







主要参考的资料如下:
深入理解堆的实现 - CTF Wiki (ctf-wiki.org)
目录
下一块不是 top chunk - 前向合并 - 合并高地址 chunk
下一块是 top chunk - 合并到 top chunk
- 宏观角度
-
- 创建堆
- 堆初始化
- 删除堆
- 微观角度
-
- 申请内存块
- 释放内存块
基础操作
unlink
unlink 用来将一个双向链表(只存储空闲的 chunk)中的一个元素取出来,可能在以下地方使用
- malloc
-
- 从恰好大小合适的 large bin 中获取 chunk。
-
-
- 这里需要注意的是 fastbin 与 small bin 就没有使用 unlink,这就是为什么漏洞会经常出现在它们这里的原因。
- 依次遍历处理 unsorted bin 时也没有使用 unlink 。
-
-
- 从比请求的 chunk 所在的 bin 大的 bin 中取 chunk。
- free
-
- 后向合并,合并物理相邻低地址空闲 chunk。
- 前向合并,合并物理相邻高地址空闲 chunk(除了 top chunk)。
- malloc_consolidate
-
- 后向合并,合并物理相邻低地址空闲 chunk。
- 前向合并,合并物理相邻高地址空闲 chunk(除了 top chunk)。
- realloc
-
- 前向扩展,合并物理相邻高地址空闲 chunk(除了 top chunk)。
"unlink" 攻击的一般步骤:
- 准备攻击者控制的数据: 攻击者首先需要有一种方式,例如堆溢出漏洞,来覆写已分配堆块的头部。攻击者会将一些控制数据写入这个堆块的头部,包括修改 fd 和 bk 指针。
- 构造伪造的链表节点: 攻击者构造一个伪造的链表节点,使用已经被攻击者控制的数据。具体来说,攻击者将 fd 和 bk 指针设置为攻击者控制的地址,使得这个堆块看起来像链表中的一个节点。
- 调用模拟 unlink 操作: 攻击者通过调用一些与内存分配/释放相关的函数(通常是 free 函数),触发 glibc 内部的类似于 unlink 操作的过程。这个过程会删除链表中的一个节点,但是由于链表结构被伪造,实际上是在破坏堆管理结构。
- 绕过堆管理检查: 由于 unlink 操作中的链表结构被破坏,攻击者可能绕过了 glibc 堆管理器的检查。这样,攻击者可以在之后的内存分配/释放操作中执行非法的内存读写。
- 执行恶意操作: 攻击者现在可以利用已经破坏的堆管理结构执行一些恶意的操作,比如读取或写入一些敏感的数据。
堆溢出覆盖,模拟一个unlink攻击
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct Chunk{
size_t prev_size;
size_t size;
struct Chunk *fd;
struct Chunk *bk;
}Chunk;
int main()
{
char input[41];
memset(input,'A',sizeof(input));
input[41] = '\0';
Chunk *chunk1 = (Chunk *)malloc(16);
Chunk *chunk2 = (Chunk *)malloc(16);
printf("%zu\n",chunk2->size);
printf("%p\n",chunk2->fd);
strcpy(((char *)chunk1+16), input);
printf("%zu\n",chunk2->size);
printf("%p\n",chunk2->fd);
} 
由于 unlink 使用非常频繁,所以 unlink 被实现为了一个宏,如下
/* Take a chunk off a bin list */
// unlink p
#define unlink(AV, P, BK, FD) { \
// 由于 P 已经在双向链表中,所以有两个地方记录其大小,所以检查一下其大小是否一致。
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) \
malloc_printerr ("corrupted size vs. prev_size"); \
FD = P->fd; \
BK = P->bk; \
// 防止攻击者简单篡改空闲的 chunk 的 fd 与 bk 来实现任意写的效果。
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
else { \
FD->bk = BK; \
BK->fd = FD; \
// 下面主要考虑 P 对应的 nextsize 双向链表的修改
if (!in_smallbin_range (chunksize_nomask (P)) \
// 如果P->fd_nextsize为 NULL,表明 P 未插入到 nextsize 链表中。
// 那么其实也就没有必要对 nextsize 字段进行修改了。
// 这里没有去判断 bk_nextsize 字段,可能会出问题。
&& __builtin_expect (P->fd_nextsize != NULL, 0)) { \
// 类似于小的 chunk 的检查思路
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr (check_action, \
"corrupted double-linked list (not small)", \
P, AV); \
// 这里说明 P 已经在 nextsize 链表中了。
// 如果 FD 没有在 nextsize 链表中
