







前言
本期主要将 thread cache、central cache、page cache 三层申请内存的过程进行联调一遍,让申请的逻辑走通!
ConcurrentAlloc函数
将thread cache、central cache以及page cache的申请流程写通了之后,我们可以向外面提供一个ConcurrentAlloc的接口函数,用于供线程获取内存对象。每个线程第一次调用该函数时会先通过TLS获取自己专属的 thread cache,后面每个线程都会去他自己的thread cache 中获取对象。
static void* ConcurrentAlloc(size_t size)
{
// 第一次调用时,通过 TLS 让每个线程获取自己专属的 thread cache 对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
// 到自己的thread cache 获取内存对象
return pTLSThreadCache->Allocate(size);
}我们上期有一个地方有问题,忘了没说:我们在page cache申请NPAGES-1页的大块内存时,使用的是当时在 定长内存池的 SystemAlloc 函数,因为我们这是在Win平台,所以条件编译会把 Windows.h 放出来,这就会导致 慢返回调节算法那里的 std::min有问题。
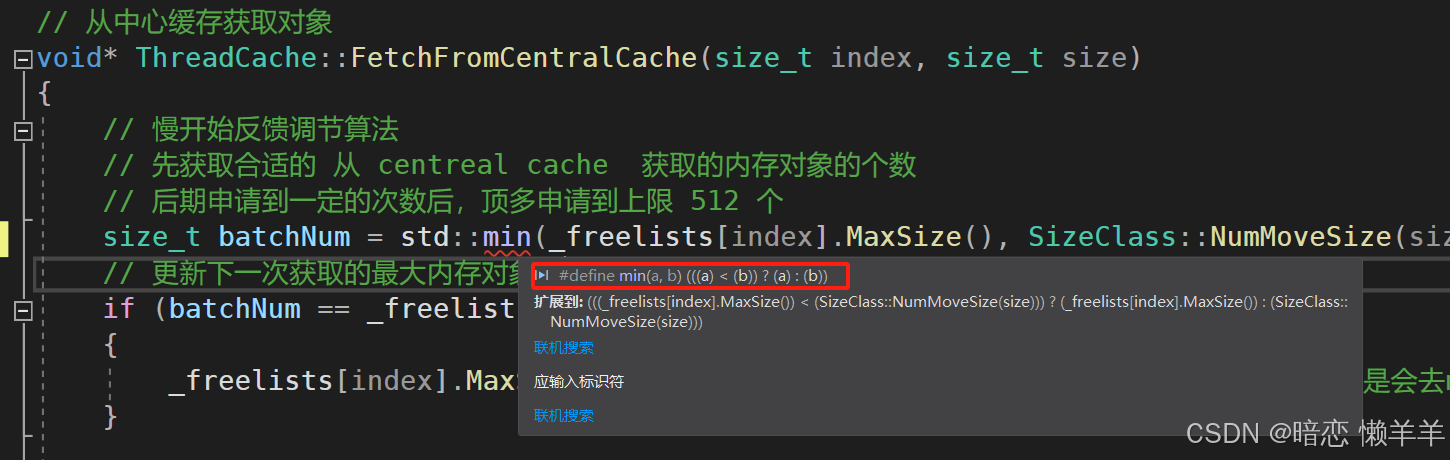
原因是 :在C++的algorithm头文件中有一个min函数,这是一个函数模板,而在Windows.h头文件中也有一个min,这是一个宏。由于调用函数模板时需要进行参数类型的推演,因此当我们调用min函数时,编译器会优先匹配Windows.h当中以宏的形式实现的min,此时当我们以std::min的形式调用min函数时就会产生报错,这就是没有用命名空间进行封装的坏处,这时我们只能选择将std::去掉,让编译器调用Windows.h当中的min。
申请内存过程联调(一)
由于在多线程环境下每个线程的时间片是不可控的,直接以上来就用多线程调试就会很麻烦。所以我们这里先使用主线程来调试,先看看在单线程的情况下代码的执行逻辑是否符合我们的预期,其次我们这里只需要简单的观察任意一个桶就可以了。这里就选择观察第一个桶!
下面主线程进行三次内存的申请,他们最终都会对其到8字节也就是0号桶
void TestConcurrentAlloc1()
{
void* p1 = ConcurrentAlloc(6);
void* p2 = ConcurrentAlloc(8);
void* p3 = ConcurrentAlloc(1);
