









一、非监督学习的含义
非监督学习是机器学习的另一种类型,它使用没有标签的原始数据来训练模型,目标是从数据中自动发现结构、模式或关系。因为没有“答案”可参考,算法就像是在自己摸索和学习。
通俗理解:
这就像你在看一堆没有标准答案的题目(比如几十篇文章或图片),你开始自己归类,比如“这些是讲科技的,那些是关于旅游的”,“这些图片颜色相近,那些结构类似”——你没有老师告诉你哪个是对的,但你通过观察发现了规律和分组方式。
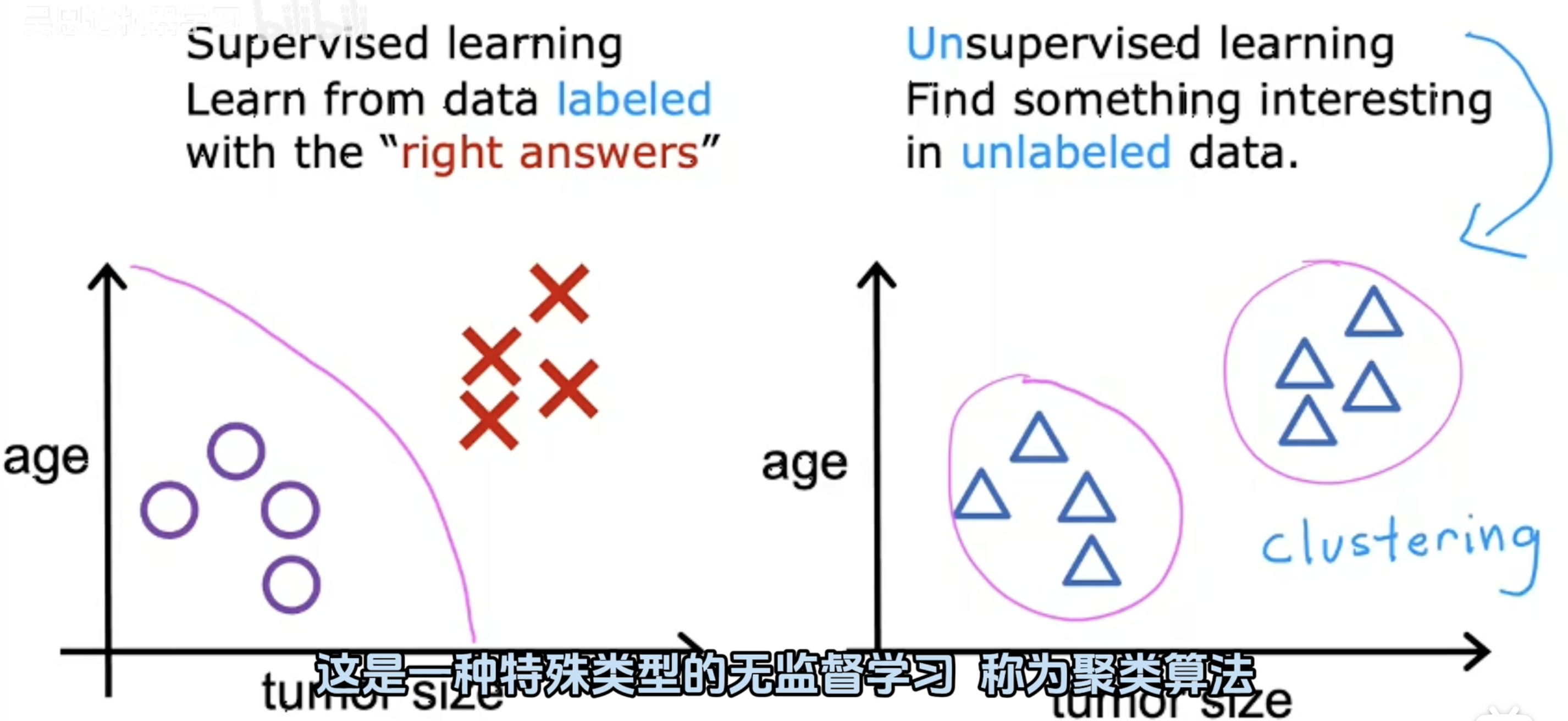
监督学习和非监督学习的区别
监督学习(Supervised Learning)
-
监督学习使用带有标签的数据进行训练,模型通过学习这些标签来预测新数据的标签。图中左侧展示了监督学习,模型试图找到一个决策边界来区分不同的类别。
非监督学习(Unsupervised Learning)
-
非监督学习处理未标记的数据,目标是发现数据中的结构或模式。图中右侧展示了非监督学习的一个例子——聚类。聚类算法将数据点分组,使得同一组内的数据点相似,而不同组之间的数据点差异较大。这种分组有助于揭示数据的内在结构,无需预先定义的标签。
二、非监督学习的主要类型

🔵 Clustering(聚类)
