







1.操作Ajax选项
Ajax就是Asynchronous JavaScript and XML(异步JavaScript and XML)
搜狗的搜索框使用了Ajax。Ajax在不加载整个网页的情况下,对网页的某部分内容进行更新。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.sogou.com/")
searchbox = dr.find_element_by_xpath('//*[@id="query"]')
searchbox.click()
sleep(1)
searchbox.send_keys(Keys.ARROW_DOWN)
searchbox.send_keys(Keys.ARROW_DOWN)
searchbox.send_keys(Keys.ARROW_DOWN)
sleep(3)
dr.quit()Ajax悬浮框内容会发生变化(根据一定的推荐算法,而某些时候可能只需要固定的第几个选项)可以参考以下代码
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.sogou.com/")
searchbox = dr.find_element_by_xpath('//*[@id="query"]')
searchbox.click()
sleep(1)
dr.find_element_by_xpath('//*[@id="vl"]/div[1]/ul/li[2]').click()
sleep(2)
dr.quit()2.富文本编辑器(Rich Text Editor,RTE)
一种可内嵌于浏览器,所见即所得的文本编辑器。比如:邮箱
#writer:Taka
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get('https://mail.163.com/')
sleep(3)
ele = dr.find_element_by_xpath('//div[@id="loginDiv"]/child::iframe')
dr.switch_to_frame(ele)
dr.find_element_by_xpath('//div[@class="u-input box"]/child::input[@name="email"]').send_keys("youremail")
dr.find_element_by_xpath('//div[@class="u-input box"]/child::input[@name="password"]').send_keys("yourpwd")
dr.find_element_by_xpath('//*[@id="dologin"]').click()
sleep(2)
dr.find_element_by_xpath('//*[@id="_mail_component_78_78"]').click()
sleep(2)
dr.switch_to_frame(3)
dr.find_element_by_xpath('/html/body').send_keys("hello word")
sleep(5)
dr.quit()3.class的值有空格
<!DOCTYPEhtml>
<htmllang="en">
<head>
<metacharset="UTF-8">
<title>Title</title>
</head>
<body>