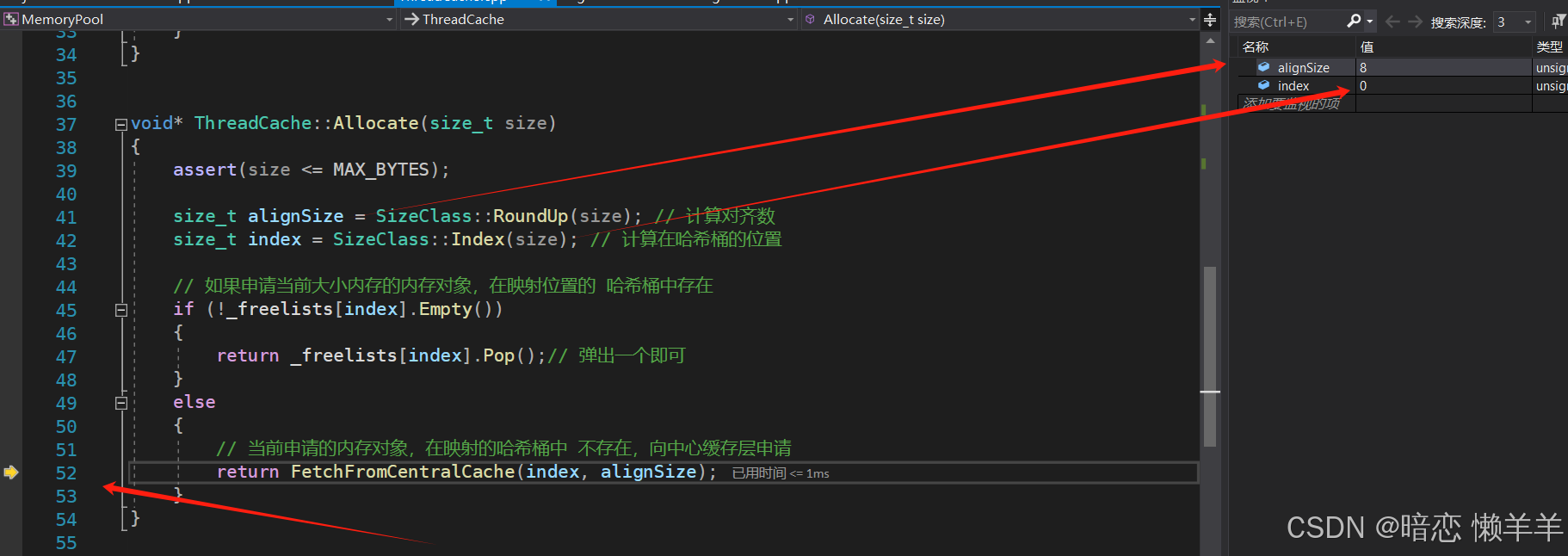
}当线程第一次申请内存的时候,该线程需要通过 TLS 创还能自己的thread cache 对象,然后通过这个thread cache 进行内存对象的申请。
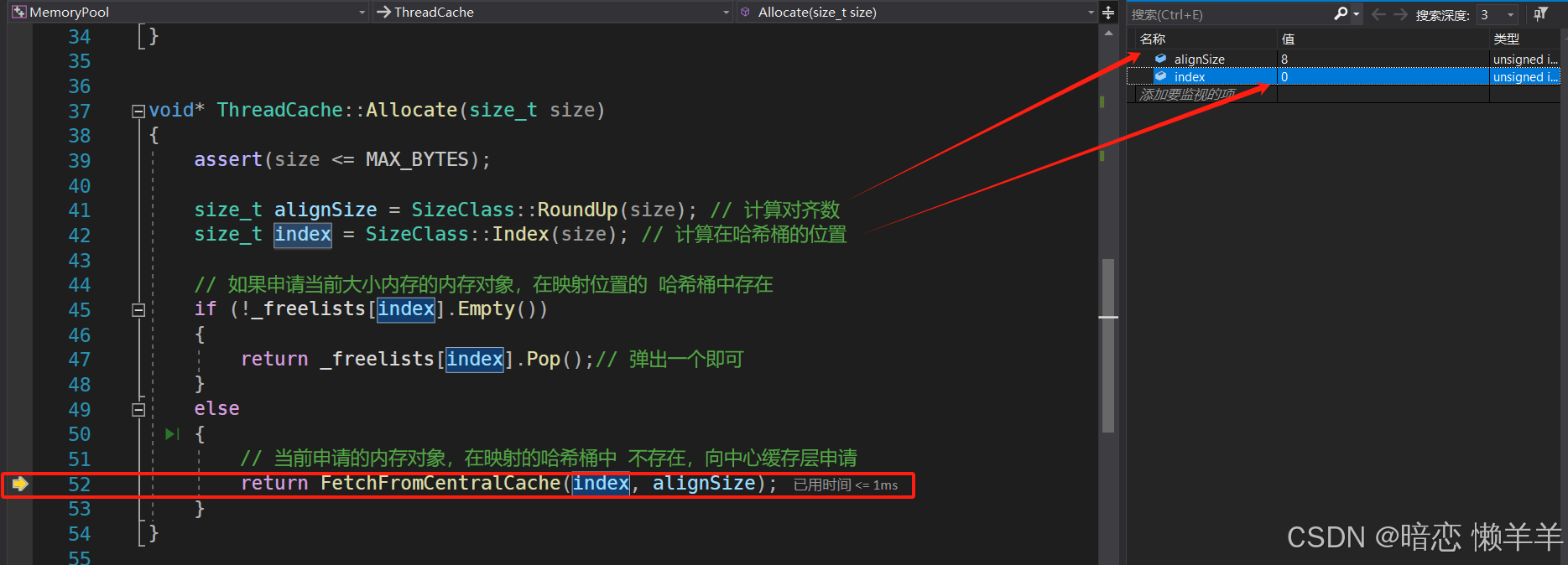
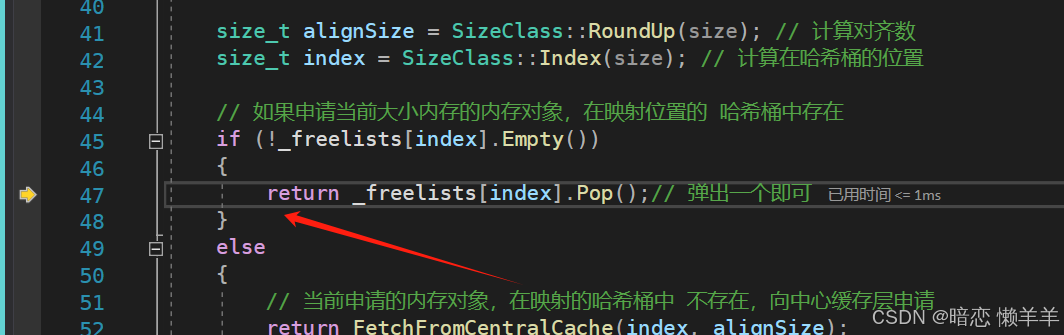
然后根据thread cache 对象去申请size大小的对象,这里会根据内存对齐规则对齐到8字节,并会映射到thread cache 的0号桶。因为第一次thread cache 的 0号桶中是空的,所以此时就需要
去central cache 中对应的桶去申请了。
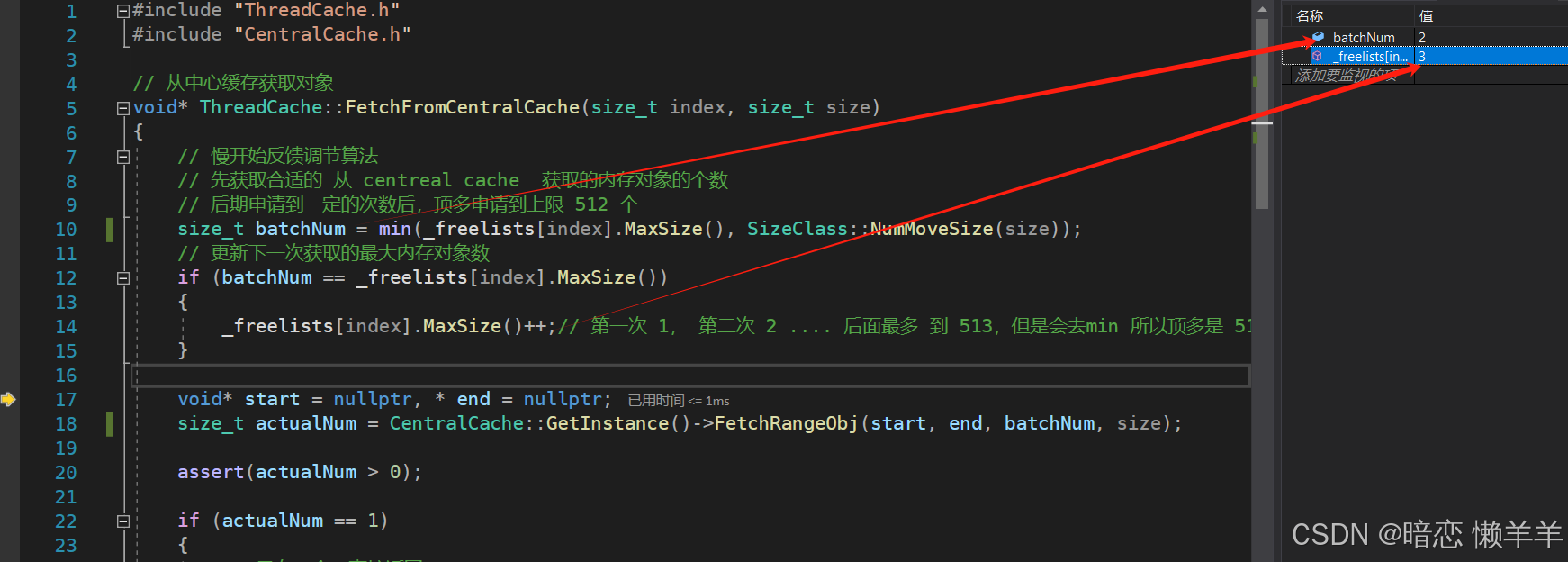
在向central cache申请内存块前,首先通过NumMoveSize函数计算得出,thread cache一次最多可向central cache申请8字节大小对象的个数是512,但由于我们采用的是慢开始算法,所以还需要将上限值512与自由链表中的_maxSize 比较,由于是第一次 _maxSize是1,所以最终像central cache申请的内存个数就是 1个
