






 文章提出了一种名为CDNet的循环一致的单幅图像去雾生成对抗网络,该网络使用编码器-解码器架构在非配对真实模糊图像数据集上训练,以估计目标级传输图并恢复无雾场景。传统的去雾方法依赖于假设或先验,而CDNet通过对抗训练和光学模型避免了这些问题,减少了颜色失真并在多个数据集上展示了优越的性能。
文章提出了一种名为CDNet的循环一致的单幅图像去雾生成对抗网络,该网络使用编码器-解码器架构在非配对真实模糊图像数据集上训练,以估计目标级传输图并恢复无雾场景。传统的去雾方法依赖于假设或先验,而CDNet通过对抗训练和光学模型避免了这些问题,减少了颜色失真并在多个数据集上展示了优越的性能。
摘要:
在雾霾、雾和烟等气溶胶颗粒存在的情况下,室外场景图像的能见度一般会下降。这是因为气溶胶粒子将物体表面反射的光线散射,从而导致光强衰减。雾霾的效果与场景点的透射系数成反比。因此,准确透射图(TrMap)的估计是重建无雾场景的关键步骤。以前的方法使用各种假设/先验来估计场景TrMap。此外,可用的端到端去雾方法利用监督训练来预测合成生成的成对模糊图像上的TrMap。尽管之前的方法取得了成功,但由于无法获得真实世界的模糊图像对来训练网络,它们在现实世界的极端模糊条件下失败了。因此,本文提出了一种循环一致的单幅图像去雾生成对抗网络CDNet,该网络在真实模糊图像数据集上以非配对方式进行训练。CDNet的生成器网络由编码器-解码器架构组成,该架构旨在估计目标层TrMap,然后是光学模型,以恢复无雾场景。我们在D-HAZY[1]、Imagenet[5]、SOTS[20]和真实图像四个数据集上进行实验。采用结构相似度指标、峰值信噪比和CIEDE2000度量来评价所提出的CDNet的性能。
背景:
在捕获图像时,假设物体表面的反射光在没有强度衰减的情况下传播一段距离到相机设备。因此,图像点的亮度完全取决于场景中单个点的亮度。此外,大多数计算机视觉算法通常要求在清晰的环境中捕获输入图像。然而,气溶胶的存在削弱了场景点的强度,降低了图像质量。因此,气溶胶的存在降低了任何计算机视觉算法的性能(如物体检测、人员再识别等)。因此,单幅图像的雾霾去除是一项非常理想的预处理任务,以提高计算机视觉算法在雾霾环境中的性能。
从图1 (a)中可以看出,雾霾的效果与场景点距离相机设备的深度成正比。由于输入是单幅图像,深度估计或传输图(TrMap)是一个欠约束问题。因此,人们提出了各种方法来从多个图像(如po-)中获取深度如larised filters[31,33],用于融合同一户外场景的多幅图像[24]。为了克服多图像依赖性,通过施加不同的条件来估计单幅图像中的场景深度,提出了各种先验[4,8,34,12,2,35,41,15]。他等人[12]提出了一种强雾相关先验,可以有效地估计传输图。暗通道先验(DChP)假设无雾场景由暗像素组成(在其中一个颜色通道中具有非常低的强度)。DChP在类似大气光和复杂边缘结构的区域失效。现有的雾霾相关先验可以很好地工作,但是在复杂场景(复杂边缘结构)或场景光照不均匀的情况下,这些先验很容易被违背。