非监督学习中的聚类是一种将无标签的数据根据其内在特征和相似性自动分组的技术。它的目标是让相似的数据点归为一类,不同的数据点分到不同的组中,从而发现数据中的结构或模式。聚类不依赖先验标签,而是通过算法自主识别数据之间的关系。
例子(一)
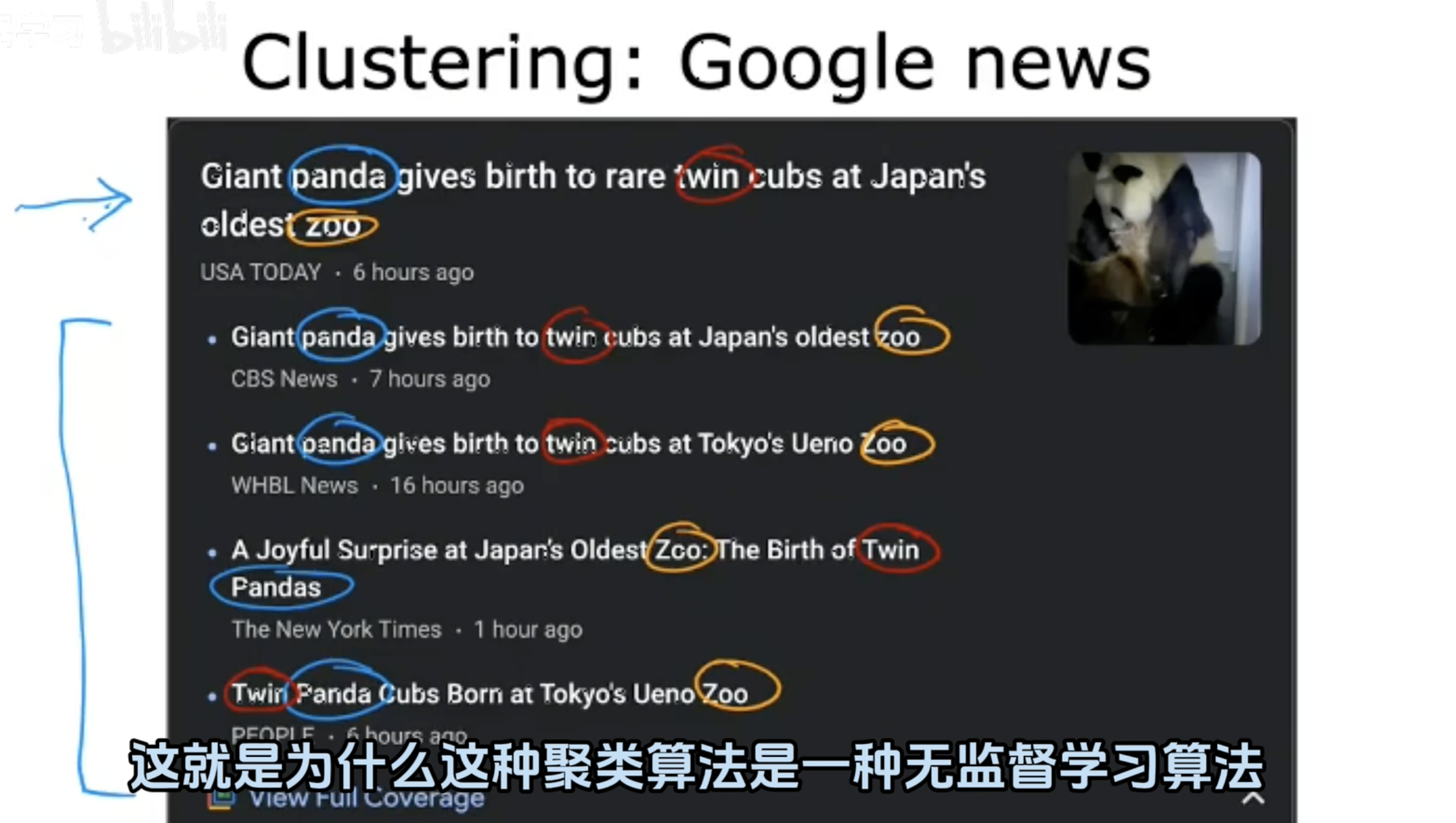
🖼️ 图解说明
-
标题
Google news
“谷歌新闻”
-
抓取新闻
系统会实时抓取各大媒体(如纽约时报、CNN等)发布的新闻标题和内容。 -
快速识别关键信息
算法会快速扫描每条新闻,提取核心关键词,比如:
"Giant panda"(大熊猫)
"twin cubs"(双胞胎幼崽)
"Ueno Zoo"(上野动物园)
"birth"(生产)
-
自动匹配相似新闻
如果发现多条新闻都包含这些相同的关键词组合,就会认为它们在讲同一件事,于是归为一类。 -
呈现给用户
最终会看到:同一个事件的不同报道被整齐地归在一起,方便一次看完所有相关报道。
例子(二)

🖼️ 图解说明
-
标题
DNA microarray
“DNA微阵列”
-
数据长什么样?
-
每一行 = 一个基因(比如基因P53、BRCA1…)
-
每一列 = 一个样本(比如病人A、病人B…或不同实验组)