Pleace input your name:<inputclass="hello storm">
</body>
</html>方案一:使用前半部分或后半部分的名称定位
以下案例用的前半部分
#writer:Taka
import os
from selenium import webdriver
from time impor tsleep
dr = webdriver.Chrome()
dr.get(os.getcwd()[:17]+'HTMLfile/myhtml7_3class包含空格.html')#我把上面的HTML放在该位置了
sleep(2)
dr.find_element_by_class_name('hello').send_keys("handsome")
sleep(1)
dr.quit()方案二:使用CSS来定位元素,空格使用‘,’代替
#writer:Taka
import os
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get(os.getcwd()[:17]+'HTMLfile/myhtml7_3class包含空格.html')
sleep(2)
dr.find_element_by_css_selector('.hello,storm').send_keys("handsome")
sleep(1)
dr.quit()4、property、attribute、text的区别
“property”和“attribute”的中文意思十分接近,前者为属性,后者为特性。但是实际上这两种是不同的东西。property是DOM中的属性,是JavaScript里的对象;attribute是HTML标签上的特性,它的值只能是字符串。
以下实例感受三者区别:
#作者:Taka
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
ele = dr.find_element_by_id('kw')
print(ele.get_property("id"))#获取元素id的属性值
dr.quit()输出 :kw
#作者:Taka
#日期:2023/4/19
from seleniumimport webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
ele = dr.find_element_by_id('kw')
# print(ele.get_property("id"))#获取元素id的属性值
# dr.quit()
ele.send_keys("hello")
print(ele.get_attribute("value"))
dr.quit()输出:hello
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
ele = dr.find_element_by_link_text("地图")
print(ele.text)
dr.quit()输出:地图
小结: get_property()就是获取元素属性,目标元素id和name就可以通过该方法获取; get_attribute("value")就是用来获取文本框中输入的内容的; text属性就是元素本身的文字显示。
5.定位动态id
示例:126邮箱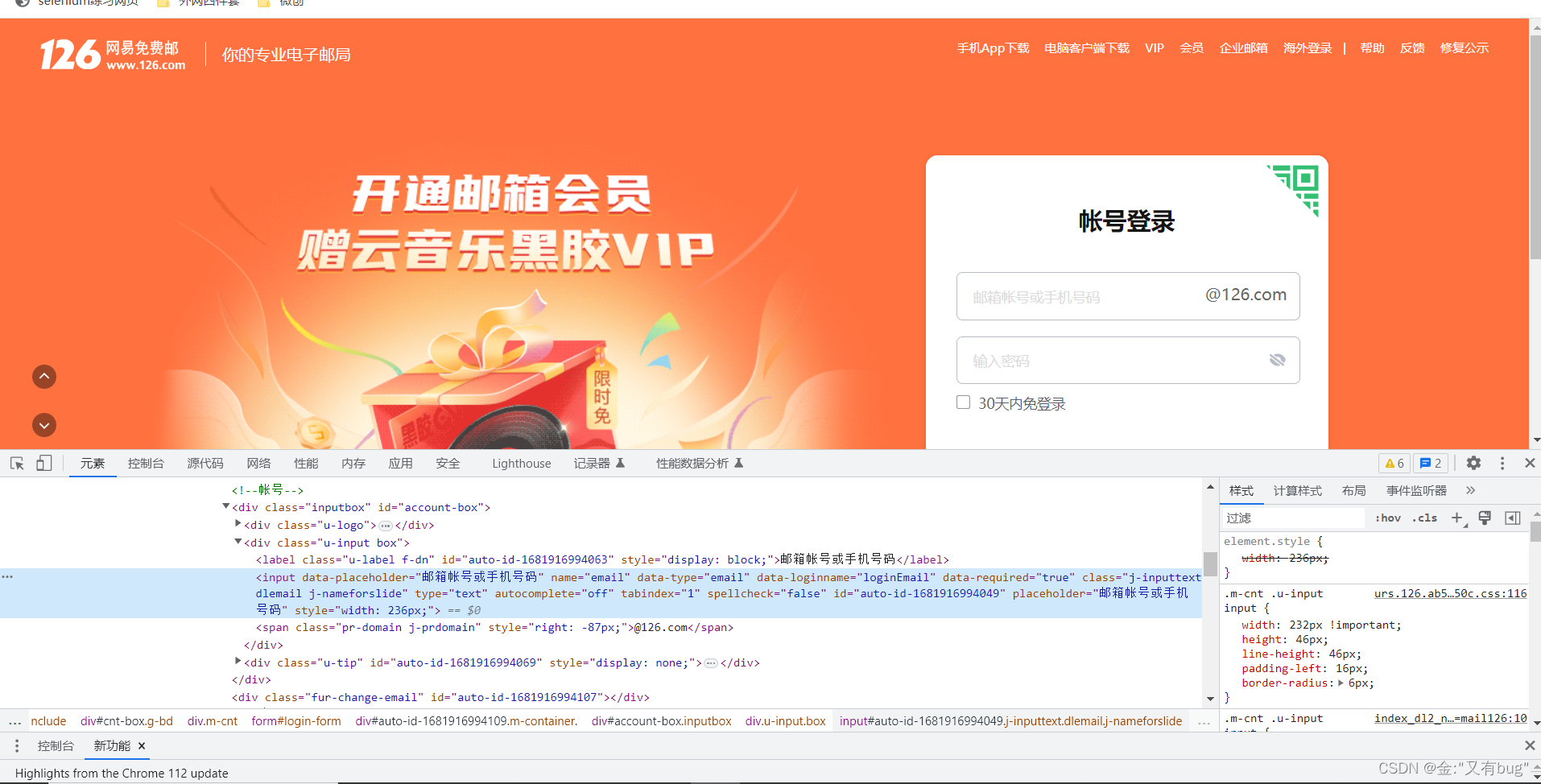
输入框有id属性,id的值由两部分组成,前面是auto-id-,后面是一串数字。刷新页面就会发现数字变化了,这就是动态id
如何进行定位?