if (FD->fd_nextsize == NULL) { \
// 如果 nextsize 串起来的双链表只有 P 本身,那就直接拿走 P
// 令 FD 为 nextsize 串起来的
if (P->fd_nextsize == P) \
FD->fd_nextsize = FD->bk_nextsize = FD; \
else { \
// 否则我们需要将 FD 插入到 nextsize 形成的双链表中
FD->fd_nextsize = P->fd_nextsize; \
FD->bk_nextsize = P->bk_nextsize; \
P->fd_nextsize->bk_nextsize = FD; \
P->bk_nextsize->fd_nextsize = FD; \
} \
} else { \
// 如果在的话,直接拿走即可
P->fd_nextsize->bk_nextsize = P->bk_nextsize; \
P->bk_nextsize->fd_nextsize = P->fd_nextsize; \
} \
} \
} \
}
这段代码实现了一个名为 unlink 的宏,主要用于将一个空闲的内存块从双向链表中移除。这个操作通常在堆管理的 free 函数中被调用。下面对这个宏的主要步骤进行详细解释:
cCopy code
#define unlink(AV, P, BK, FD) { \
if (__builtin_expect(chunksize(P) != prev_size(next_chunk(P)), 0)) \
malloc_printerr("corrupted size vs. prev_size"); \
FD = P->fd; \
BK = P->bk; \
if (__builtin_expect(FD->bk != P || BK->fd != P, 0)) \
malloc_printerr(check_action, "corrupted double-linked list", P, AV); \
else { \
FD->bk = BK; \
BK->fd = FD; \
if (!in_smallbin_range(chunksize_nomask(P)) \
&& __builtin_expect(P->fd_nextsize != NULL, 0)) { \
if (__builtin_expect(P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect(P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr(check_action, "corrupted double-linked list (not small)", P, AV); \
if (FD->fd_nextsize == NULL) { \
if (P->fd_nextsize == P) \
FD->fd_nextsize = FD->bk_nextsize = FD; \
else { \
FD->fd_nextsize = P->fd_nextsize; \
FD->bk_nextsize = P->bk_nextsize; \
P->fd_nextsize->bk_nextsize = FD; \
P->bk_nextsize->fd_nextsize = FD; \
} \
} else { \
P->fd_nextsize->bk_nextsize = P->bk_nextsize; \
P->bk_nextsize->fd_nextsize = P->fd_nextsize; \
} \
} \
} \
}- 检查块大小的一致性:
-
- 使用 __builtin_expect 宏来表达块大小是否与其后一个块的前一个大小相等的条件。这里使用 chunksize 和 prev_size 函数来获取块的大小和前一个块的大小。
- 获取前向和后向指针:
-
- FD 被设置为块 P 的前向指针,BK 被设置为块 P 的后向指针。
- 检查链表的完整性:
-
- 使用 __builtin_expect 来表达检查 FD 和 BK 是否正确的条件,以防止链表被恶意篡改。如果条件不满足,调用 malloc_printerr 报告错误。
- 更新前向和后向指针:
-
- 如果链表完整,将 FD 的 bk 设置为 BK,将 BK 的 fd 设置为 FD,从而将块 P 从双向链表中移除。
- 处理 nextsize 链表:
-
- 如果块 P 不在小型块范围内并且有 nextsize 链表,检查并进行相应的 nextsize 链表操作。这一部分主要是确保链表的完整性。
这里我们以 small bin 的 unlink 为例子介绍一下。对于 large bin 的 unlink,与其类似,只是多了一个 nextsize 的处理。
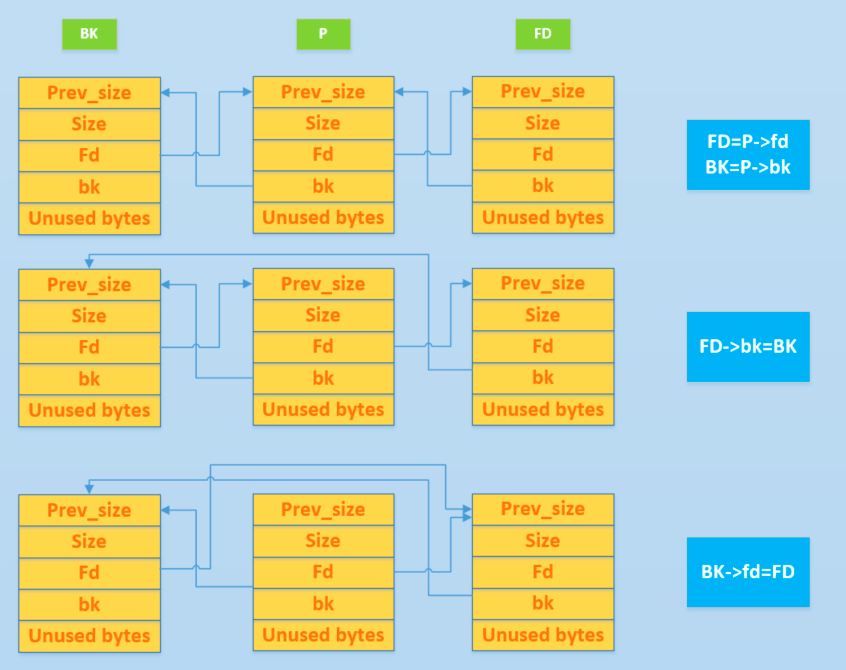
可以看出, P 最后的 fd 和 bk 指针并没有发生变化,但是当我们去遍历整个双向链表时,已经遍历不到对应的链表了。这一点没有变化还是很有用处的,因为我们有时候可以使用这个方法来泄漏地址
- libc 地址
-
- P 位于双向链表头部,bk 泄漏
- P 位于双向链表尾部,fd 泄漏
- 双向链表只包含一个空闲 chunk 时,P 位于双向链表中,fd 和 bk 均可以泄漏
- 泄漏堆地址,双向链表包含多个空闲 chunk
-
- P 位于双向链表头部,fd 泄漏
- P 位于双向链表中,fd 和 bk 均可以泄漏
- P 位于双向链表尾部,bk 泄漏
注意
- 这里的头部指的是 bin 的 fd 指向的 chunk,即双向链表中最新加入的 chunk。
