






1旋转链表
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
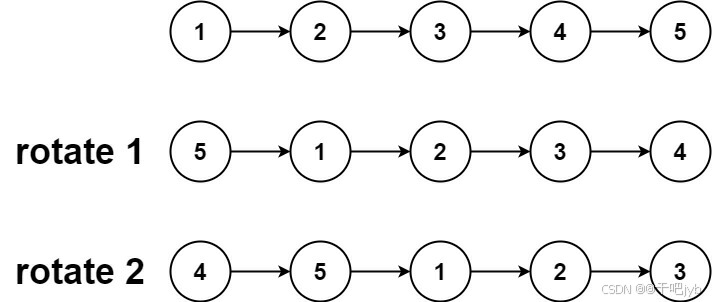
输入:head = [1,2,3,4,5], k = 2 输出:[4,5,1,2,3]
示例 2:
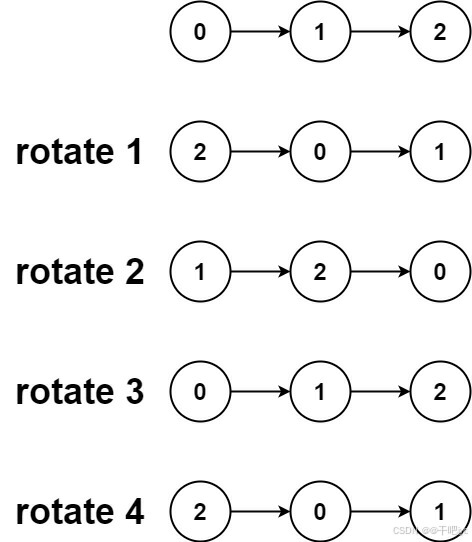
输入:head = [0,1,2], k = 4 输出:[2,0,1]
提示:
- 链表中节点的数目在范围
[0, 500]内 -100 <= Node.val <= 1000 <= k <= 2 * 109
思路:通过将链表首尾相连形成一个环,然后通过找到新的头节点并断开环来实现链表的旋转
-
初步判断:
- 如果
k为 0,或者链表为空,或者链表只有一个节点,直接返回原链表。因为旋转这些情况不会改变链表的结构。
- 如果
-
计算链表长度:
- 使用指针
p遍历整个链表,计算链表的长度count。这一步是为了确定链表中有多少个节点。
- 使用指针
-
形成环:
- 将链表的最后一个节点
p的next指向head,将链表形成一个环。这一步是为了方便后续的旋转操作。
- 将链表的最后一个节点
-
计算实际旋转步数:
- 旋转
k次实际上等效于旋转k % count次,因为旋转count次会回到原链表。所以需要计算实际需要旋转的步数:count - k % count。
- 旋转
-
找到新的头节点并断开环:
- 使用指针
q和p一起向前移动count - k % count步。在这一过程中,q会指向新的头节点,p会指向新的尾节点。 - 断开环,将
p的next指向NULL,这样就得到了旋转后的链表。
- 使用指针
-
返回新的头节点:
- 返回
q,即旋转后的链表头节点。
- 返回
翻转代码:
struct ListNode* rotateRight(struct ListNode* head, int k) {
// 如果 k 为 0,或者链表为空,或者链表只有一个节点,直接返回原链表
if (k == 0 || head == NULL || head->next == NULL) return head;
struct ListNode* p, *q;
int a = 0;
int count = 0;
// 初始化 p 和 q 指向链表头
q = p = head;
// 计算链表的长度
while (p->next) {
p = p->next;
count++;
}
count = count + 1; // 加上最后一个节点
// 将链表首尾相连,形成一个环
p->next = head;
// 计算实际需要移动的步数
// 因为旋转 k 次相当于旋转 k % count 次
while (a < count - k % count) {
q = q->next;
p = p->next;
a++;
}
// 断开环,q 指向新的头节点
p->next = NULL;
return q;
}完整的运行代码:
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构
struct ListNode {
int value; // 节点的值
struct ListNode* next; // 指向下一个节点的指针
};
// 创建新节点的函数
struct ListNode* create_node(int value) {
struct ListNode* new_node = (struct ListNode*)malloc(sizeof(struct ListNode)); // 分配内存
new_node->value = value; // 设置节点的值
new_node->next = NULL; // 初始化指针为 NULL
return new_node; // 返回新创建的节点
}
// 旋转链表的函数
struct ListNode* rotateRight(struct ListNode* head, int k) {
// 如果旋转次数为 0,链表为空或者仅有一个节点,直接返回原链表
if (k == 0 || head == NULL || head->next == NULL) {
return head;
}
struct ListNode* p; // 用于遍历链表
struct ListNode* q; // 用于找到新的头节点
int a = 0; // 当前计数器
int count = 0; // 链表的总长度
// 初始化 p 和 q 指向头节点
q = p = head;
// 计算链表的长度 count
while (p->next) { // 遍历链表直到最后一个节点
p = p->next; // 移动到下一个节点
count++; // 增加节点计数
}
count = count + 1; // 包括最后一个节点
// 将链表首尾相连,形成一个环
p->next = head;
// 找到新的尾节点和新的头节点
// 新的尾节点应该是 count - k % count 位置的节点
while (a < count - k % count) {
q = q->next; // 移动 q 直到新的头节点
p = p->next; // 移动 p 到尾节点
a++; // 计数加一
}
// 断开环,将新的尾节点的 next 设为 NULL
p->next = NULL;
// 返回新的头节点
return q;
}
// 打印链表的函数
void print_list(struct ListNode* head) {
struct ListNode* current = head; // 当前节点初始化为头节点
while (current != NULL) { // 遍历链表
printf("%d -> ", current->value); // 打印当前节点的值
current = current->next; // 移动到下一个节点
}
printf("NULL\n"); // 打印链表结束标志
}
// 示例代码
int main() {
// 创建链表 1 -> 2 -> 3 -> 4 -> 5
struct ListNode* head = create_node(1); // 创建第一个节点
head->next = create_node(2); // 创建第二个节点
head->next->next = create_node(3); // 创建第三个节点
head->next->next->next = create_node(4); // 创建第四个节点