在模糊朦胧环境下,单一先验不足以估计出准确的景深信息。为了开发一个更稳健的系统,Tang等[35]提出了一个回归框架来估计深度信息。他们利用已有的雾霾相关先验提取雾霾特征,并学习这些特征的组合来预测雾霾场景的TrMap。尽管这种方法取得了显著的进展,但由于所使用的先验,它将级联误差向上传播。最近,研究人员利用卷积神经网络(CNN)[3,26]来估计TrMap。此外,还提出了一些端到端方法[18,19]来去除单幅图像的雾霾。根据Hinds[14],由于控制这些颗粒的扩散过程,灰尘、水滴和其他气溶胶(霾/雾颗粒)的密度在环境中平滑变化。因此,我们可以期望得到分段平滑的深度(平滑的气溶胶密度)和相应的光滑的TrMap在对应于同一物体的像素处。现有的基于cnn的方法[3,26]无法估计目标级TrMap,并使用引导图像滤波[11]来实现目标级TrMap。
最近,研究人员[39,21,27]利用编码器-解码器架构估计图像去雾的TrMap。然而,这些网络需要配对数据,即模糊输入图像和相应的地面真值训练网络参数,用于估计传输图。
这些网络是在合成雾霾数据上训练的,这是不可信的,因为合成雾霾并没有结合现实世界中真实的雾霾分布。训练任何CNN架构的一个主要障碍是真实训练数据的可用性和准确的地面真值。而在天气退化图像分析领域中,想要收集到一对具有相应干净图像的天气退化图像是极不可能的。因此,一种有效实用的去雾架构应该能够在不进行配对训练的情况下恢复去雾场景。此外,任何图像去雾算法的部分目标都是了解场景中的雾霾分布。我们认为,要学习雾霾的扩散,并不需要使用配对图像来训练系统。因此,在本文中,我们使用非配对图像训练方法[40]来训练用于估计目标级TrMap的网络参数。图2显示了提出的单幅图像去雾的非配对训练方法。
为了预测对象级别的TrMap,我们在生成器网络中使用了编码器-解码器(ED)[28]架构的概念。ED架构在医学图像分割中显示出良好的效果,并被广泛用于估计语义信息[9]。
本文提出的单幅图像去霾方法的主要贡献有:1.提出了用编码器-解码器网络估计对象级传输映射的方法。2. 我们提出了循环一致生成对抗网络CDNet,该网络包括对未配对图像数据进行对抗训练以估计传输图,然后进行光学模型以恢复无雾场景。
我们在D-HAZY[1]、Imagenet[5]、SOTS[20]和真实图像四个数据集上进行实验。