- 使用其他定位方式定位。比如元素中有其他唯一属性:class name,name等等。
- 相对关系定位
- 根据父子、兄弟相邻节点定位
- 根据部分元素属性定位
- Xpath提高3种强大的方法支持定位部分属性值。contains(a,b):如果a中含有字符串b、则返回True,否则返回False。starts-with(a,b):如果a以字符串b开头,则返回True,否则返回False。ends-with(a,b):如果a以字符串b结尾,返回True,否则返回False。
1.使用contains关键字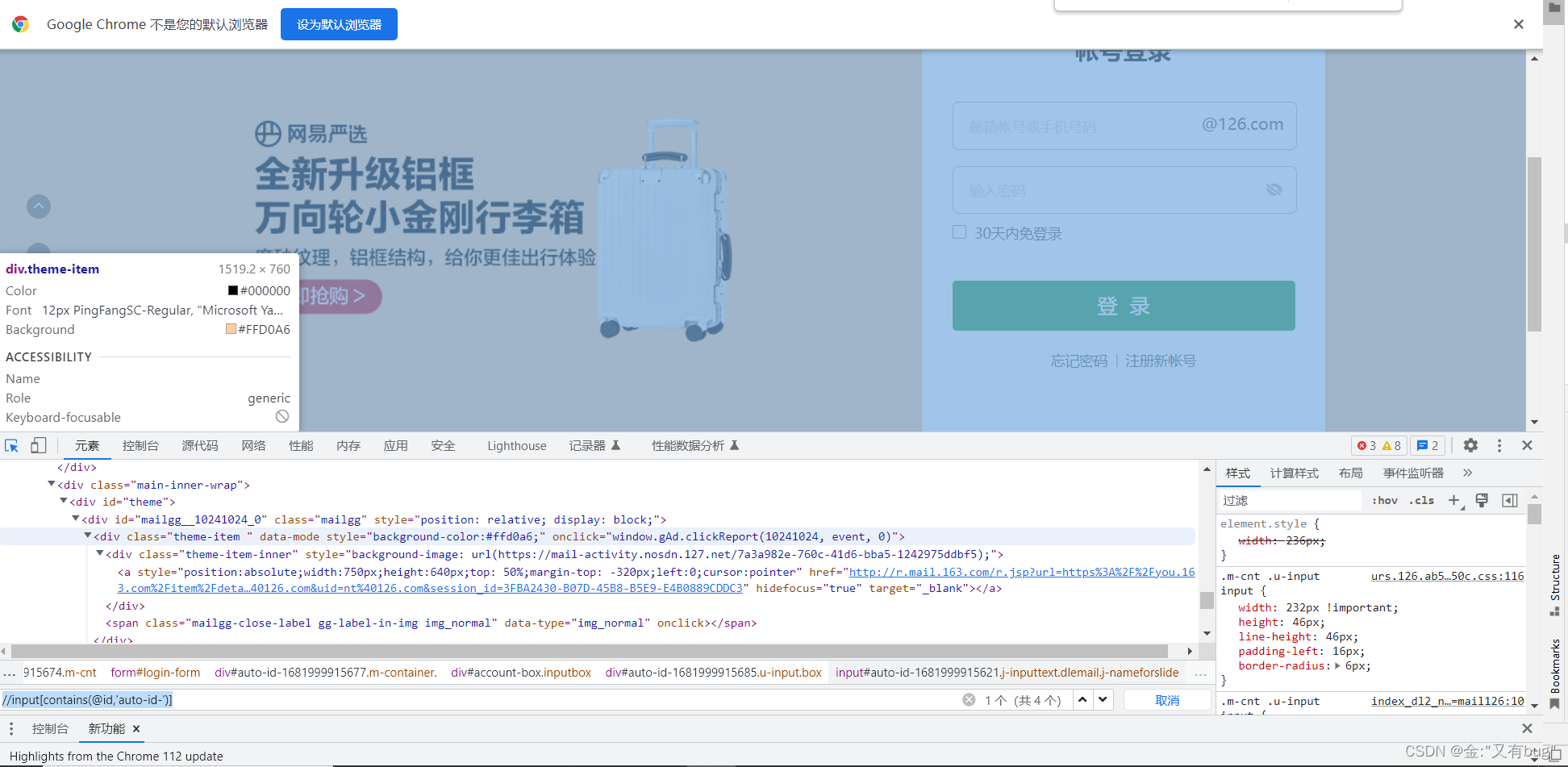
这里无法唯一定位,垃圾方法
2.使用starts-with(a,b)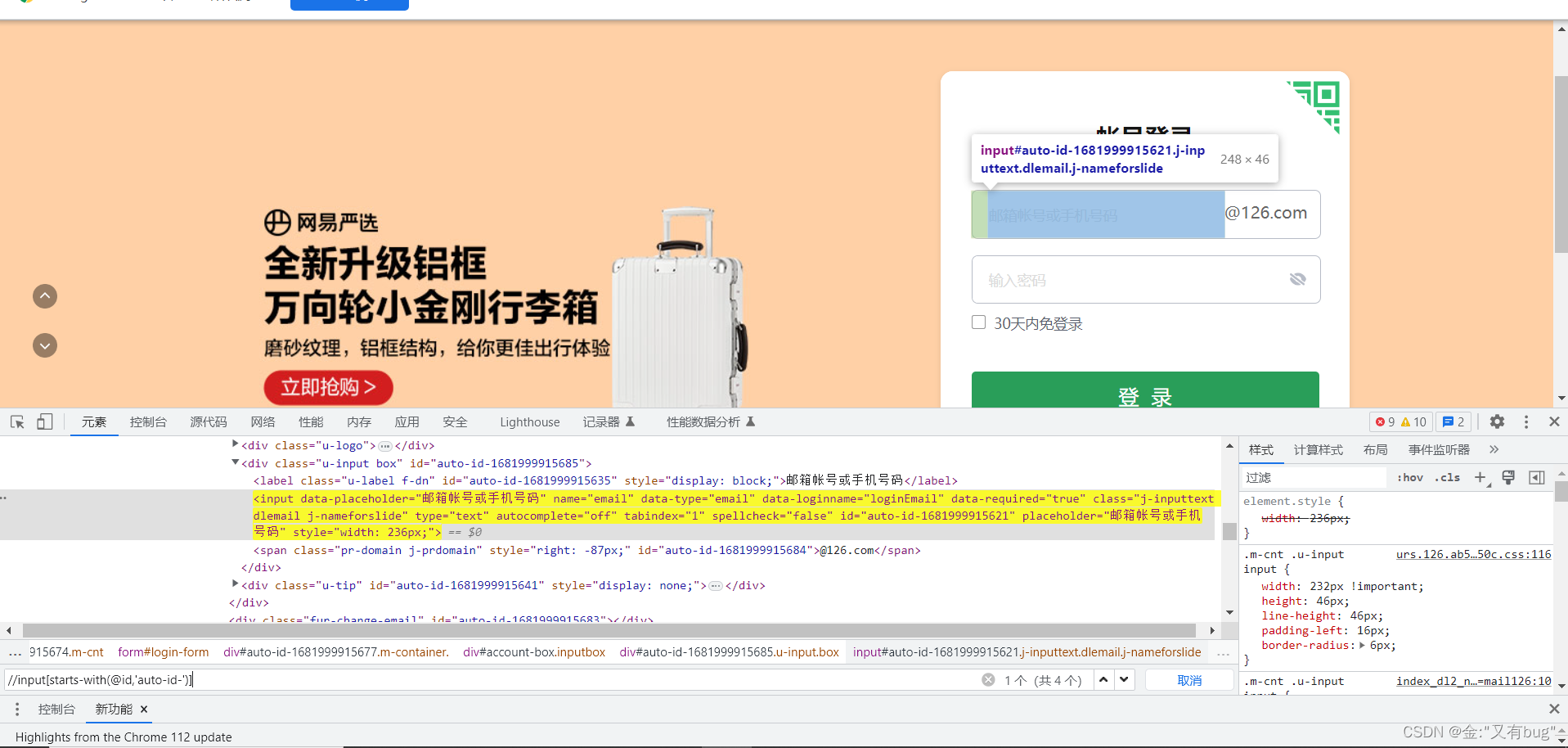
这里无法唯一定位,垃圾方法
以上内容作为了解吧
5.操作cookie
一.cookie、session、token的区别
- cookie存储在浏览去本地客户端,当我们发送的请求携带cookie时可以实现登录的操作
- session存放在服务器
- token应用于应用程序
二.如何查看cookie
方法一:使用开发者工具查看
方法二:查看网站信息
三、操作cookie的方法
获取全部的cookie
关键字:get_cookies,获取当前浏览器地址的所有cookie,返回结果是一个列表,列表元素是一个字典{key:value}
#作者:Taka
from seleniumimport webdriver
from time import sleep
url ='https://www.baidu.com/'
dr = webdriver.Chrome()
dr.implicitly_wait(20)
dr.get(url)
cur_cookie = dr.get_cookies()
print(type(cur_cookie))#输出返回值类型--->字典
print(len(cur_cookie))#输出cookie的数量
print(type(cur_cookie[0]))#输出单个cookie的类型
print(cur_cookie)#输出cookie值
sleep(2)
dr.quit()关键字get_cookie
#作者:Taka
from selenium import webdriver
from time import sleep
url ='https://www.baidu.com/'
dr = webdriver.Chrome()
dr.implicitly_wait(20)
dr.get(url)
baidu_cookie = dr.get_cookie("BD_UPN")
print(type(baidu_cookie))#输出cookie类型
print(baidu_cookie)#输出cookie的值
dr.quit()删除单个cookie
# 作者:Taka
from selenium import webdriver
from time import sleep
url = 'https://www.baidu.com/'
dr = webdriver.Chrome()
dr.implicitly_wait(20)
dr.get(url)
baidu_cookies = dr.get_cookies()
print(len(dr.get_cookies()))#删除前数量
dr.delete_cookie("BAIDUID")#删除名为BAIDUID的cookie
print(len(dr.get_cookies()))#删除后数量
dr.quit()删除所有cookie
# 作者:Taka
# 日期:2023/4/21
from selenium import webdriver
from time import sleep
url = 'https://www.baidu.com/'
dr = webdriver.Chrome()
dr.implicitly_wait(20)
dr.get(url)
baidu_cookies = dr.get_cookies()
print(len(dr.get_cookies()))#删除前数量
dr.delete_all_cookies()#删除所有cookie
print(len(dr.get_cookies()))#删除后数量
dr.quit()# 作者:Taka
from selenium import webdriver
from time import sleep
url = 'https://www.baidu.com/'
dr = webdriver.Chrome()
dr.implicitly_wait(20)
dr.get(url)
baidu_cookies = dr.get_cookies()
print(len(dr.get_cookies()))#删除前数量
dr.add_cookie({"name":"STORM","value":"123456"})#添加cookie
print(len(dr.get_cookies()))#删除后数量