- 这里的尾部指的是 bin 的 bk 指向的 chunk,即双向链表中最先加入的 chunk。
那我把一个空闲块申请下来,完整的申请下来,这个前后指针,会被删除吗?
当你通过 malloc 或类似的分配函数申请一个空闲块时,堆管理器会返回给你一块连续的内存,这块内存是已经分离(不再属于空闲块链表)的,因此不包含前向和后向指针。你获得的是一块纯粹的连续内存,只包含用户数据和管理信息。
在这种情况下,已经分配给用户的内存块不再与空闲块链表相关联,因此不会包含用于链表管理的前向和后向指针。这也意味着用户获得的内存块不会影响堆管理器内部的空闲块链表结构。
堆管理器会在内部维护一个链表结构,用于跟踪空闲块。当你释放这个内存块时(使用 free 函数),它将重新成为空闲块,并可能会被重新插入到相应大小的空闲块链表中,具体取决于堆管理器的实现。此时,前向和后向指针等链表信息可能会重新出现在该块中。
bin是一个结构还是一块存储空间
在堆内存管理中,“bin”通常是指一个数据结构,用于组织和管理相似大小的空闲内存块。这个数据结构通常是一个链表或数组,其中的每个节点表示一个特定大小的空闲块链表。这个结构被用于高效地查找和管理可用的内存块,以便满足不同大小的分配请求。
具体而言,一个“bin”包含:
- 链表节点或数组元素: 用于表示一个特定大小类别的空闲块链表。这个节点通常包含一些管理信息,如前向和后向指针,以及可能的其他信息。
- 空闲块链表: 存储相同大小类别的空闲内存块。这些空闲块在链表中连接,以便在分配和释放操作中能够高效地查找适当大小的内存块。
“Bin”本身并不是一块存储空间,而是一种组织和管理内存的结构。这个结构可以是链表、数组或其他形式,具体取决于堆管理器的实现。在 glibc 堆管理器中,有多个不同大小的“bins”(如 small bins、large bins、unsorted bins 等),每个“bin”对应一种大小的内存块链表。
同时,无论是对于 fd,bk 还是 fd_nextsize ,bk_nextsize,程序都会检测 fd 和 bk 是否满足对应的要求。
// fd bk
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
// next_size related
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr (check_action, \
"corrupted double-linked list (not small)", \
P, AV);看起来似乎很正常。我们以 fd 和 bk 为例,P 的 forward chunk 的 bk 很自然是 P ,同样 P 的 backward chunk 的 fd 也很自然是 P 。如果没有做相应的检查的话,我们可以修改 P 的 fd 与 bk,从而可以很容易地达到任意地址写的效果。关于更加详细的例子,可以参见利用部分的 unlink 。
注意:堆的第一个 chunk 所记录的 prev_inuse 位默认为 1。
malloc_printerr
在 glibc malloc 时检测到错误的时候,会调用 malloc_printerr 函数。
static void malloc_printerr(const char *str) {
__libc_message(do_abort, "%s\n", str);
__builtin_unreachable();
}主要会调用 __libc_message 来执行abort 函数,如下
if ((action & do_abort)) {
if ((action & do_backtrace))
BEFORE_ABORT(do_abort, written, fd);
/* Kill the application. */
abort();
}在abort 函数里,在 glibc 还是 2.23 版本时,会 fflush stream。
/* Flush all streams. We cannot close them now because the user
might have registered a handler for SIGABRT. */
if (stage == 1)
{
++stage;
fflush (NULL);
}堆初始化
堆初始化是在用户第一次申请内存时执行 malloc_consolidate 再执行 malloc_init_state 实现的。
1.malloc_consolidate 是用于合并相邻的空闲块,
以减少内存碎片,提高内存利用率的操作。这通常在堆的初始化阶段执行,以确保堆的初始状态较为整洁,并有助于后续的内存分配和释放操作。
2.malloc_init_state: 这个函数用于初始化堆管理器的状态,包括初始化各个空闲块链表(bins)等。堆管理器在内部维护了一些数据结构,用于跟踪不同大小类别的空闲块,并提供高效的内存分配。malloc_init_state 在堆初始化时设置这些数据结构,以便后续的内存分配和释放操作能够更快速地定位适当大小的内存块。
申请内存块
__libc_malloc
一般我们会使用 malloc 函数来申请内存块,可是当仔细看 glibc 的源码实现时,其实并没有 malloc 函数。其实该函数真正调用的是 __libc_malloc 函数。为什么不直接写个 malloc 函数呢,因为有时候我们可能需要不同的名称。此外,__libc_malloc 函数只是用来简单封装 _int_malloc 函数。_int_malloc 才是申请内存块的核心。下面我们来仔细分析一下具体的实现。