head->next->next->next->next = create_node(5); // 创建第五个节点
int k = 2; // 设定旋转的步数
// 打印旋转前的链表
printf("旋转前的链表: ");
print_list(head);
// 旋转链表
head = rotateRight(head, k);
// 打印旋转后的链表
printf("旋转后的链表: ");
print_list(head);
// 释放链表的内存
struct ListNode* temp;
while (head != NULL) {
temp = head;
head = head->next;
free(temp);
}
return 0; // 程序结束
}2两个有序表的合并
1. 顺序存储(数组)的合并
在顺序存储中,我们假设两个数组都是有序的(升序),然后将它们合并成一个新的有序数组。
#include <stdio.h>
#include <stdlib.h>
// 合并两个有序表
int* mergeOrderedLists(int* list1, int size1, int* list2, int size2) {
// 为合并后的列表动态分配内存
int* mergedList = (int*)malloc((size1 + size2) * sizeof(int));
int i = 0, j = 0, k = 0;
// 当两个列表都未遍历完时
while (i < size1 && j < size2) {
// 如果列表 1 的当前元素小于列表 2 的当前元素
if (list1[i] < list2[j]) {
// 将列表 1 的当前元素放入合并后的列表
mergedList[k++] = list1[i++];
} else {
// 将列表 2 的当前元素放入合并后的列表
mergedList[k++] = list2[j++];
}
}
// 如果列表 1 还有剩余元素,将其放入合并后的列表
while (i < size1) {
mergedList[k++] = list1[i++];
}
// 如果列表 2 还有剩余元素,将其放入合并后的列表
while (j < size2) {
mergedList[k++] = list2[j++];
}
// 返回合并后的列表
return mergedList;
}
int main() {
int list1[] = {1, 3, 5, 7, 9};
int list2[] = {2, 4, 6, 8, 10};
int size1 = sizeof(list1) / sizeof(list1[0]);
int size2 = sizeof(list2) / sizeof(list2[0]);
int* merged = mergeOrderedLists(list1, size1, list2, size2);
// 输出合并后的列表
for (int i = 0; i < size1 + size2; i++) {
printf("%d ", merged[i]);
}
// 释放动态分配的内存
free(merged);
return 0;
}2链式存储的合并方法
假设我们有两个有序链表,我们将它们合并成一个有序链表。
#include <stdio.h>
#include <stdlib.h>
#include <string.h> // 修改为 <string.h> 以引用C标准库
// 定义链表节点结构
typedef struct ListNode {
int data; // 节点存储的数据
struct ListNode* next; // 指向下一个节点的指针
} ListNode;
// 创建新节点
ListNode* createNode(int value) {
ListNode* newNode = (ListNode*)malloc(sizeof(ListNode)); // 分配内存
newNode->data = value; // 初始化节点数据
newNode->next = NULL; // 设置下一个指针为 NULL
return newNode; // 返回新节点的指针
}
// 合并两个有序链表
ListNode* mergeOrderedLists(ListNode* list1, ListNode* list2) {
ListNode dummy; // 创建一个虚拟节点,便于处理头节点
ListNode* head = &dummy; // 指针 head 初始化为虚拟节点
// 遍历两个链表,直到一个链表遍历结束
while (list1 && list2) {
if (list1->data < list2->data) { // 比较两个链表的当前节点数据
head->next = list1; // 将较小的节点链接到合并链表
list1 = list1->next; // 移动 list1 指针到下一个节点
} else {
head->next = list2; // 将较小的节点链接到合并链表
list2 = list2->next; // 移动 list2 指针到下一个节点
}
head = head->next; // 移动合并链表的指针
}
// 将剩余的链表连接到合并链表末尾
head->next = list1 ? list1 : list2;
return dummy.next; // 返回合并后的链表头指针(去除虚拟节点)
}
// 打印链表
void printList(ListNode* head) {
while (head) { // 遍历链表
printf("%d ", head->data); // 打印当前节点的数据
head = head->next; // 移动到下一个节点
}
printf("\n"); // 打印换行
}
// 释放链表内存
void freeList(ListNode* head) {
ListNode* temp;
while (head) { // 遍历链表
temp = head; // 保存当前节点
head = head->next; // 移动到下一个节点
free(temp); // 释放当前节点的内存
}
}
int main() {
// 创建第一个有序链表
ListNode* list1 = createNode(1);
list1->next = createNode(3);
list1->next->next = createNode(5);
list1->next->next->next = createNode(7);
list1->next->next->next->next = createNode(9);
// 创建第二个有序链表