dr.quit()四.截图功能
# 作者:Taka
from selenium import webdriver
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
dr.implicitly_wait(20)
dr.save_screenshot("../reports/a.png")#截取当前页面,保存当前目录,保存成.png图片
#dr.get_screenshot_as_file()#等同上面的方法
dr.quit()需求:为避免图片名称重复,将图片名称改为“脚本名+时间戳+png”格式
# 作者:Taka
#需求:为避免图片名称重复,将图片名称改为“脚本名+时间戳+png”格式
from selenium import webdriver
import os
import time
script_name = os.path.basename(__file__).split('.')[0]#获取脚本名
file_name = "../reports/"+script_name+str(time.time())+".png"#组合成文件名
# print(os.path.basename(__file__))#7_22截图2.py
# print(os.path.basename(__file__).split('.'))#['7_22截图2', 'py']
# print(script_name)#7_22截图2
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
dr.save_screenshot(file_name)#截图
dr.quit()
页面截图,返回二进制数据
from selenium import webdriver
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
a = dr.get_screenshot_as_png()#截图返回截图的二进制数据
print(type(a))
print(a)
dr.quit()截图返回base64的字符串
# 作者:Taka
from selenium import webdriver
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
a = dr.get_screenshot_as_base64()#截图并返回base64的字符串
print(type(a))
print(a)
dr.quit()截图对比
# 作者:Taka
from selenium import webdriver
import unittest,time
from PIL import Image
'''
某些情况下,我们需要对某个功能执行两次并分别截图,通过比较截图来验证功能是否没问题
首先安装Python的pillow包,然后from PIL import Image
'''
class ImageCompare(object):
'''
本实例实现的功能是对两张图片通过像素对比的算法,获取文件的像素个数大小
然后通过循环的方式对两张图片的所有项目进行一一对比
并计算对比结果的相似度的百分比
'''
def make_regalur_image(self,img,size = (256,256)):
#将图片尺寸强制重置为指定的大小,然后再将其转换成RGB
return img.resize(size).convert("RGB")
def split_image(self,img,part_size = (64,64)):
#将图片按给定大小切分
w,h = img.size
pw,ph = part_size
assert w % pw == h % ph == 0
return [img.crop((i,j,i + ph,j + ph)).copy()
for i in range(0,w,pw) for j in range(0,h,ph)]
def hish_similar(self,lh,rh):
#统计切分后每部分图片的相似度频率曲线
assert len(lh) == len(rh)
return sum(1 - (0 if l == r else float(abs(l-r)) / max(l,r))
for l,r in zip(lh,rh)) / len(lh)
def calc_similar(self,li,ri):
#计算两张图片的相似度
return sum(self.hish_similar(l.histogram(),r.histogram())
for l,r in zip(self.split_image(li),self.split_image(ri)))/16.0
def calc_similar_by_path(self,lf,rf):
li,ri = self.make_regalur_image(Image.open(lf)),\
self.make_regalur_image(Image.open(rf))
