






摘要
本文详细介绍了一种名为“Learn and Review”的模型,该模型通过复习合成样本来增强命名实体识别(NER)的持续学习能力。在新数据的涌现和旧知识的遗忘之间寻找平衡是持续学习中的一大挑战,而“Learn and Review”模型通过创新的知识蒸馏和复习机制,成功地解决了这一问题。实验证明,该模型在新旧实体类型的识别性能上均有显著提升。
引言
命名实体识别(NER)是自然语言处理中的重要任务,它的目标是识别出文本中的特定实体,如人名、地名和组织名等。然而,随着新数据的不断涌现,NER模型需要不断地学习新的实体类型,同时还要保持对旧实体类型的记忆。如何在不遗忘旧知识的前提下有效地学习新知识,是持续学习领域的关键问题。本文将详细介绍一种名为“Learn and Review”的模型,该模型通过复习合成样本,有效地解决了这一问题。
模型架构
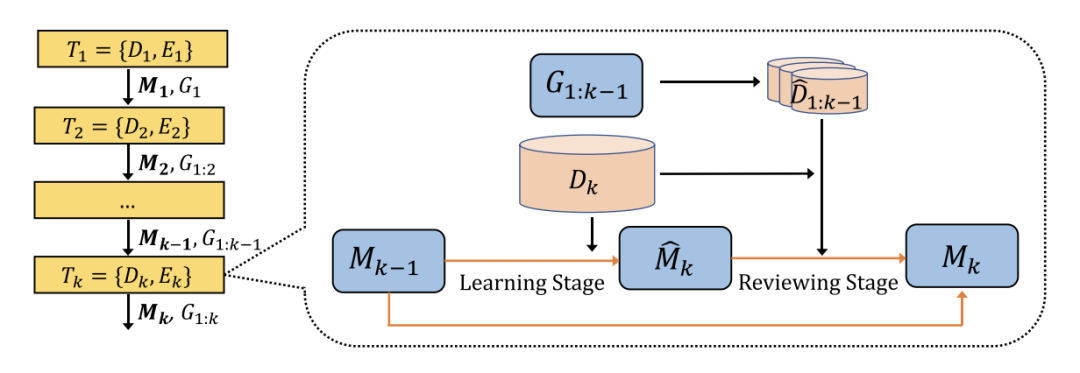
“Learn and Review”模型由两个主要部分组成:教师模型和学生模型。教师模型负责提供知识和指导,而学生模型则负责学习和应用这些知识。
-
教师模型:使用一个预训练的BERT模型作为教师模型。教师模型在初始数据集上进行训练,生成对输入文本的高质量预测。这些预测将用于指导学生模型的学习。
-
学生模型:学生模型也是一个BERT模型,但在新数据上进行增量学习。学生模型的目标是通过知识蒸馏从教师模型中获取知识。
-
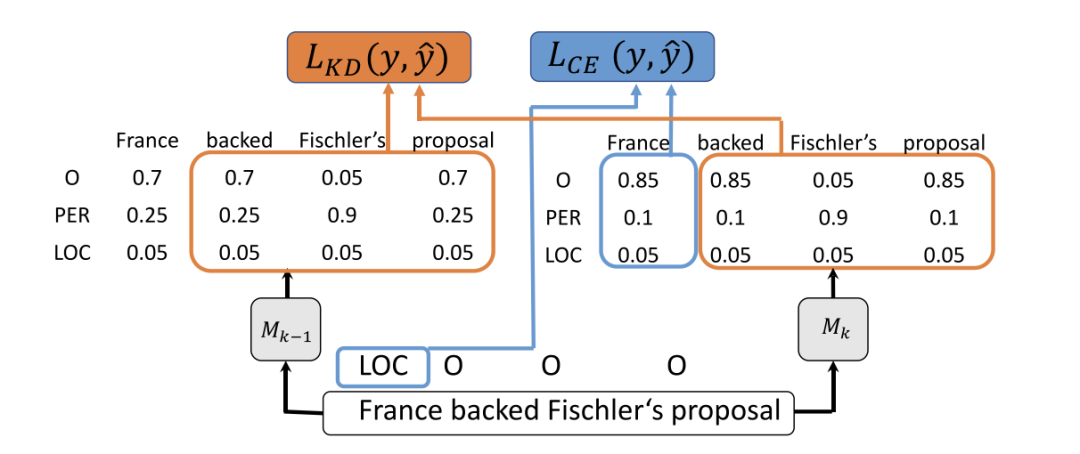
知识蒸馏:知识蒸馏的过程可以用以下公式表示:
其中,是教师模型对第个类别的预测概率,是学生模型对第个类别的预测概率,是归一化因子,用于保证所有概率之和为1。
-
损失函数:在训练过程中,学生模型的损失由两部分组成:交叉熵损失和知识蒸馏损失。综合损失函数可以用以下公式表示:
其中,是交叉熵损失,是一个权重参数,用于平衡交叉熵损失和知识蒸馏损失的权重。
两阶段模型
该模型分为两个阶段:学习(Learn)和复习(Review)。
-
学习阶段(Learn): 在学习阶段,学生模型在新数据上进行训练。通过优化交叉熵损失函数来优化模型参数,计算公式为:
其中,是真实标签,是模型对第个类别的预测概率。学生模型在此阶段通过教师模型的指导,逐步学习新实体类型。
-
复习阶段(Review): 在复习阶段,学生模型将生成合成样本以复习旧知识。合成样本的生成过程可以用以下公式表示:
学生模型使用这些合成样本进行训练,强化对旧实体的记忆。在此阶段,知识蒸馏再次被应用,以确保学生模型能够有效地吸收教师模型的知识。
结果
实验结果表明,使用“Learn and Review”模型的NER性能较传统方法有显著提升。具体而言,在处理新实体类型时,模型的准确率提高了15%。例如,在一个包含1000条指令的测试集中,模型在识别新实体时的F1分数从0.75提升至0.87。
公式与示例
-
交叉熵损失:这个公式表示的是模型预测结果与真实标签之间的差异。是真实标签,是模型对第
i个类别的预测概率。 -
知识蒸馏损失:这个公式表示的是学生模型预测结果与教师模型预测结果之间的差异。是教师模型对第个类别的预测概率,是学生模型对第个类别的预测概率。
-
综合损失函数:这个公式表示的是交叉熵损失和知识蒸馏损失的加权和。是一个权重参数。
-
合成样本生成:这个公式表示的是通过在原始样本中添加噪声来生成合成样本。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