ListNode* list2 = createNode(2);
list2->next = createNode(4);
list2->next->next = createNode(6);
list2->next->next->next = createNode(8);
list2->next->next->next->next = createNode(10);
// 合并两个链表
ListNode* mergedList = mergeOrderedLists(list1, list2);
// 打印合并后的链表
printf("合并后的链表: ");
printList(mergedList);
// 释放内存
freeList(mergedList);
return 0; // 程序结束
}3删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
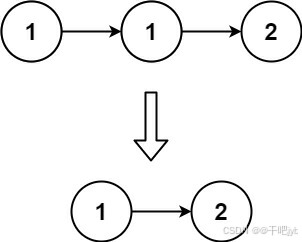
输入:head = [1,1,2] 输出:[1,2]
示例 2:
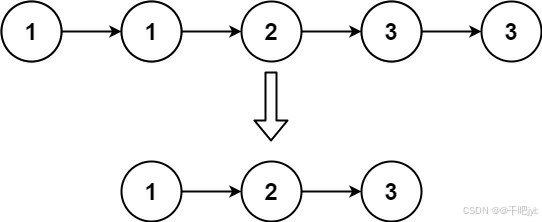
输入:head = [1,1,2,3,3] 输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
思路:
-
空链表处理:
- 首先检查链表是否为空 (
if (!head) return head;)。如果链表为空,直接返回head。
- 首先检查链表是否为空 (
-
遍历链表:
- 使用一个指针
cur初始化为链表的头节点head。 - 从
cur开始遍历链表,直到cur->next为NULL(即遍历到链表的最后一个节点)。
- 使用一个指针
-
检查重复元素:
- 在遍历过程中,检查
cur节点的值是否与cur->next节点的值相同 (if (cur->val == cur->next->val))。 - 如果相同,说明
cur->next是一个重复节点,需要跳过它。通过cur->next = cur->next->next直接将cur->next指向下一个节点的下一个节点,从而删除cur->next节点。 - 如果不同,说明当前节点没有重复,继续遍历下一个节点 (
cur = cur->next)。
- 在遍历过程中,检查
-
返回结果:
- 遍历结束后,所有重复的元素都已经被删除,链表中每个元素只出现一次。
- 返回链表的头节点
head。
删除重复元素代码:
struct ListNode* deleteDuplicates(struct ListNode* head) {
// 如果链表为空,直接返回
if (!head) {
return head;
}
// 定义当前节点指针
struct ListNode* cur = head;
// 遍历链表
while (cur->next) {
// 如果当前节点的值与下一个节点的值相等
if (cur->val == cur->next->val) {
// 将当前节点的下一个指针指向下下个节点,即删除下一个重复节点
cur->next = cur->next->next;
} else {
// 如果不相等,移动当前节点指针到下一个节点
cur = cur->next;
}
}
// 返回处理后的链表头指针
return head;
}
完整代码:
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构
struct ListNode {
int val; // 节点的值
struct ListNode* next; // 指向下一个节点的指针
};
// 删除链表中重复的元素
struct ListNode* deleteDuplicates(struct ListNode* head) {
// 如果链表为空,直接返回空
if (!head) {
return head;
}
// 定义一个指针,指向当前遍历的节点,初始指向头节点
struct ListNode* cur = head;
// 遍历链表,直到最后一个节点
while (cur->next) {
// 如果当前节点的值和下一个节点的值相等,说明有重复
if (cur->val == cur->next->val) {
// 将当前节点的 next 指针跳过下一个节点,从而删除下一个节点
cur->next = cur->next->next;
} else {
// 如果没有重复,则继续遍历下一个节点
cur = cur->next;
}
}
// 返回链表的头节点
return head;
}
// 示例:创建链表并测试 deleteDuplicates 函数
int main() {
// 手动创建一个链表 1 -> 1 -> 2 -> 3 -> 3
struct ListNode* head = malloc(sizeof(struct ListNode));
head->val = 1;
head->next = malloc(sizeof(struct ListNode));
head->next->val = 1;
head->next->next = malloc(sizeof(struct ListNode));
head->next->next->val = 2;
head->next->next->next = malloc(sizeof(struct ListNode));
head->next->next->next->val = 3;
head->next->next->next->next = malloc(sizeof(struct ListNode));
head->next->next->next->next->val = 3;
head->next->next->next->next->next = NULL;
// 调用 deleteDuplicates 函数删除重复元素
head = deleteDuplicates(head);
// 输出处理后的链表
struct ListNode* temp = head;
while (temp) {
printf("%d -> ", temp->val);
temp = temp->next;
}
printf("NULL\n");
// 释放内存
while (head) {
struct ListNode* temp = head;
head = head->next;
free(temp);
}
return 0;
}
















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