该函数会首先检查是否有内存分配函数的钩子函数(__malloc_hook),这个主要用于用户自定义的堆分配函数,方便用户快速修改堆分配函数并进行测试。
__malloc_hook
__malloc_hook 是 glibc 中的一个钩子函数,用于拦截 malloc 函数的调用。通过使用这个钩子,开发者可以在程序运行时修改或监控内存分配的行为。
具体而言,__malloc_hook 是一个函数指针,它指向一个用户定义的函数。当程序执行 malloc 函数时,glibc 将检查是否设置了 __malloc_hook,如果设置了,就会调用这个用户定义的函数而不是标准的 malloc。这允许开发者在内存分配时注入自定义的逻辑。
这里需要注意的是,用户申请的字节一旦进入申请内存函数中就变成了无符号整数。
// wapper for int_malloc
void *__libc_malloc(size_t bytes) {
mstate ar_ptr;
void * victim;
// 检查是否有内存分配钩子,如果有,调用钩子并返回.
void *(*hook)(size_t, const void *) = atomic_forced_read(__malloc_hook);
if (__builtin_expect(hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS(0));接着会寻找一个 arena 来试图分配内存。
arena_get(ar_ptr, bytes);然后调用 _int_malloc 函数去申请对应的内存。
victim = _int_malloc(ar_ptr, bytes);如果分配失败的话,ptmalloc 会尝试再去寻找一个可用的 arena,并分配内存。
/* Retry with another arena only if we were able to find a usable arena
before. */
if (!victim && ar_ptr != NULL) {
LIBC_PROBE(memory_malloc_retry, 1, bytes);
ar_ptr = arena_get_retry(ar_ptr, bytes);
victim = _int_malloc(ar_ptr, bytes);
}如果申请到了 arena,那么在退出之前还得解锁。
if (ar_ptr != NULL) __libc_lock_unlock(ar_ptr->mutex);判断目前的状态是否满足以下条件
- 要么没有申请到内存
- 要么是 mmap 的内存
- 要么申请到的内存必须在其所分配的 arena 中
assert(!victim || chunk_is_mmapped(mem2chunk(victim)) ||
ar_ptr == arena_for_chunk(mem2chunk(victim)));最后返回内存。
return victim;
}_int_malloc
_int_malloc 是内存分配的核心函数,其核心思路有如下
- 它根据用户申请的内存块大小以及相应大小 chunk 通常使用的频度(fastbin chunk, small chunk, large chunk),依次实现了不同的分配方法。
- 它由小到大依次检查不同的 bin 中是否有相应的空闲块可以满足用户请求的内存。
- 当所有的空闲 chunk 都无法满足时,它会考虑 top chunk。
- 当 top chunk 也无法满足时,堆分配器才会进行内存块申请。
在进入该函数后,函数立马定义了一系列自己需要的变量,并将用户申请的内存大小转换为内部的 chunk 大小。
static void *_int_malloc(mstate av, size_t bytes) {
INTERNAL_SIZE_T nb; /* normalized request size */
unsigned int idx; /* associated bin index */
mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */
INTERNAL_SIZE_T size; /* its size */
int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */
unsigned long remainder_size; /* its size */
unsigned int block; /* bit map traverser */
unsigned int bit; /* bit map traverser */
unsigned int map; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */
mchunkptr bck; /* misc temp for linking */
const char *errstr = NULL;
/*
Convert request size to internal form by adding SIZE_SZ bytes
overhead plus possibly more to obtain necessary alignment and/or
to obtain a size of at least MINSIZE, the smallest allocatable
size. Also, checked_request2size traps (returning 0) request sizes
that are so large that they wrap around zero when padded and
aligned.