-
格子里的数值 = 这个基因在对应样本中的表达量(可以理解为基因的“活跃程度”)。
-
聚类的目标
-
对基因聚类(图中标注的genes (each row))
→ 找出行为相似的基因(比如同时高表达或低表达的基因组)。 -
对样本聚类(图中标注的individuals)
→ 找出基因表达模式相似的样本(比如可能患同种疾病的病人分组)。
-
聚类如何操作?
计算相似性
-
比较基因之间的表达模式:如果基因X和基因Y在所有样本中的表达量变化趋势一致(同升同降),它们就被认为是相似的。
-
比较样本之间的基因表达谱:如果病人A和病人B的大多数基因表达水平接近,他们可能属于同一组。
自动分组
-
算法会根据相似性,把基因或样本分成若干组(图中types1、types2等)。
例子(三)
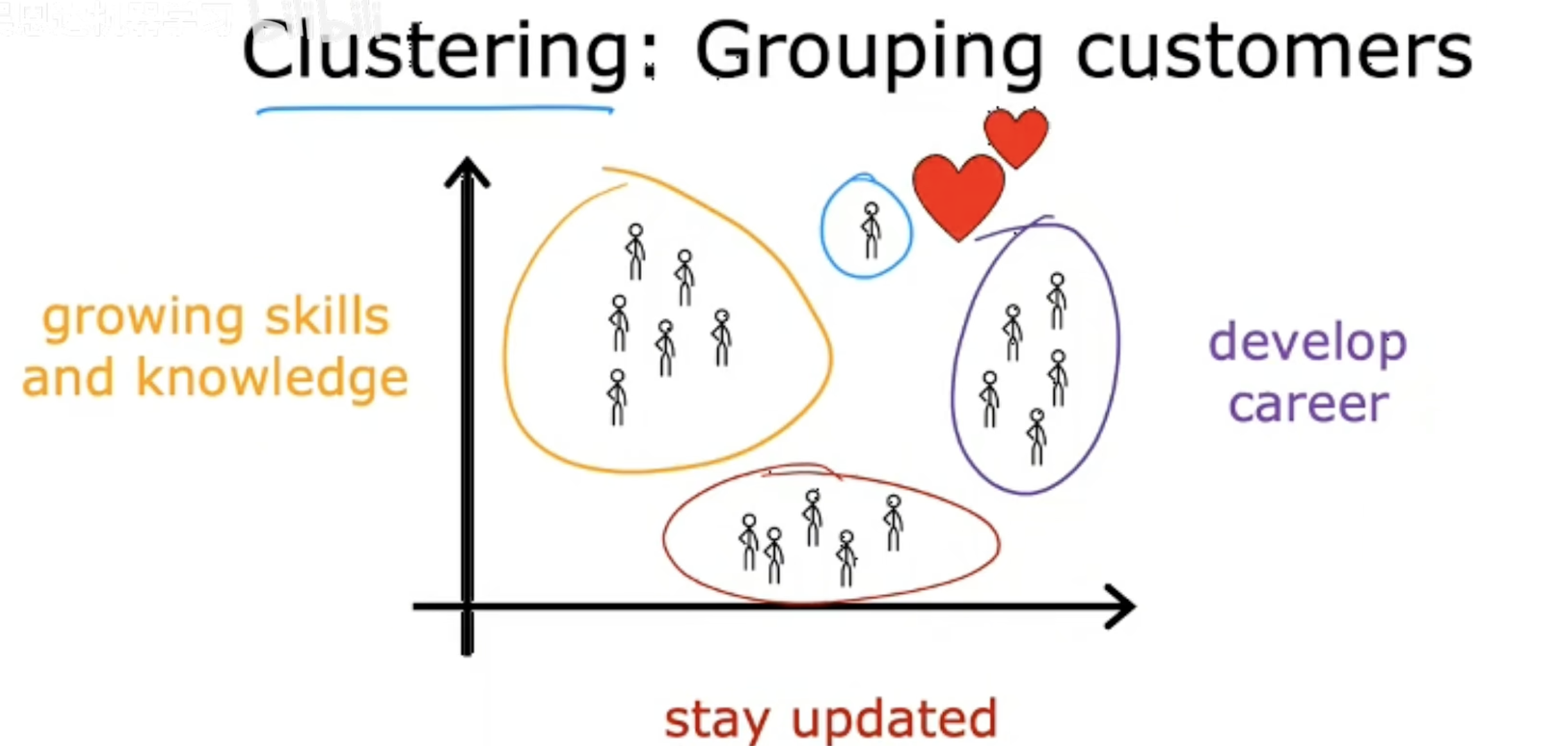
🖼️ 图解说明
-
标题
Grouping customers
“客户分组”
-
数据是什么?
-
每一行代表一个客户(或用户)。
-
每一列代表客户的特征或行为,比如:
-
"growing skills"(技能提升需求)
-
"and knowledge"(知识学习需求)
-
"develop career"(职业发展需求)
-
"stay updated"(保持行业更新需求)
-
-
数据可能是用户的调查问卷结果、APP行为日志、购买记录等。
-
聚类的目标
-
将客户分成不同的群组,每组客户在需求或行为上高度相似。
-
例如:
-
群组1:强烈关注“职业发展”和“技能提升”的职场新人。
-
群组2:主要想“保持行业更新”的资深从业者。
-
群组3:均衡关注所有需求的多面手。
-
-
聚类如何操作?
提取特征
-
从原始数据中量化客户的需求强度(比如评分、频率统计等)。
-
例如:
-
用户A:
["growing skills": 高, "develop career": 高, "stay updated": 低] -
用户B:
["growing skills": 低, "develop career": 中, "stay updated": 高]
-
计算相似性
-
用算法比较客户之间的特征相似度。
-
如果两个客户在“技能提升”“职业发展”等需求上打分接近,他们会被归为同一组。
自动分组
-
算法输出分群结果(如图中可能的
Group 1/2/3)。
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