return self.calc_similar(li,ri)
class TestDemo(unittest.TestCase):
def setUp(self):
self.IC = ImageCompare()
self.driver = webdriver.Chrome()
def test_ImageComparison(self):
self.driver.get("https://www.baidu.com/")
self.driver.save_screenshot("../reports/a.png")
time.sleep(1)
self.driver.get("https://www.baidu.com/")
self.driver.save_screenshot("../reports/b.png")
time.sleep(1)
print("图片相似度为:",self.IC.calc_similar_by_path("../reports/a.png","../reports/b.png"))
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()断言失败截图
# Writer:Taka
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.baidu.com/")
dr.find_element_by_id("kw").send_keys("Hello")
print(dr.find_element_by_id('kw').get_property("value"))
if dr.find_element_by_id('kw').get_property("value") == "hello":
print("输入hello成功")
else:
dr.save_screenshot("../reports/baidu_test.png")
dr.quit()五、获取焦点元素
# Writer:Taka
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 获取当前焦点所在元素的attribute信息
id = driver.switch_to.active_element.get_attribute("id")
element_facus = driver.switch_to.active_element
element_facus.send_keys("123456")
print(id)
time.sleep(2)
driver.quit()
六、颜色验证
<!DOCTYPE html>
<html>
<head>
<title>红色背景页面</title>
<style id="ground" type="text/css">
body {
background-color: rgba(0, 0, 0, 1);
}
</style>
</head>
<body>
<h1>这是一个黑色背景的页面
body {
background-color: black;
}</h1>
<p>你好,这是一个示例页面。</p>
</body>
</html># Writer:Taka
import os
import time
from selenium.webdriver.support.color import Color
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pytest
# 创建 Chrome WebDriver 实例
driver = webdriver.Chrome()
# 打开网页
file_path = os.getcwd()[:40]+"Webpage_HTML/redground.html"
print(file_path)
driver.get(file_path)
# 等待页面加载完毕并检查背景颜色
time.sleep(3)
RED = Color.from_string("rgba(0, 0, 0, 1)")
background_color = driver.find_element(By.TAG_NAME,"body").value_of_css_property("background-color")
print(background_color)
assert background_color == "rgba(0, 0, 0, 1)","页面背景颜色不是红色"
# 关闭浏览器 20;、
driver.quit()七、JavaScript 的应用
操作页面元素
# Writer:Taka
from selenium import webdriver
from time import sleep
dr = webdriver.Chrome()
dr.get("https://www.baidu.com")
sleep(2)
ele1JS = 'document.querySelector("#kw").value="123456"'
