在使用 Python 爬虫抓取网页数据时,经常会遇到各种数据格式。了解这些格式的特点和处理方法,对于高效提取和利用数据至关重要。
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】!
本节将重点介绍在开发中常见的几种数据格式,包括 HTML、JSON、XML 和二进制数据,并提供相应的处理方法和代码示例。
1.HTML:网页的骨架
- HTML(超文本标记语言)是用于构建网页的标准标记语言。它由一系列的标签组成,这些标签定义了网页的结构和内容。
示例代码:解析 HTML 数据
from bs4 import BeautifulSoup
html_data = '''
<html>
<head>
<title>示例网页</title>
</head>
<body>
<h1>欢迎来到我的网页</h1>
<p>这是一个段落。</p>
<a href="https://www.example.com">链接到示例网站</a>
</body>
</html>
'''
soup = BeautifulSoup(html_data, 'html.parser')
title = soup.find('title').text
print(f"标题:{title}")
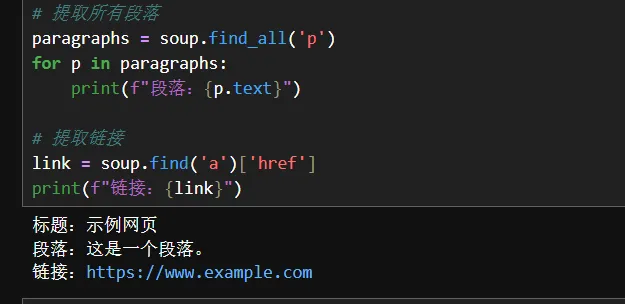
paragraphs = soup.find_all('p')
for p in paragraphs:
print(f"段落:{p.text}")
link = soup.find('a')['href']
print(f"链接:{link}")
代码说明:
- BeautifulSoup:用于解析 HTML 数据。
- soup.find() 和 soup.find_all():用于查找特定标签。
- text:获取标签内的文本内容。
- [‘href’]:获取标签的属性值。
2.JSON 轻量级数据交换格式
- JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和编写,同时也易于机器解析和生成
- JSON 数据通常以键值对的形式组织,类似于 Python 中的字典。
示例代码:处理 JSON 数据
import json
json_data = '''
{"name": "John","age": 30,"city": "New York","skills": ["Python", "JavaScript", "HTML"]}
'''
data = json.loads(json_data)
name = data['name']
age = data['age']
city = data['city']
skills = data['skills']
print(f"姓名:{name}")
print(f"年龄:{age}")
print(f"城市:{city}")
print(f"技能:{', '.join(skills)}")
new_data = {"name": "Jane","age": 25,"city": "Los Angeles","skills": ["Java", "C++", "SQL"]}
json_string = json.dumps(new_data)
print(f"新的 JSON 数据:{json_string}")

代码说明:
- json.loads():将 JSON 字符串转换为 Python 字典。
- json.dumps():将 Python 字典转换为 JSON 字符串。
- data[‘key’]:通过键访问字典中的值。
3.XML 结构化数据格式
- XML(可扩展标记语言)是一种用于标记电子文档的标记语言,它类似于 HTML,但更灵活,可以自定义标签。XML 常用于数据存储和传输。
示例代码:解析 XML 数据
import xml.etree.ElementTree as ET
xml_data = '''
<root>
<person>
<name>John</name>
<age>30</age>
<city>New York</city>
</person>
<person>
<name>Jane</name>
<age>25</age>
<city>Los Angeles</city>
</person>
</root>
'''
root = ET.fromstring(xml_data)
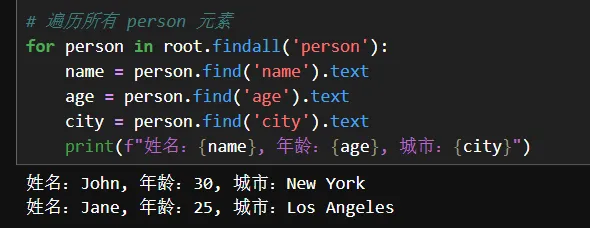
for person in root.findall('person'):
name = person.find('name').text
age = person.find('age').text
city = person.find('city').text
print(f"姓名:{name}, 年龄:{age}, 城市:{city}")
代码说明:
- ET.fromstring():将 XML 字符串解析为 ElementTree 对象。
- root.findall():查找所有指定标签的元素。
- person.find():查找指定标签的子元素。
4.二进制数据:多媒体文件的传输
- 二进制数据是计算机中存储和传输数据的基本形式。常见的二进制数据包括图片、音频、视频等。在流传输中,我们经常需要下载这些二进制文件。
示例代码:下载二进制文件
import requests
image_url = "https://example.com/image.jpg"
response = requests.get(image_url, stream=True)
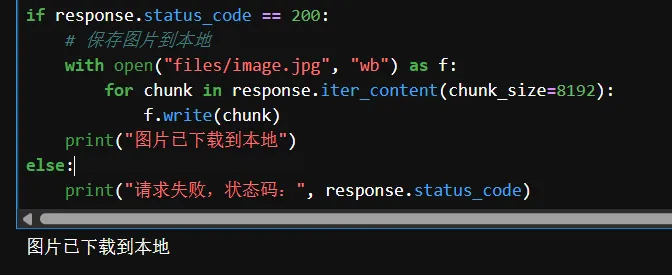
if response.status_code == 200:
with open("image.jpg", "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print("图片已下载到本地")
else:
print("请求失败,状态码:", response.status_code)
代码说明:
- requests.get():发送 GET 请求。
- stream=True:以流的形式下载文件,避免占用过多内存。
- response.iter_content():逐块读取响应内容。
- wb:以二进制写入模式打开文件。
在Python开发中,常见的数据格式包括 HTML、JSON、XML 和二进制数据。每种格式都有其特点和处理方法:
- HTML:用于构建网页,通过 BeautifulSoup 解析。
- JSON:轻量级数据交换格式,通过 json 模块处理。
- XML:结构化数据格式,通过 xml.etree.ElementTree 解析。
- 二进制数据:用于存储和传输多媒体文件,通过 requests 下载。
掌握这些数据格式的处理方法,可以帮助我们更高效地提取和利用爬取到的数据。希望这些示例能帮助你更好地理解和应用这些知识。

总结
- 最后希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
- 最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】领取!
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,学习不再是只会理论
- ④ 华为出品独家Python漫画教程,手机也能学习
可以扫描下方二维码领取【保证100%免费】
























 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