完成之后,会将自由链表中的_maxSize 自增 1,也就是下次向 central cache申请时,就会申请2个
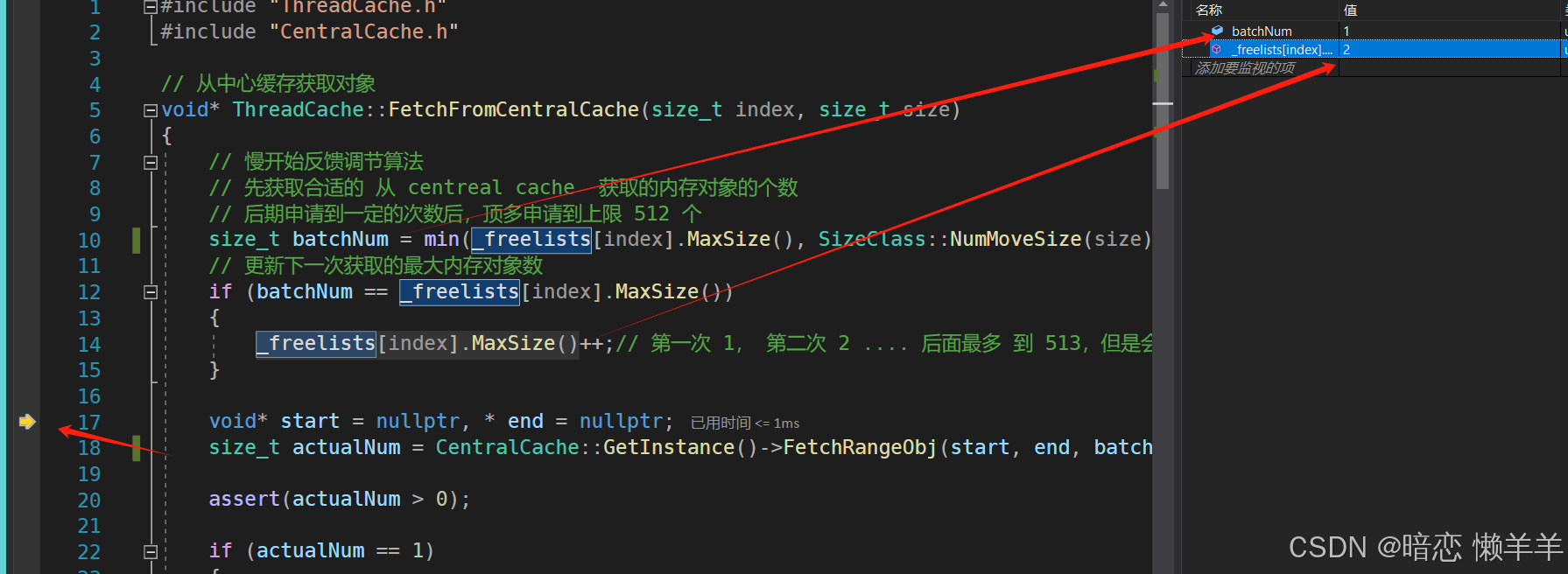
在thread cache向central cache 获取对象之前,为了避免出现线程安全问题,需要先对central cache对应的哈希桶位置进行加 桶锁,这里就是对 0 号桶加锁。
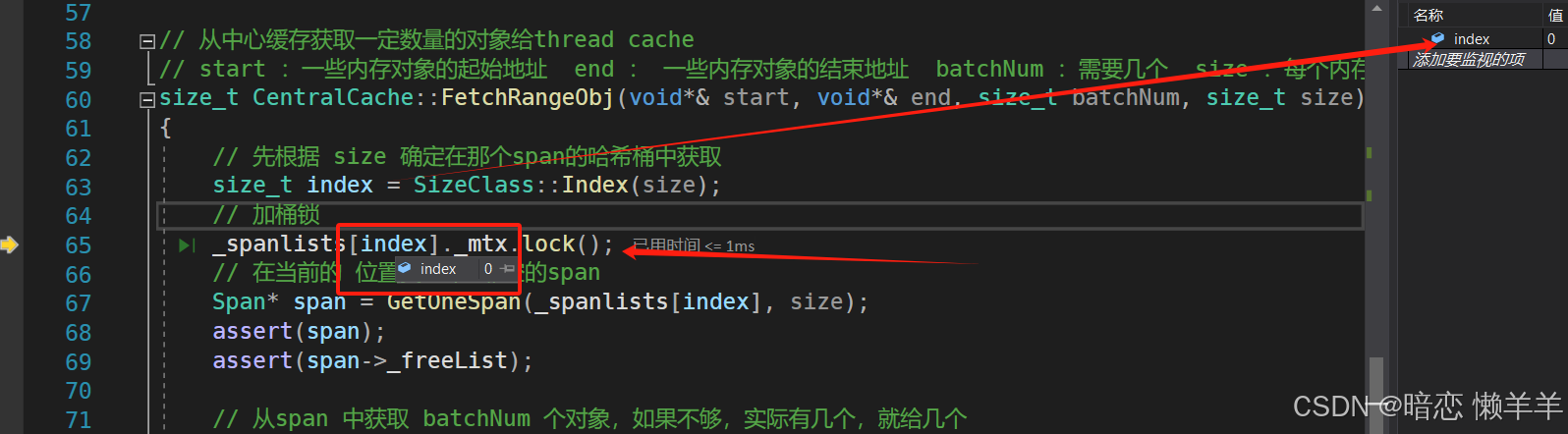
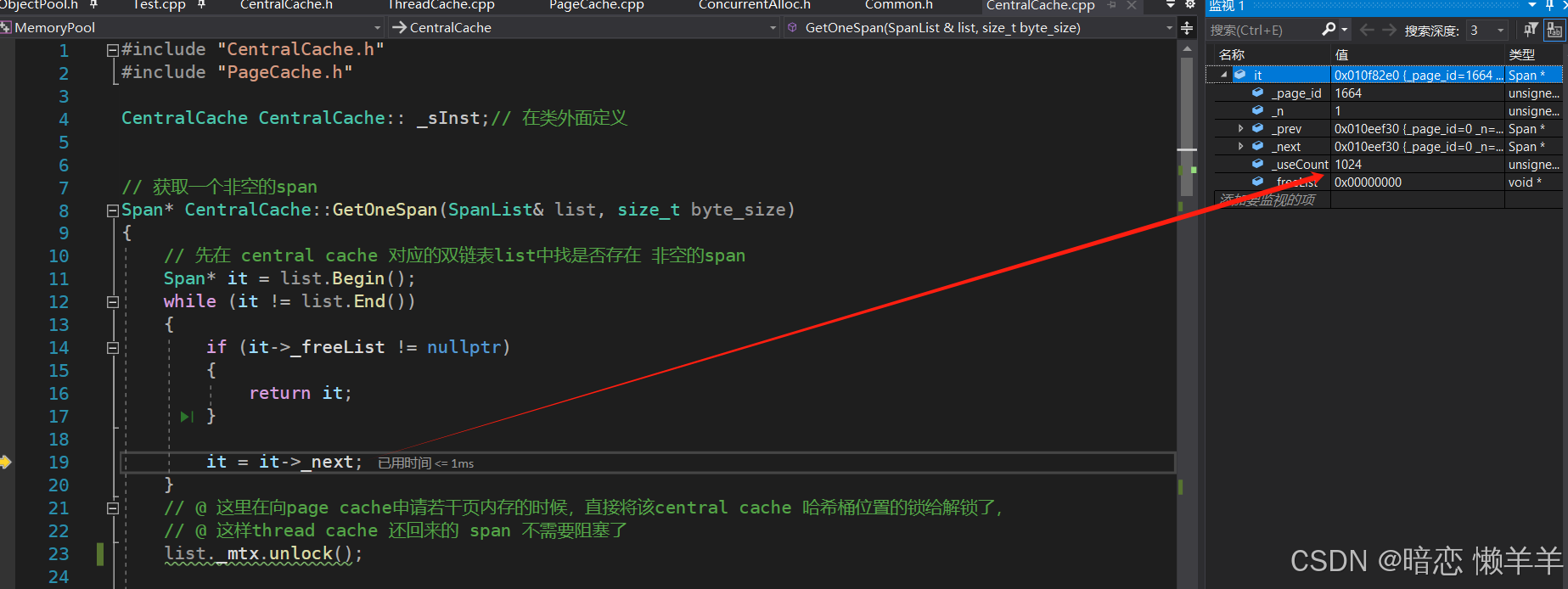
在central cache 的0号桶中获取一个非空的span 时,此时第一次所以是没有的,因此就需要去page cache 层获取。这里为了避免还回来内存对象需要等到锁,所以我们在去page cache层申请大块的页内存时,就需要把这个桶锁给解了
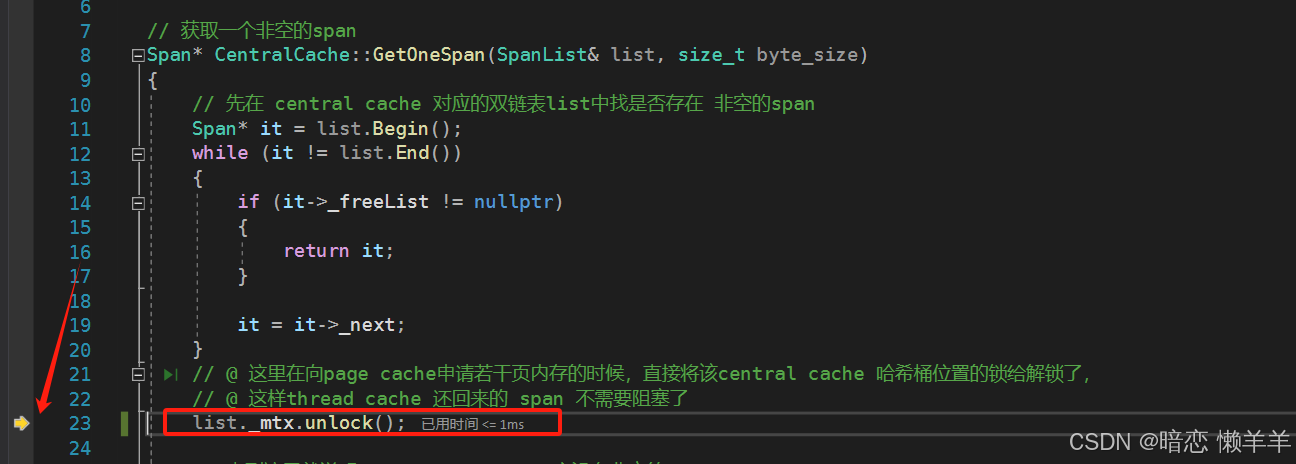
然后去page cache 申请大页的内存时,因为是需要遍历后面的桶的,所以直直接整体加互斥锁,等用完了解锁,分割。
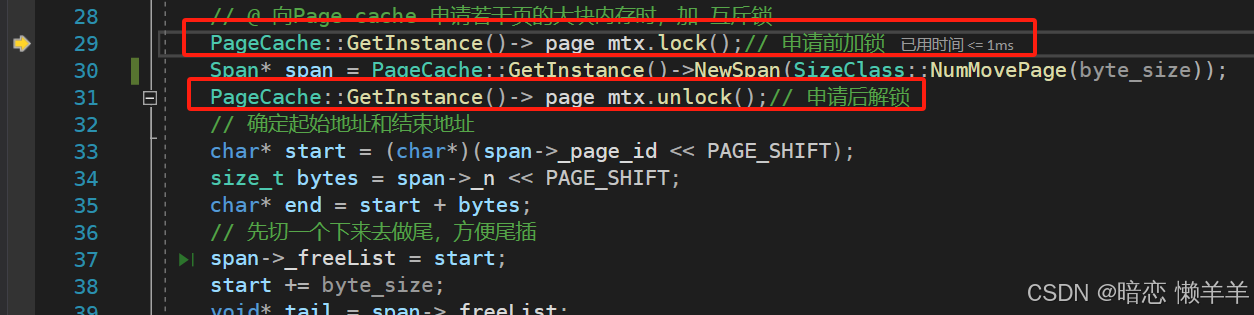