CycleGAN在生成器模块中使用了残差块,并被证明(在[40]中)可以有效地进行干净图像(无雾霾)的风格转移。然而,当我们尝试将相同的网络用于除雾任务时,发现很难在不失真的情况下恢复无雾的场景信息。这可能是因为雾霾的加入降低了图像的质量,这使得学习任务变得更加困难,这与风格迁移不同。在我们的实验中,我们使用光学模型来恢复无雾场景。我们发现这种方法有利于消除颜色失真,而不是要求网络直接输出无雾图像。
因此,受[40]的启发,我们提出了循环一致生成对抗网络(CDNet)来预测鲁棒传输图,然后使用光学模型来恢复无雾霾场景。尽管我们与CycleGAN共享类似的训练过程,但我们为CDNet生成器设计了一个编码器-解码器架构,而不是残差块。图4显示了提议的CDNet的生成器网络。网络架构和参数细节将在第3节中讨论。
模型架构:
在本文中,我们使用Zhu等[40]提出的非配对训练方法CycleGAN来学习雾霾场景的传输图。CycleGAN是一种端到端架构,最初是为图像到图像样式传输应用程序提出的。为了实现非配对训练,他们提出了循环损失。图3显示了使用CycleGAN恢复的无雾图像的颜色失真。这背后的原因是,风格迁移任务[40](具有无雾输入)是一个约束模型,旨在预测三个未知因素,即目标风格的R, G, B颜色强度。然而,在一个朦胧的场景中,一个额外的成分,即雾霾,使得一个约束下的模型来学习干净和朦胧图像之间的映射。另一方面,光学模型是利用模糊场景及其估计的透射图来恢复无模糊场景的良好模型。许多研究者使用光学模型来恢复无雾场景[34,12,2,35,41,15,3,26]。
光学模型成功的原因是,它描述了模糊图像的形成过程。因此,我们可以按照相反的过程很容易地得到一个没有雾霾的场景。
虽然是两步的方法,但它恢复了没有颜色失真的无雾场景,并且它给出了深度信息(因为传输通道和场景物体的深度成反比),可以用于机器人视觉等高级任务。
因此,在本文中,我们采用了unpaired training方法[40],先对雾霾场景的TrMap进行估计,然后利用光学模型恢复无雾场景。
我们提出了一种具有跳跃连接的编码器-解码器(ED)架构作为所提出的CDNet的生成网络。ED架构广泛应用于医学图像分割任务[28,23]。编码器网络的作用是通过保持对象的结构信息,从输入图像中获得抽象的特征映射。另一方面,解码器网络旨在从编码器网络获得的低分辨率目标显著性图中再现高分辨率特征图。我们利用ED体系结构的这些属性来获得精细化的传输图(对象级)。
本文尝试用ED体系结构获得对象级传输图。针对发电网络,设计了以预测对象级传输信道信息为目标的动态规划体系结构。图4描述了拟议CDNet的生成器网络。
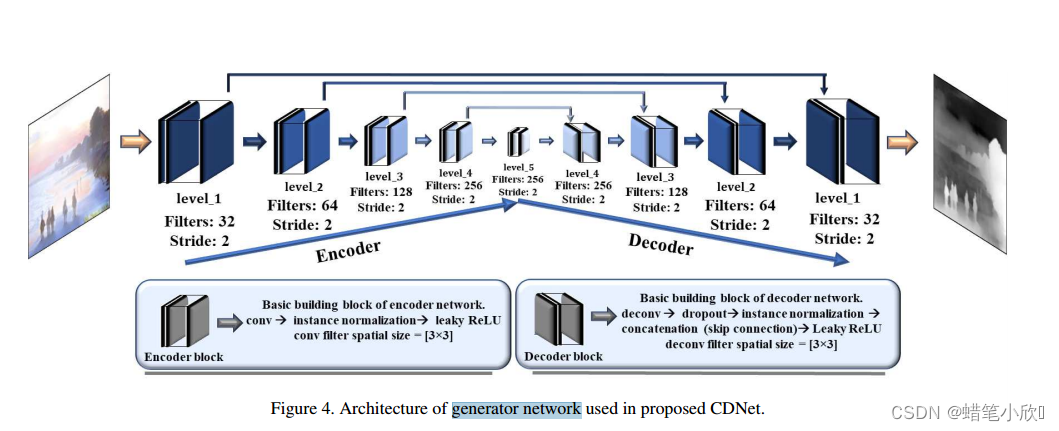
它由五个编码器块和五个解码器块组成。每个编码器块由{卷积层⇒实例归一化⇒泄漏ReLU}组成。每个解码器块由{反卷积层⇒退出层⇒实例归一化层⇒连接层(跳过连接)⇒leakyReLU}组成。ED架构中的空间滤波器尺寸是恒定的,在整个网络中为3 × 3。在每个编码器块上,卷积层设计为步长2。
