较深,索引速度慢。
红黑树:大数据量情况下,层级较深,检索速度慢。
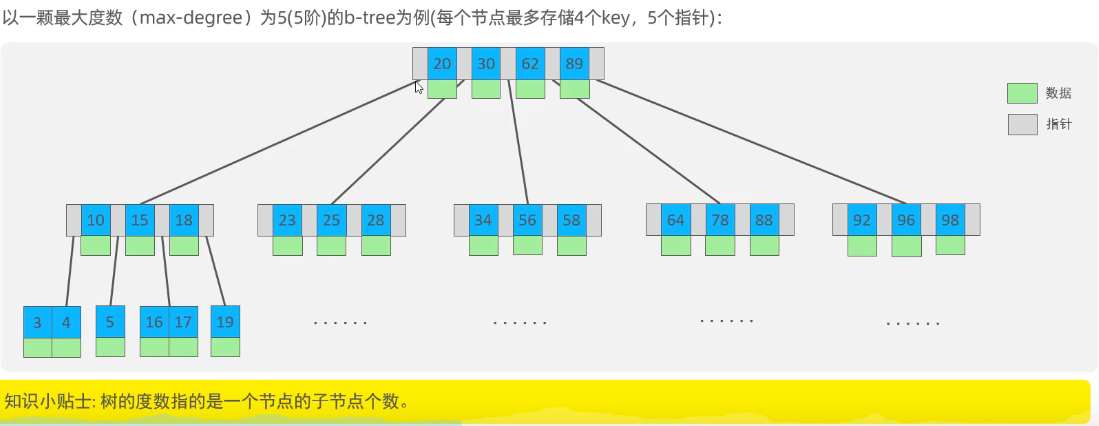
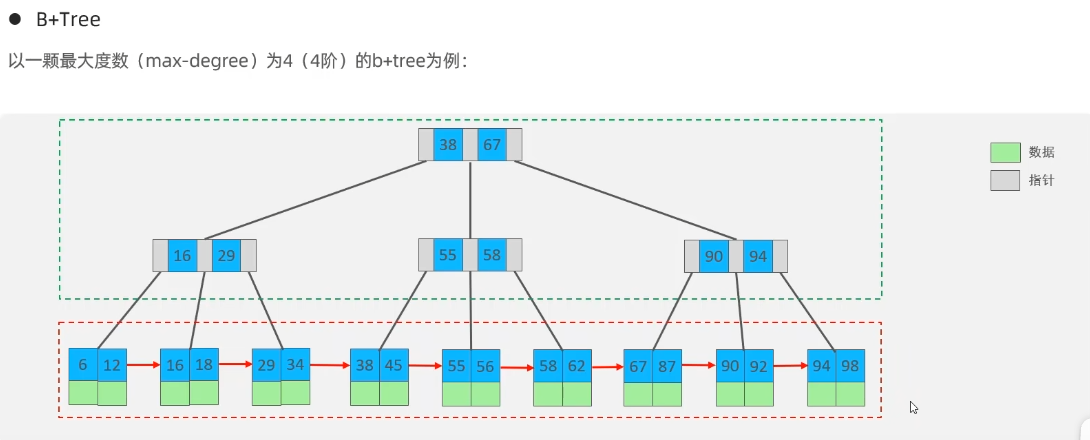
相对于B-Tree区别:
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表
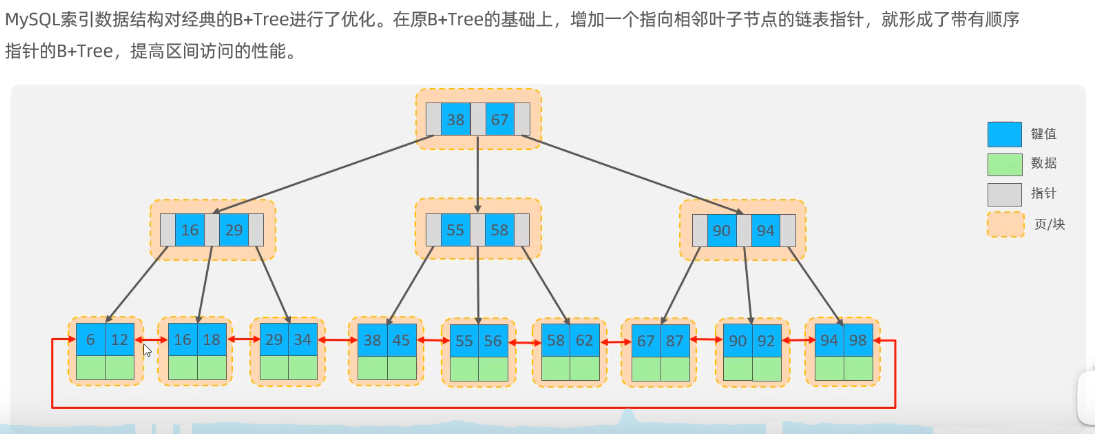
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到相应的槽位上,然后存储在hash表中。
如果两个或多个键值,映射到一个相同的槽位上,他们就产生了HASH冲突,可以通过链表解决。
-
Hash索引只能用于对等比较(=, in),不支持范围查询(between, >, <, …)
-
无法利用索引完成排序操作
-
查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree索引
事务
事务是一组操作的集合
四大特性(ACID)
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性: 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性: 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性: 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务操作
select @@autocommit;
set @@autocommit=0; //设置为手动提交
commit;
rollback;
事务并发异常
脏读:脏读指一个事务访问到了另一个事务未提交的数据
不可重复读:不可重复读指一个事务多次读取同一数据的过程中,数据值 内容 发生了改变,导致没有办法读到相同的值,描述的是针对同一条数据 update/delete 的现象
幻读:幻读指一个事务多次读取同一数据的过程中,全局数据(如数据行数)发生了改变,仿佛产生了幻觉,描述的是针对全表 insert/delete 的现象
三大范式
第一范式(1NF):每个列都不可以再拆分。
第二范式(2NF):在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式(3NF):在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
