






1.哈希表的定义:
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
即:
- 哈希表又叫散列表
- 哈希表是一个数据结构
- 哈希表是数组结构
1.1几个重要概念:
-
散列函数(Hash function):一个将任意长度的二进制值映射为较短的、固定长度的二进制值的函数。在哈希表中,这个函数用于将关键码值映射到表中一个位置(即散列地址),以便直接访问记录。
-
散列表(Hash table):存放记录的数组,通过散列函数将关键码值映射到表中的位置。
-
哈希冲突(Hash collision):不同的关键字通过相同的哈希数计算出相同的哈希地址的现象。也就是说,k1 ≠ k2,但 f(k1) = f(k2)。
-
同义词(Synonym):具有相同函数值的关键字对散列函数来说称做同义词。
-
均匀散列函数(Uniform Hash function):如果对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数。它有助于减少哈希冲突。
-
哈希表的主要操作:
- 插入元素:使用哈希函数计算元素的关键码值对应的存储位置,并将元素存储在该位置。
- 查找元素:使用哈希函数计算元素的关键码值对应的存储位置,然后检查该位置是否有相应的元素。
- 删除元素:找到元素的存储位置,并将其从表中删除。
-
哈希表的时间复杂度:哈希表的时间复杂度通常是O(1),这意味着无论哈希表中有多少元素,插入、查找和删除操作都可以在常数时间内完成。但这取决于哈希函数的选择和冲突解决策略。
-
冲突解决策略:
- 闭散列(开放定址法):当发生哈希冲突时,如果哈希表未被装满,说明哈希表中还有空位置,那么将出现冲突的元素存放在下一个空位置中。查找空位置的方法包括线性探测和二次探测。
- 开散列(链地址法):为哈希表的每一个存储位置创建一个链表,所有哈希地址相同的元素都添加到同一个链表中。
2.map,hash_map,unordered_map的区别:
2.1map:
- 底层基于红黑树实现的有序的关联容器。
- 元素按照键值进行排序,且不允许键值重复。
- 查找、插入和删除操作时间复杂度为O(log n)。
2.2hash_map:
- 使用哈希表实现的关联容器。但标准C++中已不推荐使用,建议使用unordered_map代替。
- 元素的排列顺序与键的哈希值有关。
- STL没有提供hash_map,但是一些第三方库或C++的扩展库中可能会提供。
2.3unordered_map:
- 使用哈希表实现的无序的关联容器。
- 元素存储的顺序与元素的键的哈希值无关。
- 查找、插入和删除操作时间复杂度为O(1)。unordered_map是C++11引入的新容器。
综上所述,map是有序的关联容器,hash_map是废弃的使用哈希表实现的关联容器,unordered_map是无序的使用哈希表实现的关联容器。unordered_map在查找、插入和删除操作上有更优秀的性能。