*/
checked_request2size(bytes, nb);arena
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from
mmap. */
if (__glibc_unlikely(av == NULL)) {
void *p = sysmalloc(nb, av);
if (p != NULL) alloc_perturb(p, bytes);
return p;
}fast bin
如果申请的 chunk 的大小位于 fastbin 范围内,需要注意的是这里比较的是无符号整数。此外,是从 fastbin 的头结点开始取 chunk。
/*
If the size qualifies as a fastbin, first check corresponding bin.
This code is safe to execute even if av is not yet initialized, so we
can try it without checking, which saves some time on this fast path.
*/
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast())) {
// 得到对应的fastbin的下标
idx = fastbin_index(nb);
// 得到对应的fastbin的头指针
mfastbinptr *fb = &fastbin(av, idx);
mchunkptr pp = *fb;
// 利用fd遍历对应的bin内是否有空闲的chunk块,
do {
victim = pp;
if (victim == NULL) break;
} while ((pp = catomic_compare_and_exchange_val_acq(fb, victim->fd,
victim)) != victim);
// 存在可以利用的chunk
if (victim != 0) {
// 检查取到的 chunk 大小是否与相应的 fastbin 索引一致。
// 根据取得的 victim ,利用 chunksize 计算其大小。
// 利用fastbin_index 计算 chunk 的索引。
if (__builtin_expect(fastbin_index(chunksize(victim)) != idx, 0)) {
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr(check_action, errstr, chunk2mem(victim), av);
return NULL;
}
// 细致的检查。。只有在 DEBUG 的时候有用
check_remalloced_chunk(av, victim, nb);
// 将获取的到chunk转换为mem模式
void *p = chunk2mem(victim);
// 如果设置了perturb_type, 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}
}small bin
如果获取的内存块的范围处于 small bin 的范围,那么执行如下流程
/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/
if (in_smallbin_range(nb)) {
// 获取 small bin 的索引
idx = smallbin_index(nb);
// 获取对应 small bin 中的 chunk 指针
bin = bin_at(av, idx);
// 先执行 victim = last(bin),获取 small bin 的最后一个 chunk
// 如果 victim = bin ,那说明该 bin 为空。
// 如果不相等,那么会有两种情况
if ((victim = last(bin)) != bin) {
// 第一种情况,small bin 还没有初始化。
if (victim == 0) /* initialization check */
// 执行初始化,将 fast bins 中的 chunk 进行合并
malloc_consolidate(av);
// 第二种情况,small bin 中存在空闲的 chunk
else {
// 获取 small bin 中倒数第二个 chunk 。
bck = victim->bk;
// 检查 bck->fd 是不是 victim,防止伪造
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
// 设置 victim 对应的 inuse 位
set_inuse_bit_at_offset(victim, nb);
// 修改 small bin 链表,将 small bin 的最后一个 chunk 取出来
bin->bk = bck;
bck->fd = bin;
// 如果不是 main_arena,设置对应的标志
if (av != &main_arena) set_non_main_arena(victim);
// 细致的检查,非调试状态没有作用
check_malloced_chunk(av, victim, nb);
// 将申请到的 chunk 转化为对应的 mem 状态
void *p = chunk2mem(victim);
// 如果设置了 perturb_type , 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}
}
}large bin