sql语句书写、执行顺序
执行顺序
-
from 阶段
-
where 阶段
-
group by 阶段
-
having 阶段
-
select 阶段
-
order by 阶段
-
limit 阶段
书写顺序和执行顺序表格
Javaweb
cookie作用
类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据
由于HTTP协议是无状态协议,如果你在同一个客户端向服务器发送多次请求,服务器不会知道这些请求来自同一客户端(同一个用户)。 而Cookie则解决了这个问题。
Cookie就是一些数据,用于存储服务器返回给客服端的信息,客户端进行保存。在下一次访问该网站时,客户端会将保存的cookie一同发给服务器,服务器再利用cookie进行一些操作。利用cookie我们就可以实现自动登录,保存游览历史,身份验证等功能。

请求数据
三部分
- 请求行:请求数据的第一行。其中GET表示请求方式,/ 表示请求资源路径,HTTP/1.1表示请求协议版本
- 请求头:第二行开始,格式为key:value形式。
- 请求体:POST请求的最后一部分,存放请求参数
HTTP
超文本传输协议,规定了浏览器和服务器之间的数据传输规则。
特点
- 基于TCP协议:面向连接,安全
- 基于请求-响应模型的:一次请求对应一次响应
- HTTP协议是无状态的协议:对于事务处理没有记忆。每次请求响应都是独立的。
- 缺点:多次请求之间不能共享数据。
- 优点:速度快。
GET请求和POST请求区别
- GET请求请求参数再请求行中,没有请求体。POST请求的请求参数在请求体中。
- GET请求请求参数大小有限制,POST没有限制
DTO
DTO即数据传输对象。
我们原来的user类,面向Model。如果前端只需要显示用户名,那我们不应该传递密码等敏感数据,应该定义面向UI的DTO,而且当我们业务更改,后端model层新加属性 比如address等,不需要更改面向UI的DTO 实现了一定解耦,于是我们使用DTO。
好处
- 实现了一定视图层和Model层解耦
- 可以防止敏感信息泄露
- 如果使用session 存取较少的数据可以节省内存空间


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









