






以上掌握了Python的数据类型、语句和函数,基本上就可以编写出很多有用的程序了。但是在Python中,代码不是越多越好,而是越少越好。代码不是越复杂越好,而是越简单越好。
基于这一思想,我们来介绍Python中非常有用的高级特性,1行代码能实现的功能,决不写5行代码。请始终牢记,代码越少,开发效率越高。
文:https://www.liaoxuefeng.com/
主要包括以下高级特性:
切片:有了切片操作,很多地方循环就不再需要了;
迭代:只要是可迭代对象,无论有无下标,都可以迭代;
列表生成式:快速生成list;
生成器:generator是非常强大的工具,可以简单地把列表生成式改成generator,也可以通过函数实现复杂逻辑的generator。
迭代器
切 片
取一个list或tuple的部分元素是非常常见的操作。比如,一个list如下:

取前3个元素,应该怎么做?
笨办法:
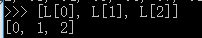
之所以是笨办法是因为扩展一下,取前N个元素就没辙了。
取前N个元素,也就是索引为0-(N-1)的元素,可以用循环:
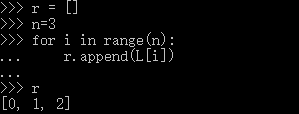
对这种经常取指定索引范围的操作,用循环十分繁琐,因此,Python提供了切片(Slice)操作符,能大大简化这种操作。
对应上面的问题,取前3个元素,用一行代码就可以完成切片:
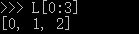
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
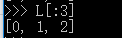
类似的,既然Python支持L[-1]取倒数第一个元素,那么它同样支持倒数切片,试试:
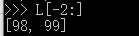
记住倒数第一个元素的索引是-1。
前10个数,每两个取一个:
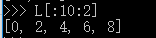
所有数,每5个取一个:
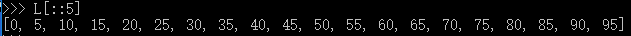
甚至什么都不写,只写[:]就可以原样复制一个list:
L[:]tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple:
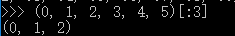
在很多编程语言中,针对字符串提供了很多各种截取函数(例如,substring),其实目的就是对字符串切片。Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
有了切片操作,很多地方循环就不再需要了。Python的切片非常灵活,一行代码就可以实现很多行循环才能完成的操作。
迭 代
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
在Python中,迭代是通过for ... in来完成的,而很多语言比如C语言,迭代list是通过下标完成的,比如Java代码:

可以看出,Python的for循环抽象程度要高于C的for循环,因为Python的for循环不仅可以用在list或tuple上,还可以作用在其他可迭代对象上。
list这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:
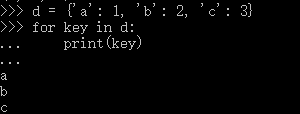
因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不一样。
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
由于字符串也是可迭代对象,因此,也可以作用于for循环:
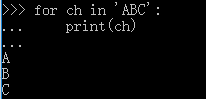
所以,当我们使用for循环时,只要作用于一个可迭代对象,for循环就可以正常运行,而我们不太关心该对象究竟是list还是其他数据类型。
那么,如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:

最后一个小问题,如果要对list实现类似Java那样的下标循环怎么办?Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:

上面的for循环里,同时引用了两个变量,在Python里是很常见的,比如下面的代码:

任何可迭代对象都可以作用于for循环,包括我们自定义的数据类型,只要符合迭代条件,就可以使用for循环。
列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
举个例子,要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11)):
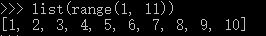
但如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?方法一是循环:

但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
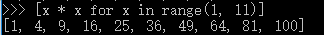
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来,十分有用,多写几次,很快就可以熟悉这种语法。
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:

还可以使用两层循环,可以生成全排列:
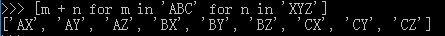
三层和三层以上的循环就很少用到了。
运用列表生成式,可以写出非常简洁的代码。例如,列出当前目录下的所有文件和目录名,可以通过一行代码实现:

for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:

因此,列表生成式也可以使用两个变量来生成list:

最后把一个list中所有的字符串变成小写:
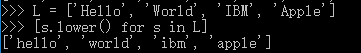
运用列表生成式,可以快速生成list,可以通过一个list推导出另一个list,而代码却十分简洁。
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:

创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
我们讲过,generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
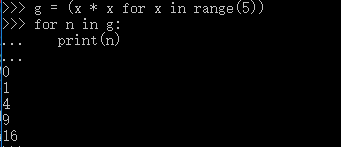
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
定义generator的另一种方法:如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。
最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
generator是非常强大的工具,在Python中,可以简单地把列表生成式改成generator,也可以通过函数实现复杂逻辑的generator。
要理解generator的工作原理,它是在
for循环的过程中不断计算出下一个元素,并在适当的条件结束for循环。对于函数改成的generator来说,遇到return语句或者执行到函数体最后一行语句,就是结束generator的指令,for循环随之结束。请注意区分普通函数和generator函数,普通函数调用直接返回结果:
迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:

而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:

生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:

你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
凡是可作用于
for循环的对象都是Iterable类型;凡是可作用于
next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;集合数据类型如
list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。Python的
for循环本质上就是通过不断调用next()函数实现的。
推荐 | 中文文本标注工具Chinese-Annotator
资源 | 2017年GitHub中Top 30开源机器学习项目
分享 | 由0到1走入Kaggle-入门指导 (长文、干货)
加入Python学习微信交流群
请添加微信:BetaWater
备注:姓名-单位-研究方向
更
多
精
彩
请猛戳右边二维码
公众号ID
BetaWater


















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