当 fast bin、small bin 中的 chunk 都不能满足用户请求 chunk 大小时,就会考虑是不是 large bin。但是,其实在 large bin 中并没有直接去扫描对应 bin 中的 chunk,而是先利用 malloc_consolidate(参见 malloc_state 相关函数) 函数处理 fast bin 中的 chunk,将有可能能够合并的 chunk 先进行合并后放到 unsorted bin 中,不能够合并的就直接放到 unsorted bin 中,然后再在下面的大循环中进行相应的处理。为什么不直接从相应的 bin 中取出 large chunk 呢?这是 ptmalloc 的机制,它会在分配 large chunk 之前对堆中碎片 chunk 进行合并,以便减少堆中的碎片。
/*
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
*/
else {
// 获取large bin的下标。
idx = largebin_index(nb);
// 如果存在fastbin的话,会处理 fastbin
if (have_fastchunks(av)) malloc_consolidate(av);
}大循环 - 遍历 unsorted bin
如果程序执行到了这里,那么说明 与 chunk 大小正好一致的 bin (fast bin, small bin) 中没有 chunk 可以直接满足需求 ,但是 large chunk 则是在这个大循环中处理。
在接下来的这个循环中,主要做了以下的操作
- 按照 FIFO 的方式逐个将 unsorted bin 中的 chunk 取出来
-
- 如果是 small request,则考虑是不是恰好满足,是的话,直接返回。
- 如果不是的话,放到对应的 bin 中。
- 尝试从 large bin 中分配用户所需的内存
该部分是一个大循环,这是为了尝试重新分配 small bin chunk,这是因为我们虽然会首先使用 large bin,top chunk 来尝试满足用户的请求,但是如果没有满足的话,由于我们在上面没有分配成功 small bin,我们并没有对 fast bin 中的 chunk 进行合并,所以这里会进行 fast bin chunk 的合并,进而使用一个大循环来尝试再次分配 small bin chunk。
/*
Process recently freed or remaindered chunks, taking one only if
it is exact fit, or, if this a small request, the chunk is remainder from
the most recent non-exact fit. Place other traversed chunks in
bins. Note that this step is the only place in any routine where
chunks are placed in bins.
The outer loop here is needed because we might not realize until
near the end of malloc that we should have consolidated, so must
do so and retry. This happens at most once, and only when we would
otherwise need to expand memory to service a "small" request.
*/
for (;;) {
int iters = 0;unsorted bin 遍历
先考虑 unsorted bin,再考虑 last remainder ,但是对于 small bin chunk 的请求会有所例外。
注意 unsorted bin 的遍历顺序为 bk。
// 如果 unsorted bin 不为空
// First In First Out
while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) {
// victim 为 unsorted bin 的最后一个 chunk
// bck 为 unsorted bin 的倒数第二个 chunk
bck = victim->bk;
// 判断得到的 chunk 是否满足要求,不能过小,也不能过大
// 一般 system_mem 的大小为132K
if (__builtin_expect(chunksize_nomask(victim) <= 2 * SIZE_SZ, 0) ||
__builtin_expect(chunksize_nomask(victim) > av->system_mem, 0))
malloc_printerr(check_action, "malloc(): memory corruption",
chunk2mem(victim), av);
// 得到victim对应的chunk大小。
size = chunksize(victim);SMALL REQUEST
如果用户的请求为 small bin chunk,那么我们首先考虑 last remainder,如果 last remainder 是 unsorted bin 中的唯一一块的话, 并且 last remainder 的大小分割后还可以作为一个 chunk ,为什么没有等号?
这里没有等号的情况可能是为了强调排除等于的情况。也就是说,仅在 last remainder 是 unsorted bin 中的唯一一块且大小适合分割时,执行某些处理逻辑。这样的设计可能是为了确保逻辑在特定情况下执行,而不包括其他可能的情况。
/*
If a small request, try to use last remainder if it is the
only chunk in unsorted bin. This helps promote locality for
runs of consecutive small requests. This is the only
exception to best-fit, and applies only when there is
no exact fit for a small chunk.