在哈希表(Hash Table)中,Map是一个重要的概念,它通常指的是一种存储键值对(Key-Value Pair)的数据结构。哈希表通过散列函数(Hash Function)将键(Key)映射到存储位置,以实现快速查找和访问数据。
具体来说,Map在哈希表中的作用是存储和管理键值对。每个键值对由一个唯一的键和一个与之对应的值组成。Map中的键用于标识和定位数据,而值则是与键相关联的数据。
在编程中,Map通常是一个接口或类,它定义了一系列方法来操作键值对数据。例如,你可以使用put()方法向Map中添加键值对,使用get()方法根据键获取对应的值,使用remove()方法删除指定的键值对,以及使用containsKey()和containsValue()等方法检查Map中是否包含特定的键或值。
哈希表中的Map与普通的Map数据结构有所不同。在哈希表中,Map通过散列函数将键映射到存储位置,以实现高效的查找和访问。这意味着当你向哈希表添加键值对时,哈希表会根据键的散列值将其存储到相应的位置。当你需要访问某个键对应的值时,哈希表可以直接通过计算键的散列值来找到存储位置,从而快速获取值。
需要注意的是,哈希表中的Map可能会遇到哈希冲突(Hash Collision)的问题。当两个或多个不同的键具有相同的散列值时,就会发生哈希冲突。为了解决这个问题,哈希表通常会使用一些策略来处理冲突,如链地址法(Chaining)或开放寻址法(Open Addressing)等。
总之,哈希表中的Map是一个用于存储和管理键值对的数据结构,它通过散列函数将键映射到存储位置以实现高效的查找和访问。在编程中,你可以使用各种Map实现类来操作和管理哈希表中的键值对数据。
2.4一些重要参数:
- 默认初始容量为16
- 最大长度为2的30次幂
- 默认加载因子为0.75
- 当链表节点小于等于6,自动退化成链表
- 当链表节点大于等于8,长度大于64时进行变化成红黑树
- 扩容阈值,当你的hashmap中的元素个数超过这个阈值,便会发生扩容
- threshold = capacity * loadFactor
2.5扩容
其中initailCapacity是初始容量:默认值为16
在计算存入结点下标时,会利用 key 的 hsah 值进行取余操作,而计算机计算时,并没有取余等运算,会将取余转化为其他运算;当HashMap中的元素越来越多的时候,碰撞的几率也就越来越高,所以为了提高查询的效率,就要对HashMap的数组进行扩容;具体来说,就是当hashmap中的元素个数大于数组中的元素个数(16*0.75=12)就需要扩容,即将16*2=32;
2.6具体语法
#include <map>
//map 生成
map<key_type, value_type> name;
map<int, int> mp;
//map 迭代器
map<int, int>::iterator iter
mp.begin()
mp.end()