ele2JS = 'document.querySelector("#su").click()'
dr.execute_script(ele1JS)
sleep(1)
dr.execute_script(ele2JS)
sleep(1)
dr.quit()
修改页面元素
<input type="datetime-local" id="time" readonly># Writer:Taka
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import os
driver = webdriver.Chrome()
file_path = os.getcwd()[:40]+"Webpage_HTML/readonly_datetime.html"
driver.get(file_path)
time.sleep(2)
js1 = 'document.getElementById("time").removeAttribute("readonly")' # 原生js.移除属性
# js1 = '$("input[id=time]").removeAttr("readonly")'# jQuery,移除属性
# js1 = '$("input[id=time]").attr("readonly",False)'# jQuery,设置属性为False
# js1 = '$("input[id=time]").attr("readonly",“”)'# jQuery,设置属性为空
driver.execute_script(js1)
ele_time = driver.find_element(By.XPATH,"/html/body/input")
ele_time.send_keys("002023/05/05/15/59")
time.sleep(10)
# driver.close()
操作滚动条
# Writer:Taka
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("123456")
driver.find_element_by_id("su").click()
js1 = "window.scrollTo(0,document.body.scrollHeight)"# 滑动滚动条到最底部
js2 = "window.scrollTo(0,0)" # 滑动到顶端
js3 = "window.scrollTo(0,200)" # 滑动200像素
js4 = "arguments[0].scrollIntoView();" # 滑动到指定元素
sleep(2)
driver.execute_script(js1)
print("已完成到最底部")
sleep(5)
driver.execute_script(js2)
print("已完成到最顶部")
sleep(5)
driver.execute_script(js3)
print("已完成滑动200像素")
sleep(5)
driver.execute_script(js2)
sleep(2)
ele_argument = driver.find_element(By.XPATH,'//*[@id="rs_new"]/div')# 定位某个元素
driver.execute_script(js4,ele_argument)#滑动到上方定位元素位置
print("已完成到指定元素位置")
sleep(5)
driver.quit()操作滚动条左右移动
# Writer:Taka
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.set_window_size(500,500)
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("123456")
sleep(1)
js1 = "window.scrollTo(document.body.scrollWidth,0)"# 滑动滚动条到最右边
js2 = "window.scrollTo(0,0)" # 滑动到最左边
js3 = "window.scrollTo(200,0)" # 向右滑动200像素
sleep(2)
driver.execute_script(js1)
print("已完成到最右")
sleep(5)
driver.execute_script(js2)
print("已完成到最左部")
sleep(5)
driver.execute_script(js3)
print("已完成向右滑动200像素")
sleep(5)
driver.execute_script(js2)
sleep(5)
driver.quit()操作内嵌滚动条
# Writer:Taka
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://sahitest.com/demo/iframesTest.htm")
ele_iframe1 = driver.find_element(By.XPATH,"/html/body/iframe")