加完锁后就去page cache层申请大页对象,因为我们有可能某个线程申请的频次已经达到 上限了,所以我们一次给central cache 的大页内存至少得够 一个线程单次申请的上限数 即这里就是512,然后用上限数乘以单个对象的大小就是所需上限对象个数的总字节数,这里就是512*8=4096字节,我们在使用总字节数 除以 一页的大小就是对应应该申请几页了,这里就是 4096 / 8K = 0,我们的策略是至少给 1 页
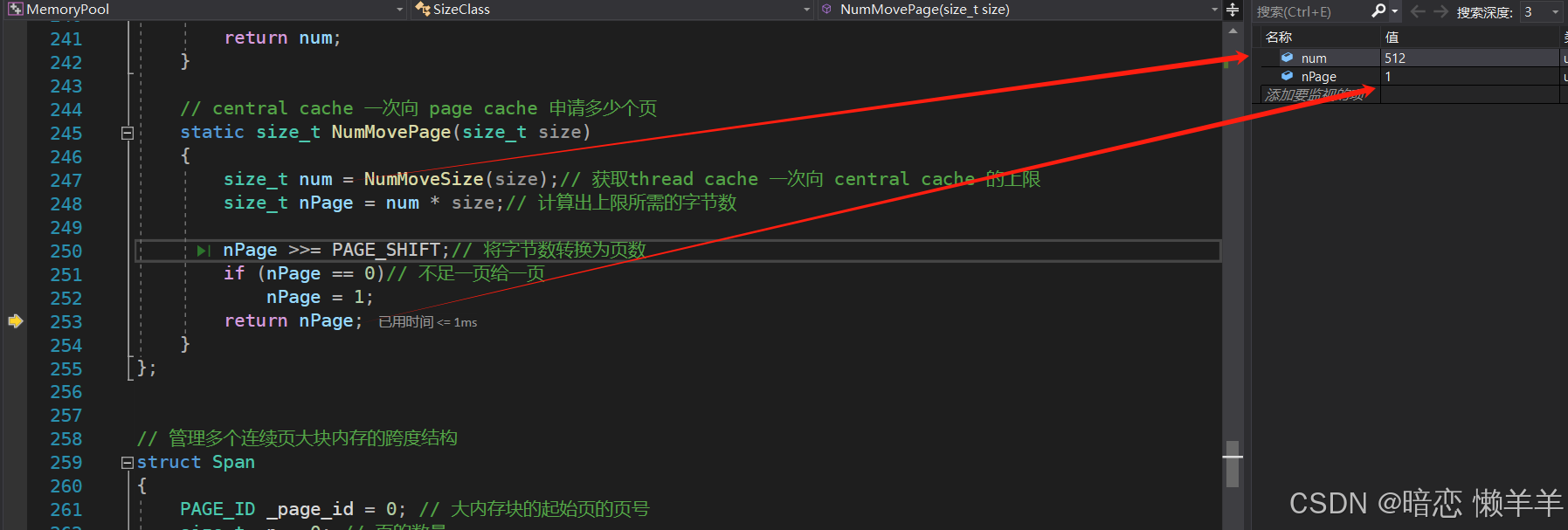
但是此时 page cache 的1号桶以及128都是空的,所以此时会想OS申请一个128页的内存span
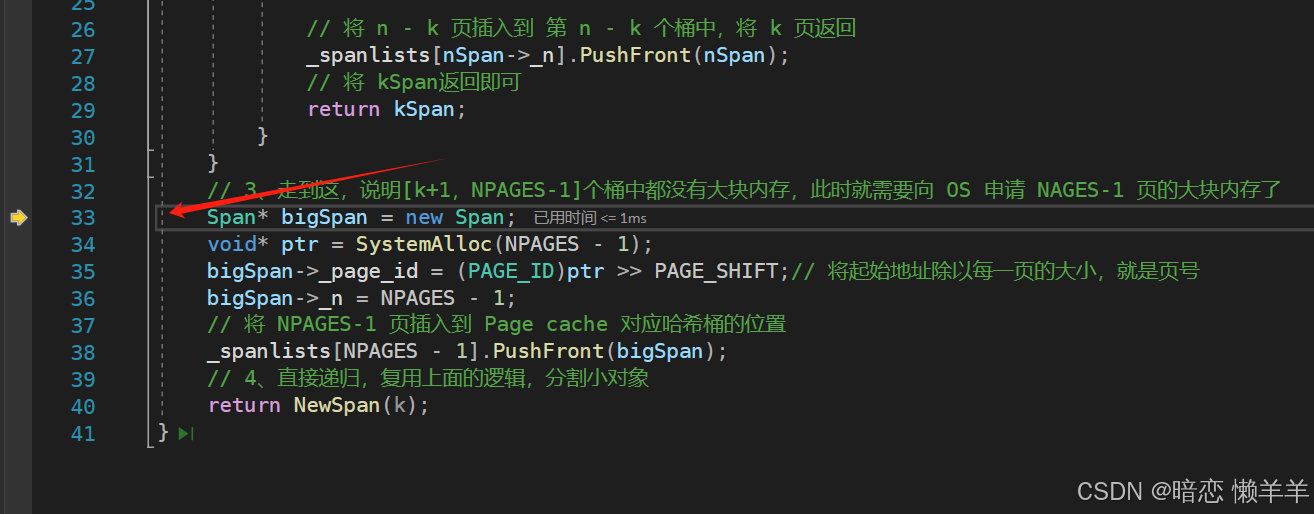
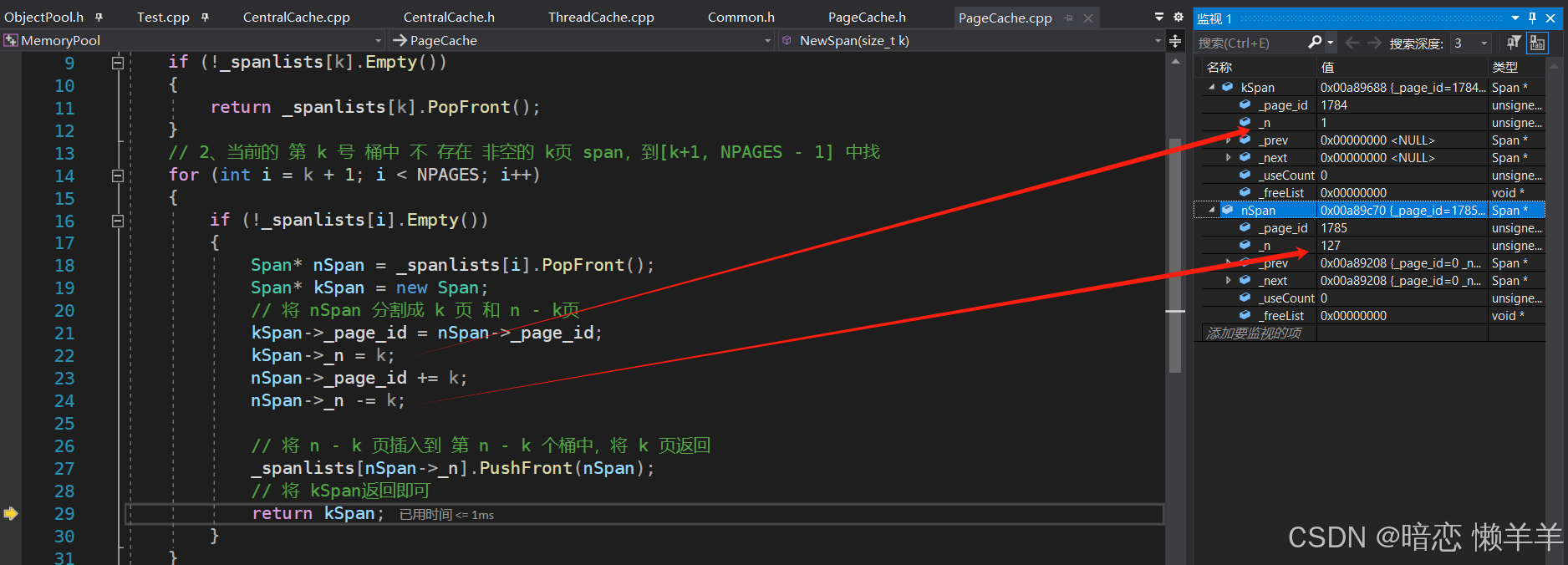
我们可以使用监视窗口看到,用于管理128页的span的信息
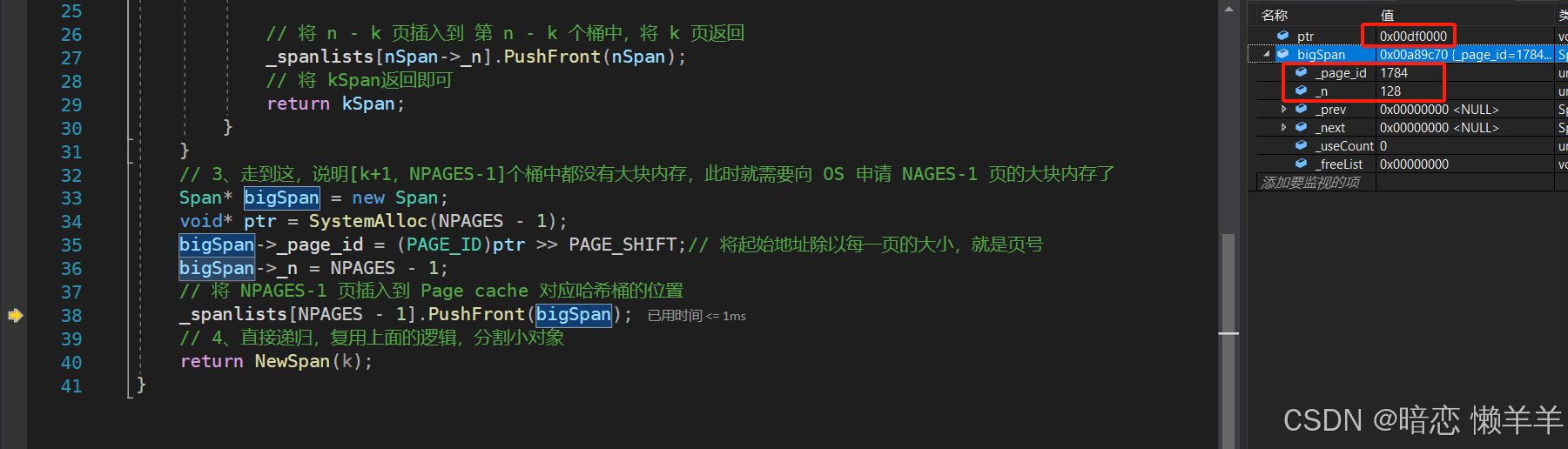
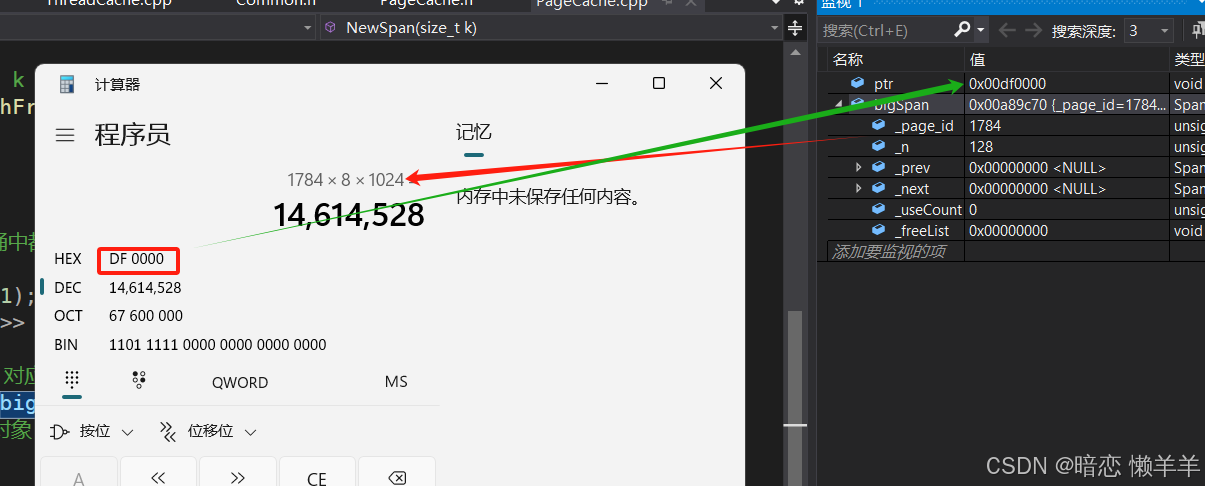
这里我么可以顺便验证一下,按页申请内存的起始地址和页号的转换的正确性:我么可以使用页号*一个的大小(8K)就可以得到128页的起始地址,转成16禁止个ptr对比
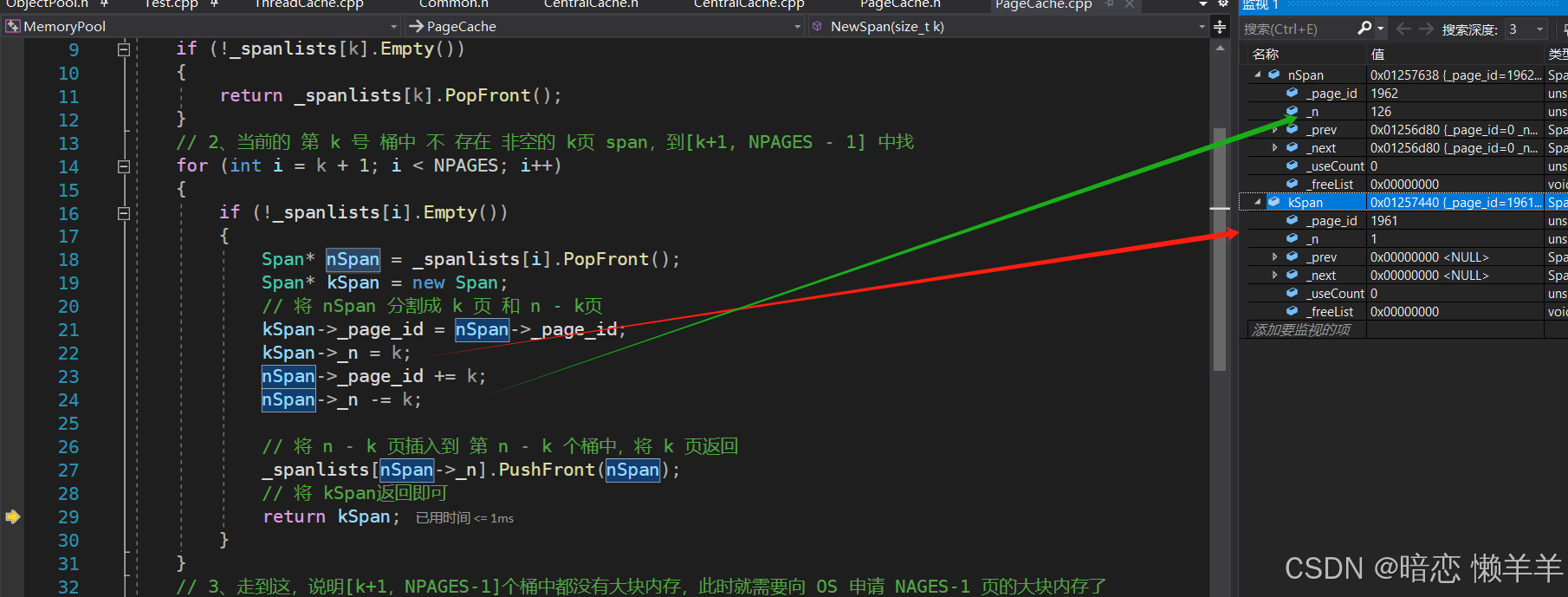
现在申请到了 128页的span此时将他插入到page cache 的第128号桶,然后继续递归调用一遍 NewSpan(k)即可,此时一定能找到一个非空的span