//map 键值
iter->first //key
iter->second //value
//map 插入
mp[2] = 5; //直接添加
mp.insert(pair<int, int>(2, 5)); //insert一个pair
//删除
mp.erase(iter); //删除迭代器所指的键值对
//map 容量
mp.size()
//map 查找
mp.find(2) //从前往后找,若找到,返回指向该处的迭代器;反之,返回迭代器mp.end()
//map 某元素个数
st.count(2); //返回key为2的个数(map中只可能是0或者1)
//map 判空
mp.empty() //返回布尔值
//map 清空
mp.clear();
2.7应用实例
2.7.1求多数元素
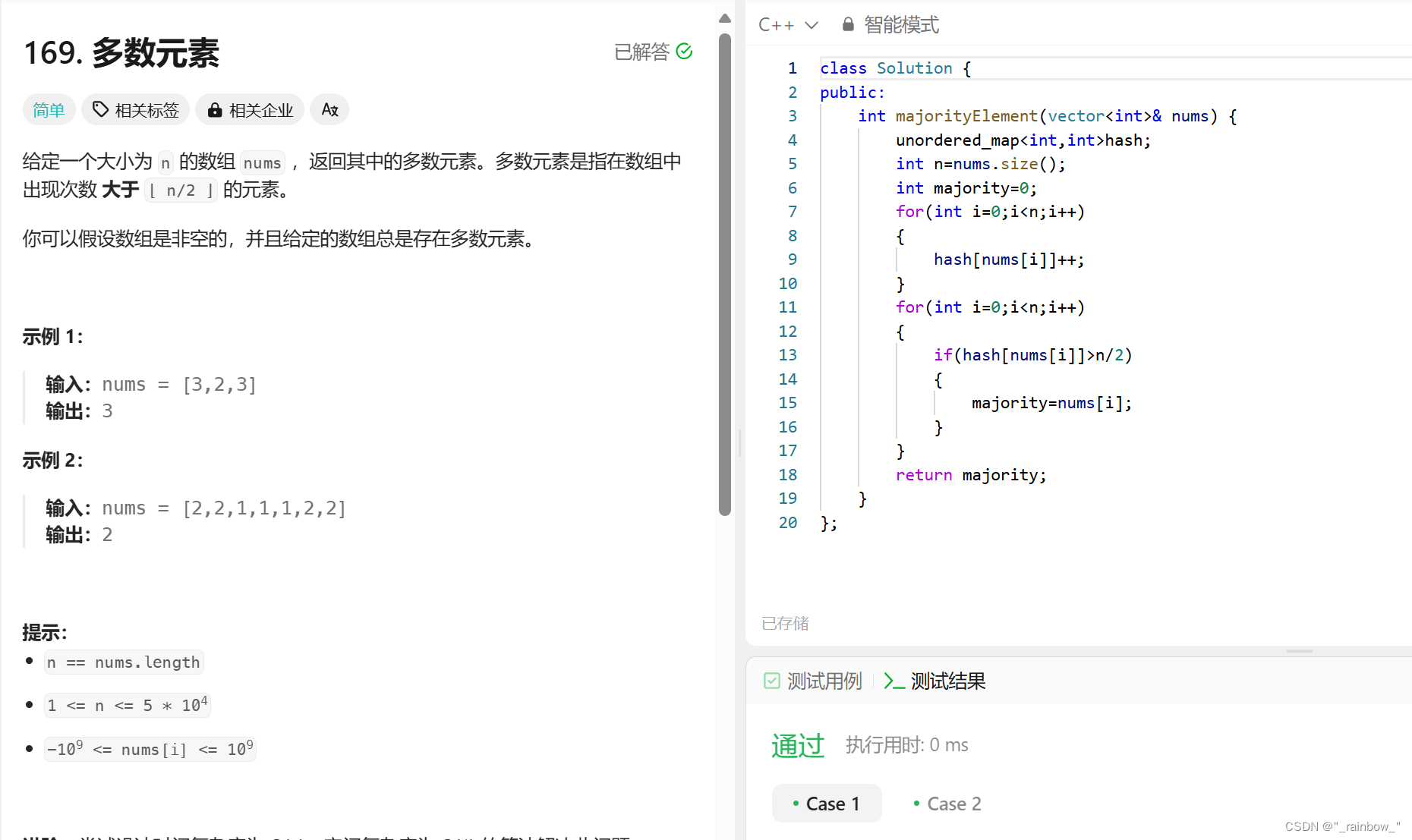
class Solution {
public:
int majorityElement(vector<int>& nums) {
unordered_map<int,int>hash;
int n=nums.size();
int majority=0;
for(int i=0;i<n;i++)
{
hash[nums[i]]++;
}
for(int i=0;i<n;i++)
{
if(hash[nums[i]]>n/2)
{
majority=nums[i];
}
}
return majority;
}
};2.7.2快乐数
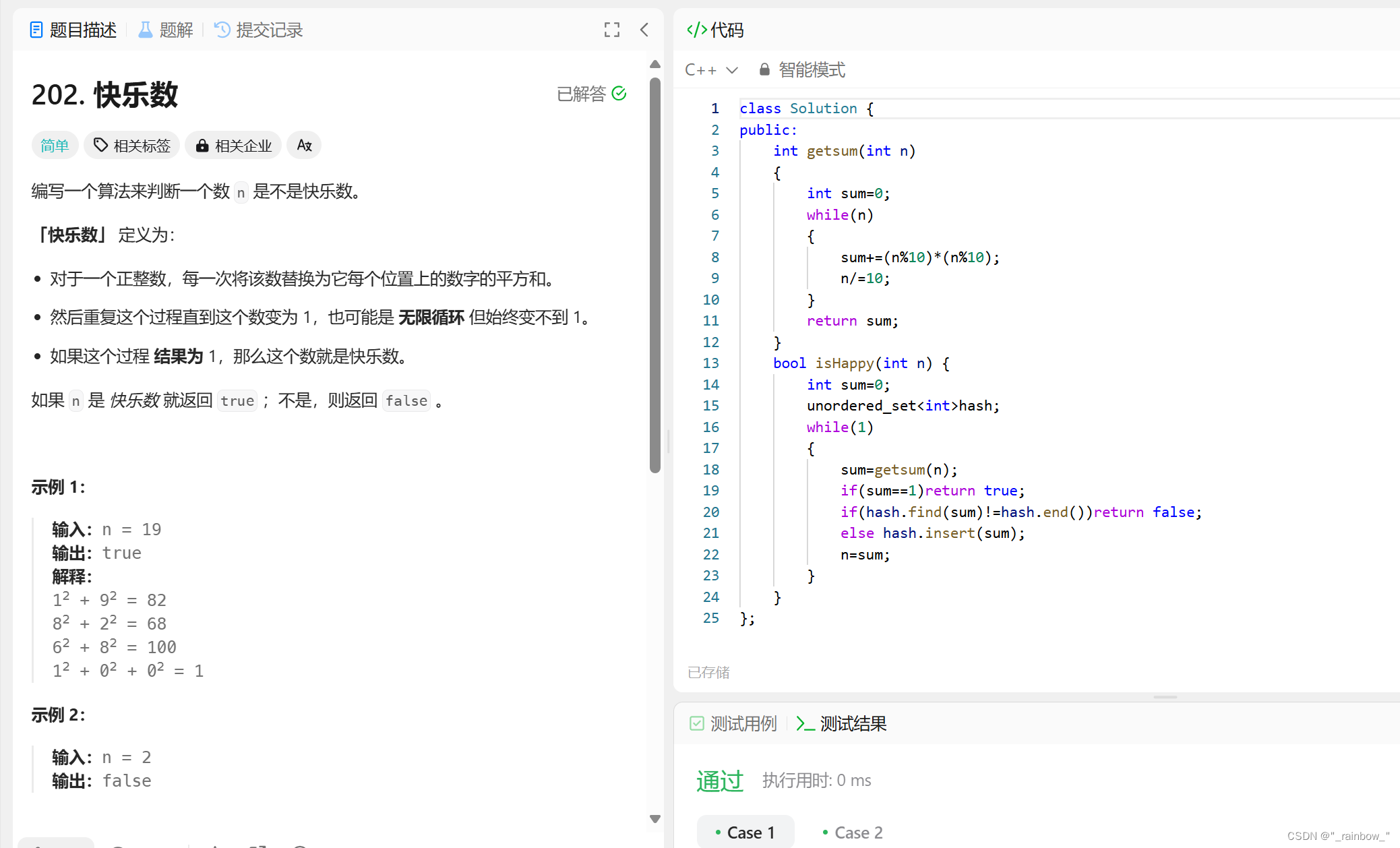
class Solution {
public:
int getsum(int n)
{
int sum=0;
while(n)
{
sum+=(n%10)*(n%10);
n/=10;
}
return sum;
}
bool isHappy(int n) {
int sum=0;
unordered_set<int>hash;
while(1)
{
sum=getsum(n);
if(sum==1)return true;
if(hash.find(sum)!=hash.end())return false;
else hash.insert(sum);
n=sum;
}
}
};注意:hash.find(sum)!=hash.end()是指在哈希表中找sum,如果找到了则表示sum之前出现过,return false。
`hash.find()` 是用于在哈希表(例如 `unordered_map`)中查找指定键的方法。它接受一个键作为参数,并返回一个迭代器,指向包含该键的元素,如果找不到该键,则返回指向哈希表末尾的迭代器。这个方法的作用是用于在哈希表中搜索指定键是否存在,并返回对应的位置或者标识不存在。


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