*/
if (in_smallbin_range(nb) && bck == unsorted_chunks(av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE)) {
/* split and reattach remainder */
// 获取新的 remainder 的大小
remainder_size = size - nb;
// 获取新的 remainder 的位置
remainder = chunk_at_offset(victim, nb);
// 更新 unsorted bin 的情况
unsorted_chunks(av)->bk = unsorted_chunks(av)->fd = remainder;
// 更新 av 中记录的 last_remainder
av->last_remainder = remainder;
// 更新last remainder的指针
remainder->bk = remainder->fd = unsorted_chunks(av);
if (!in_smallbin_range(remainder_size)) {
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
// 设置victim的头部,
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
// 设置 remainder 的头部
set_head(remainder, remainder_size | PREV_INUSE);
// 设置记录 remainder 大小的 prev_size 字段,因为此时 remainder 处于空闲状态。
set_foot(remainder, remainder_size);
// 细致的检查,非调试状态下没有作用
check_malloced_chunk(av, victim, nb);
// 将 victim 从 chunk 模式转化为mem模式
void *p = chunk2mem(victim);
// 如果设置了perturb_type, 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}初始取出
/* remove from unsorted list */
unsorted_chunks(av)->bk = bck;
bck->fd = unsorted_chunks(av);EXACT FIT
如果从 unsorted bin 中取出来的 chunk 大小正好合适,就直接使用。这里应该已经把合并后恰好合适的 chunk 给分配出去了。
/* Take now instead of binning if exact fit */
if (size == nb) {
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena) set_non_main_arena(victim);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
alloc_perturb(p, bytes);
return p;
}PLACE CHUNK IN SMALL BIN
把取出来的 chunk 放到对应的 small bin 中。
/* place chunk in bin */
if (in_smallbin_range(size)) {
victim_index = smallbin_index(size);
bck = bin_at(av, victim_index);
fwd = bck->fd;PLACE CHUNK IN LARGE BIN
把取出来的 chunk 放到对应的 large bin 中。
} else {
// large bin 范围
victim_index = largebin_index(size);
bck = bin_at(av, victim_index); // 当前 large bin 的头部
fwd = bck->fd;
/* maintain large bins in sorted order */
/* 从这里我们可以总结出,largebin 以 fd_nextsize 递减排序。
同样大小的 chunk,后来的只会插入到之前同样大小的 chunk 后,
而不会修改之前相同大小的fd/bk_nextsize,这也很容易理解,
可以减低开销。此外,bin 头不参与 nextsize 链接。*/
// 如果 large bin 链表不空
if (fwd != bck) {
/* Or with inuse bit to speed comparisons */
// 加速比较,应该不仅仅有这个考虑,因为链表里的 chunk 都会设置该位。
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
// bck->bk 存储着相应 large bin 中最小的chunk。
// 如果遍历的 chunk 比当前最小的还要小,那就只需要插入到链表尾部。
// 判断 bck->bk 是不是在 main arena。
assert(chunk_main_arena(bck->bk));
if ((unsigned long) (size) <
(unsigned long) chunksize_nomask(bck->bk)) {
// 令 fwd 指向 large bin 头
fwd = bck;
// 令 bck 指向 largin bin 尾部 chunk
bck = bck->bk;
// victim 的 fd_nextsize 指向 largin bin 的第一个 chunk
victim->fd_nextsize = fwd->fd;
// victim 的 bk_nextsize 指向原来链表的第一个 chunk 指向的 bk_nextsize
victim->bk_nextsize = fwd->fd->bk_nextsize;
// 原来链表的第一个 chunk 的 bk_nextsize 指向 victim
// 原来指向链表第一个 chunk 的 fd_nextsize 指向 victim
fwd->fd->bk_nextsize =
victim->bk_nextsize->fd_nextsize = victim;
} else {
// 当前要插入的 victim 的大小大于最小的 chunk
// 判断 fwd 是否在 main arena
assert(chunk_main_arena(fwd));
// 从链表头部开始找到不比 victim 大的 chunk
while ((unsigned long) size < chunksize_nomask(fwd)) {
fwd = fwd->fd_nextsize;
assert(chunk_main_arena(fwd));
}
// 如果找到了一个和 victim 一样大的 chunk,
// 那就直接将 chunk 插入到该chunk的后面,并不修改 nextsize 指针。
if ((unsigned long) size ==
(unsigned long) chunksize_nomask(fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
else {
// 如果找到的chunk和当前victim大小不一样
// 那么就需要构造 nextsize 双向链表了
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
}
} else
// 如果空的话,直接简单使得 fd_nextsize 与 bk_nextsize 构成一个双向链表即可。
victim->fd_nextsize = victim->bk_nextsize = victim;
}最终取出
// 放到对应的 bin 中,构成 bck<-->victim<-->fwd。
mark_bin(av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;WHILE 迭代次数
while 最多迭代 10000 次后退出。
// #define MAX_ITERS 10000
if (++iters >= MAX_ITERS) break;
}large chunk
注: 或许会很奇怪,为什么这里没有先去看 small chunk 是否满足新需求了呢?这是因为 small bin 在循环之前已经判断过了,这里如果有的话,就是合并后的才出现 chunk。但是在大循环外,large chunk 只是单纯地找到其索引,所以觉得在这里直接先判断是合理的,而且也为了下面可以再去找较大的 chunk。
如果请求的 chunk 在 large chunk 范围内,就在对应的 bin 中从小到大进行扫描,找到第一个合适的。
/*
If a large request, scan through the chunks of current bin in
sorted order to find smallest that fits. Use the skip list for this.