这里,步幅为2的卷积层消除了池化层的要求。另一方面,解码器架构由类似的设置组成,例如3 × 3反卷积滤波器,上采样因子为2。为了避免过拟合,我们使用dropout rate = 0.5的drop-out layer。泄漏ReLU层的泄漏系数= 0.2。同样,与[36,40]类似,我们使用实例归一化对卷积层的特征映射进行归一化。对于鉴别器网络,我们采用了CycleGAN的架构,因为它在图像到图像的风格传递任务上表现出了令人印象深刻的效果。图5显示了使用建议的CDNet和现有的最先进的方法估计的传输图。从图5中可以看出,提出的CDNet估计了目标级传输图(见标记区域,以便清晰理解)。
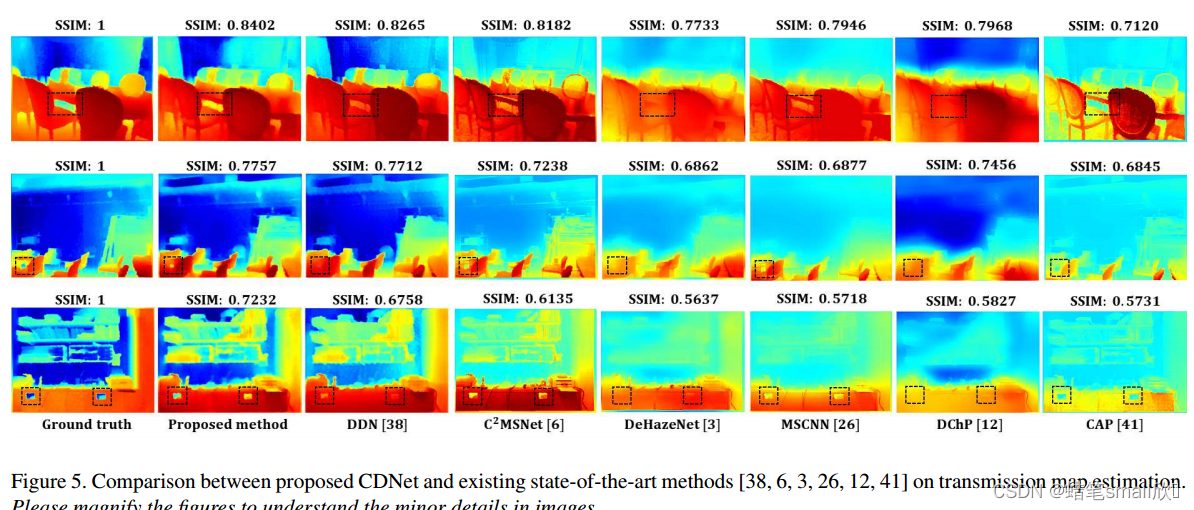
图2显示了用于训练CDNet去除单幅图像雾霾的非配对训练方法。如图2所示,CDNet包括两个映射:(1)正向映射,即从朦胧到清洁;(2)反向映射,即从清洁到朦胧。生成器网络由编码器-解码器网络组成,该网络对TrMap进行估计,然后通过光学模型恢复无雾场景1。模型的其余设置与[40]相似。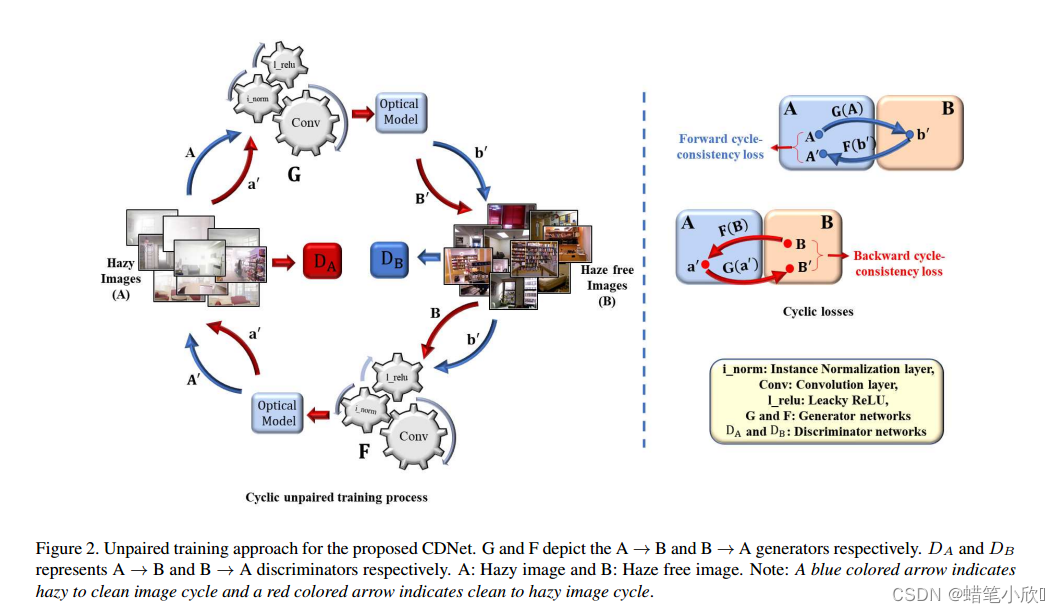
结果分析:
从图6 (b)中可以看出,CDNet恢复了没有任何颜色失真的无雾场景。图6 (b)的另一个观察结果是,基于光学模型的方法(CDNet和DDN)恢复了写入标记区域的文本(NYU)。然而,CycleGAN[40]和CycleDehaze[7]的端到端方法无法恢复相似的文本。与其他现有方法相比,图6 (b)中标记区域的目标边界更加清晰。
从图6中可以看出,尽管所有方法都不能完全去除霾,但本文提出的方法仍然比其他现有方法保持其地位。我们将此归功于所提出的利用光学模型去除单幅图像雾霾的方法。

图7 (c, d)显示了端到端方法(CycleGAN[40]和CycleDehaze[7])造成的色彩失真,无法恢复感知上令人愉悦的无雾霾场景。定性分析表明,所提出的CDNet优于现有的单幅图像雾霾去除方法。
总结:
在这项工作中,我们使用非配对训练方法(CycleGAN)解决了卷积神经网络训练中无法获得成对自然模糊图像的问题。此外,使用基于光学模型的方法解决了现有端到端去雾架构中的颜色失真问题。与现有的端到端方法相比,我们提出了周期一致的生成器
[40] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In 2017 IEEE International Conference on Computer
Vision (ICCV), pages 2242–2251. IEEE, 2017.