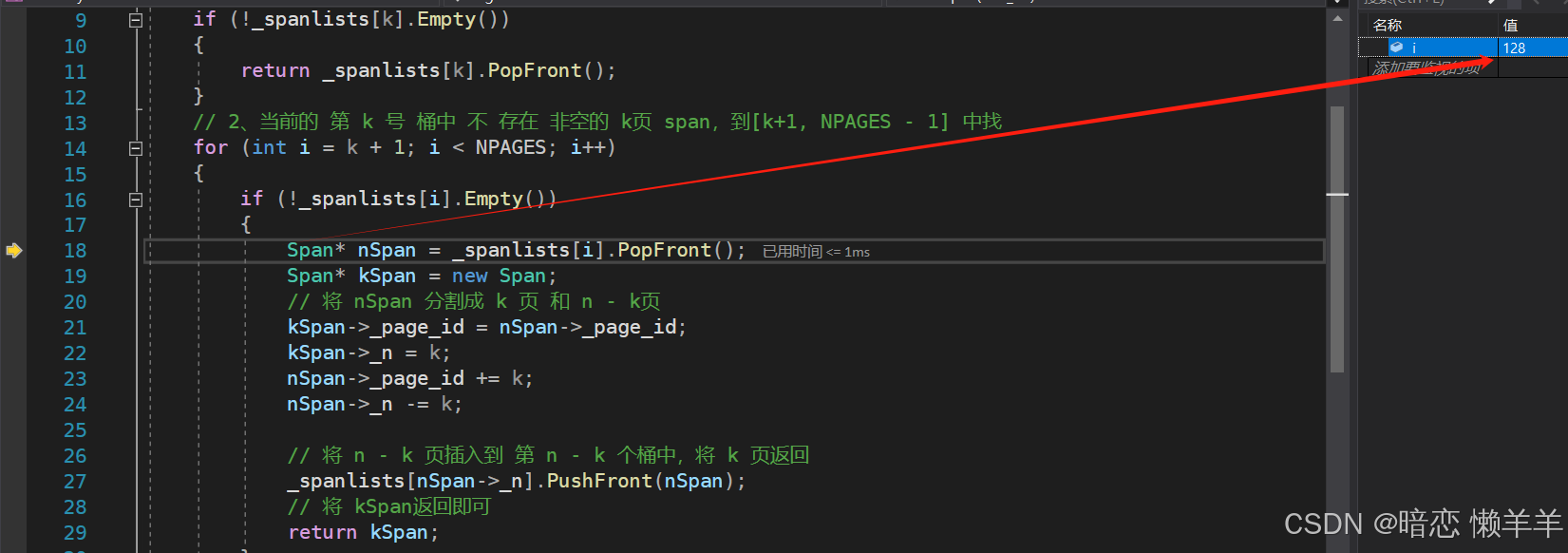
然后将128页的span 拿出来分成 1页 和 127页的span ,将1页的返回,将 127页的挂到page cache的第127号桶
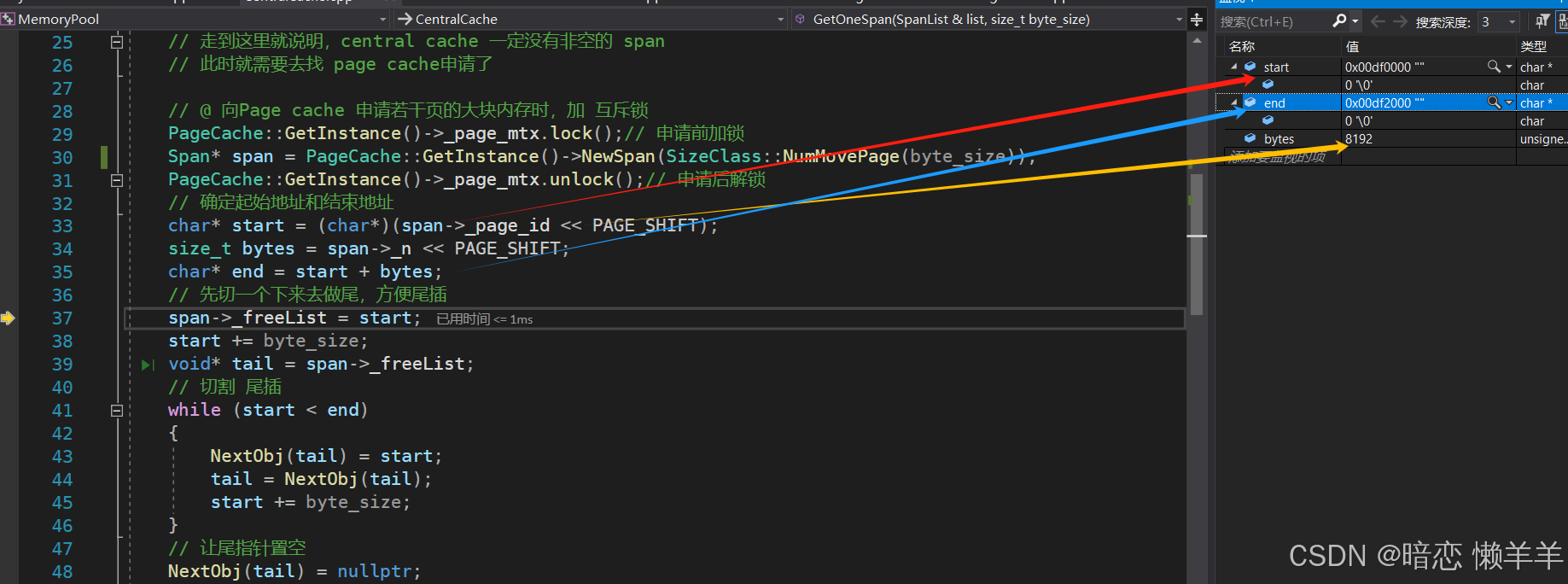
等大块页的内存申请完成之后,立即将page cache 的大锁解了,然后进行将大块内存进行分成固定大小的小内存挂到,span 的自由链表上。可以通过页号*8K计算出起始位置,然后用页数*8K计算出这么多页的总字节数,然后起始位置+总字节数就是结束位置。有了起始和结束位置就可以切割了
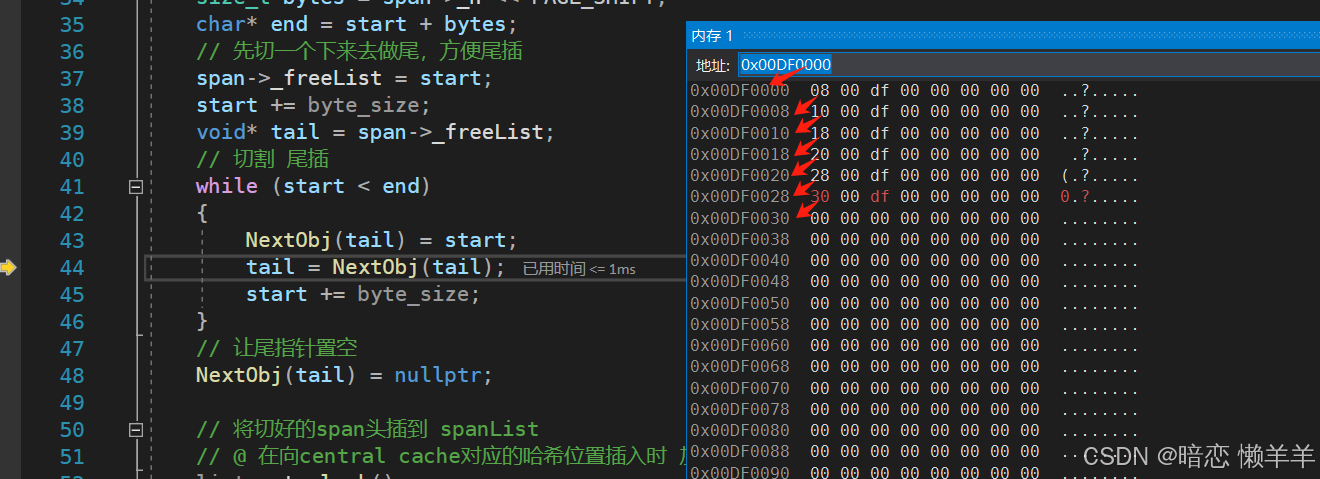
在切割成小对象的过程中,我们可以通过监视窗口的内存窗口看到,切分出来的每一个对象的前4个字节(win)都存的是下一个内存对象的起始地址。
当切分结束后再获取central cache第0号桶的桶锁,然后将这个切好的span插入到central cache的第0号桶中,最后再将这个非空的span返回,此时central cache就获取到了一个非空的span。
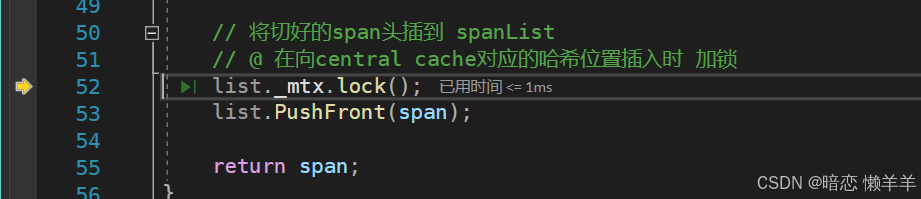