driver.switch_to.frame(ele_iframe1)
sleep(2)
js1 = "window.scrollTo(0,document.body.scrollHeight)"
driver.execute_script(js1)
sleep(2)
driver.quit()八、高亮显示正被操作的元素
# Writer:Taka
def heighLightElement(driver,element):
'''
封装显示页面元素的方法:使用js代码将页面元素对象的背景颜色设置成绿色,边框设置为红色
:param driver:
:param element:
:return:
'''
driver.execute_script("arguments[0].setAttribute('style',arguments[1]);",element,"background:yellow;border: 10px solid red;")
if __name__ == '__main__':
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
ele = driver.find_element_by_id("kw")
heighLightElement(driver,ele)
sleep(3)
driver.quit()九、JavaSript操作span元素
# Writer:Taka
from selenium import webdriver
from time import sleep
from tools.getHTMLfilepath import get_htmlpath
driver = webdriver.Chrome()
htmlfile = get_htmlpath()+"含有span类型2..html"
driver.get(htmlfile)
js1 = "document.getElementById('span_id').innerText='aaa'"
driver.execute_script(js1)
sleep(2)
driver.quit()十、定制参数启动浏览器
最大化启动
# Writer:Taka
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
options.add_argument("--start-maximized")#z最大化参数
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://www.baidu.com")
sleep(2)
driver.quit()
指定编码格式
# Writer:Taka
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
options.add_argument("lang=zh_CN.UTF-8")
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://www.baidu.com")
ele = driver.find_element_by_id("su")
print(ele)
driver.quit()指定浏览器的driver
# Writer:Taka
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome(executable_path="D:\python\chromedriver.exe")
driver.get("https://www.baidu.com")
ele = driver.find_element_by_id("su")
print(ele)
driver.quit()无界面启动
# Writer:Taka
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
options.add_argument('headless')
dr = webdriver.Chrome(chrome_options=options)
dr.get("https://www.baidu.com")
ele = dr.find_element_by_id("kw")
print(ele)
dr.quit()禁止加载图片
# Writer:Taka
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values' : {
'images' : 2
}
}
options.add_experimental_option("prefs",prefs)
dr = webdriver.Chrome(chrome_options=options)
dr.get("https://www.baidu.com")
sleep(3)
dr.quit()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