注释:
(一)
在深度学习中,"filters"(滤波器)和"stride"(步幅)是与卷积神经网络(Convolutional Neural Networks,CNNs)中卷积操作相关的概念。
1. Filters(滤波器):
- Filters 是卷积神经网络中的一种参数,用于对输入图像或特征图进行特征提取。
- 滤波器可以看作是一个小的矩阵或卷积核,其权重值用于对输入数据进行加权求和。
- 在卷积操作中,滤波器通过滑动窗口的方式在输入图像上移动,并与图像中的局部区域进行卷积运算。
- 每个滤波器可以捕捉不同的特征,如边缘、纹理或形状等。在卷积层中,通常会使用多个滤波器来提取不同的特征。
2. Stride(步幅):
- Stride 是卷积操作中的一个参数,指定了滤波器在输入图像上移动的步长。
- 步幅决定了每次滤波器移动的距离,可以是水平方向和垂直方向上的步长。
- 当步幅为1时,滤波器逐个像素地在输入图像上移动;当步幅大于1时,滤波器会跳过一些像素。
- 通过调整步幅,可以改变输出特征图的尺寸。较小的步幅可以保留更多的空间信息,而较大的步幅可以减小特征图的尺寸。
综上所述,Filters(滤波器)用于卷积操作中对输入数据进行特征提取,Stride(步幅)用于指定滤波器在输入图像上的移动步长。这些参数在卷积神经网络中的设计和调整,可以影响网络对图像特征的感知和提取能力,进而影响网络的性能和输出结果。
(二)
Leaky ReLU(带泄漏的线性整流单元)是神经网络中常用的激活函数,尤其在深度学习模型中应用广泛。它是传统ReLU激活函数的扩展。
在标准的ReLU函数中,对于所有负输入值,输出为0,对于所有正输入值,输出为输入值本身。然而,Leaky ReLU在负值上引入了一个小斜率,而不是将其设为零。这种对负输入的非零斜率允许激活函数具有较小的梯度,并解决了“ReLU死亡”问题。
Leaky ReLU函数的数学表示为:
f(x) = { x, 如果 x ≥ 0,
αx, 如果 x < 0 }
这里,α是一个小常数,通常设置为一个小的正值,例如0.01。负斜率(αx)确保网络中的神经元对负输入不完全处于非活动状态,并在反向传播期间允许一些梯度流动,有助于学习和避免死亡神经元。
Leaky ReLU相对于传统ReLU的主要优点是它防止神经元完全失效,并解决了死亡神经元的问题。研究发现,Leaky ReLU可以通过允许更强大和稳定的梯度流动来改善深度神经网络的性能。
总体而言,Leaky ReLU是一个受欢迎的激活函数选择,特别适用于处理深度神经网络,有助于缓解标准ReLU激活函数的某些局限性。
(三)
实例归一化层(Instance Normalization)是一种常用的归一化技术,用于神经网络模型中的图像处理任务。它是一种归一化输入特征图的方法,旨在提高模型的训练和泛化性能。
与批归一化(Batch Normalization)不同,实例归一化是对单个样本或特征图进行归一化,而不是对整个批次的样本进行归一化。实例归一化的主要思想是将每个样本(或特征图中的每个像素位置)独立地进行归一化,以减少特征之间的相关性,从而提供更好的特征表达和更稳定的训练过程。
在实例归一化中,对于每个特征图,归一化是通过计算每个样本在通道维度上的均值和方差来完成的。具体而言,对于一个具有C个通道的特征图,对于每个样本x,实例归一化的计算步骤如下:
1. 对于每个通道c,计算样本x在通道c上的均值μ(x_c)和方差σ(x_c)。
2. 使用计算得到的均值和方差对样本x在通道c上进行归一化,即:
y_c = (x_c - μ(x_c)) / σ(x_c)
3. 可选地,引入可学习的缩放因子和偏移量,以允许网络自行调整归一化后的特征:
y_c = γ * y_c + β
其中,γ和β是可学习的参数。
实例归一化在图像生成、图像超分辨率、图像风格迁移等任务中被广泛使用。它有助于提高模型的训练速度、稳定性和泛化性能,并且通常被认为比批归一化更适合于生成模型和样式转换任务。

















 8139
8139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