此时,我们也可以thread cache需要找central cache 申请一个对象,central cache的useCount应该也变成了1
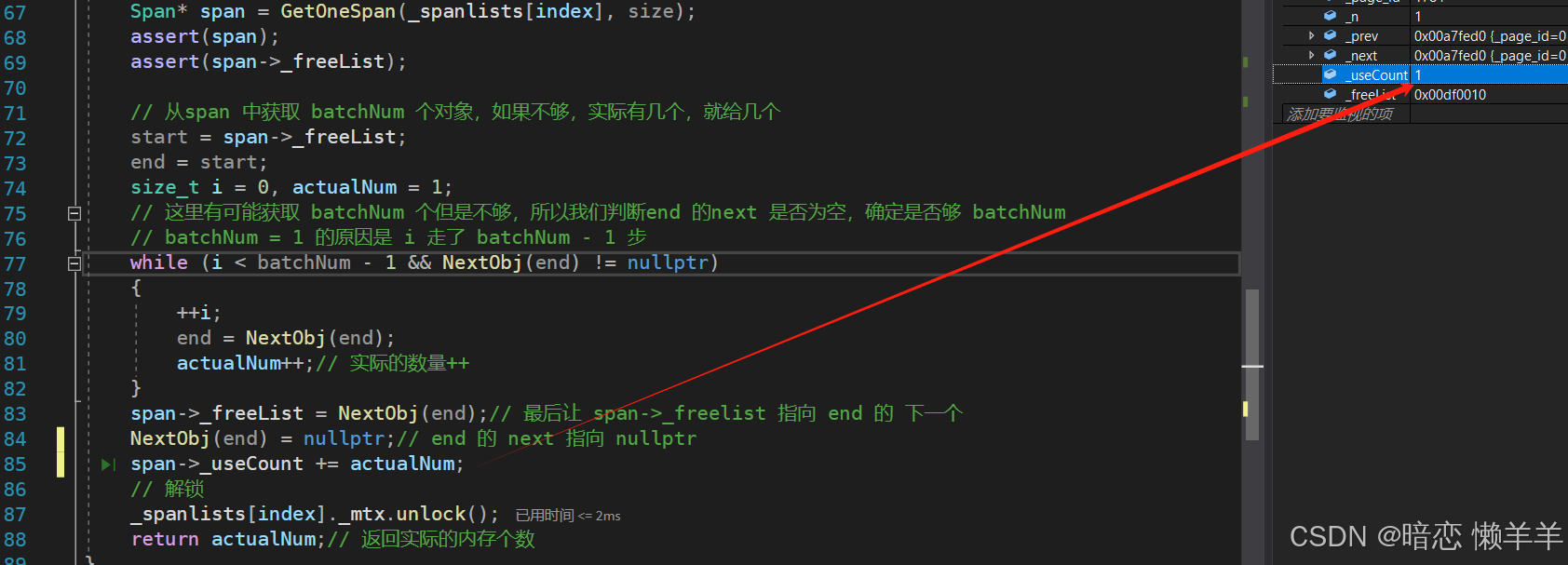
由于此时thread cache实际只向central cache申请到了一个对象,因此直接将这个对象返回给线程即可。
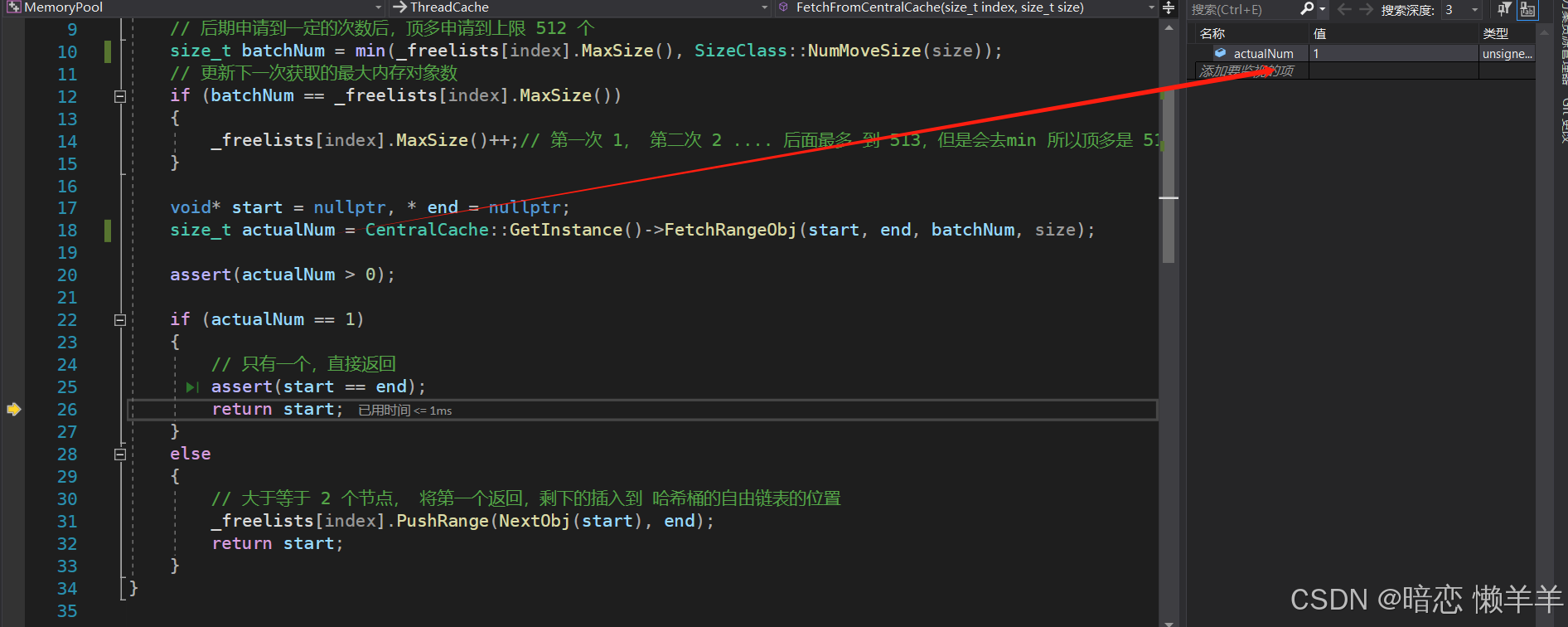
当同一个线程第二次申请8字节的对象时,就不会创建 thread cache对象了

第二次申请8字节的对象时,此时thread cache中还没有对象,因为第一次就是申请了一个,所以第二次好需要向central cache申请。
这是第二次增长,所以根据慢反馈调节算法,此时依然取的是 _maxSize 和 当前字节对应上限个数的最小值,因为第一次申请完成后对 _maxSize 加了1此时就是2,所以第二次申请2个对象,然后在对 _maxSize 加1,第三次再去central cache就申请三个
因为第一次central cache没有定长的内存即没有span,所以找page cache申请了一个一页的span对象并且分了1024个8字节的对象,用了一个剩余1023个,所以第二次是不需要在向 page cache申请了,直接取两个,一个返回,一个挂到thread cache 的0号桶即可

第三次申请,因为第2次申请了两个,用了一个,在thread cache的第0号桶还有一个,所以直接无锁申请即可
申请内存过程联调(二)
为了进一步测试代码的正确性,我们可以做这样一个测试:让线程申请1024次8字节的对象,然后通过调试观察在第1025次申请时,central cache是否会再向page cache申请内存块。
通过调试我们可以看到,第1025次申请8字节大小的对象时,central cache第0号桶中的这个span的_useCount已经增加到了1024,也就是说这1024个对象都已经被线程申请了,此时central cache就需要再向page cache申请一页的span来进行切分了
而这次central cache在向page cache申请一页的内存时,page cache就是将127页span切分成了1页的span和126页的span了,然后central cache拿到这1页的span后,又会将其切分成1024块8字节大小的内存块以供thread cache申请。
OK,整体的三层联调基本是没有问题的!我们下期开始介绍三层的回收过程及实现!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