*/
if (!in_smallbin_range(nb)) {
bin = bin_at(av, idx);
/* skip scan if empty or largest chunk is too small */
// 如果对应的 bin 为空或者其中的chunk最大的也很小,那就跳过
// first(bin)=bin->fd 表示当前链表中最大的chunk
if ((victim = first(bin)) != bin &&
(unsigned long) chunksize_nomask(victim) >=
(unsigned long) (nb)) {
// 反向遍历链表,直到找到第一个不小于所需chunk大小的chunk
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize(victim)) <
(unsigned long) (nb)))
victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
// 如果最终取到的chunk不是该bin中的最后一个chunk,并且该chunk与其前面的chunk
// 的大小相同,那么我们就取其前面的chunk,这样可以避免调整bk_nextsize,fd_nextsize
// 链表。因为大小相同的chunk只有一个会被串在nextsize链上。
if (victim != last(bin) &&
chunksize_nomask(victim) == chunksize_nomask(victim->fd))
victim = victim->fd;
// 计算分配后剩余的大小
remainder_size = size - nb;
// 进行unlink
unlink(av, victim, bck, fwd);
/* Exhaust */
// 剩下的大小不足以当做一个块
// 很好奇接下来会怎么办?
if (remainder_size < MINSIZE) {
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena) set_non_main_arena(victim);
}
/* Split */
// 剩下的大小还可以作为一个chunk,进行分割。
else {
// 获取剩下那部分chunk的指针,称为remainder
remainder = chunk_at_offset(victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
// 插入unsorted bin中
bck = unsorted_chunks(av);
fwd = bck->fd;
// 判断 unsorted bin 是否被破坏。
if (__glibc_unlikely(fwd->bk != bck)) {
errstr = "malloc(): corrupted unsorted chunks";
goto errout;
}
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
// 如果不处于small bin范围内,就设置对应的字段
if (!in_smallbin_range(remainder_size)) {
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
// 设置分配的chunk的标记
set_head(victim,
nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
// 设置remainder的上一个chunk,即分配出去的chunk的使用状态
// 其余的不用管,直接从上面继承下来了
set_head(remainder, remainder_size | PREV_INUSE);
// 设置remainder的大小
set_foot(remainder, remainder_size);
}
// 检查
check_malloced_chunk(av, victim, nb);
// 转换为mem状态
void *p = chunk2mem(victim);
// 如果设置了perturb_type, 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}
}寻找较大 chunk
如果走到了这里,那说明对于用户所需的 chunk,不能直接从其对应的合适的 bin 中获取 chunk,所以我们需要来查找比当前 bin 更大的 fast bin , small bin 或者 large bin。
/*
Search for a chunk by scanning bins, starting with next largest
bin. This search is strictly by best-fit; i.e., the smallest
(with ties going to approximately the least recently used) chunk
that fits is selected.
The bitmap avoids needing to check that most blocks are nonempty.
The particular case of skipping all bins during warm-up phases
when no chunks have been returned yet is faster than it might look.
*/
++idx;
// 获取对应的bin
bin = bin_at(av, idx);
// 获取当前索引在binmap中的block索引
// #define idx2block(i) ((i) >> BINMAPSHIFT) ,BINMAPSHIFT=5
// Binmap按block管理,每个block为一个int,共32个bit,可以表示32个bin中是否有空闲chunk存在
// 所以这里是右移5
block = idx2block(idx);
// 获取当前块大小对应的映射,这里可以得知相应的bin中是否有空闲块
map = av->binmap[ block ];
// #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT) - 1))))
// 将idx对应的比特位设置为1,其它位为0
bit = idx2bit(idx);
for (;;) {找到一个合适的 MAP
/* Skip rest of block if there are no more set bits in this block.
*/
// 如果bit>map,则表示该 map 中没有比当前所需要chunk大的空闲块
// 如果bit为0,那么说明,上面idx2bit带入的参数为0。
if (bit > map || bit == 0) {
do {
// 寻找下一个block,直到其对应的map不为0。
// 如果已经不存在的话,那就只能使用top chunk了
if (++block >= BINMAPSIZE) /* out of bins */
goto use_top;
} while ((map = av->binmap[ block ]) == 0);
// 获取其对应的bin,因为该map中的chunk大小都比所需的chunk大,而且
// map本身不为0,所以必然存在满足需求的chunk。
bin = bin_at(av, (block << BINMAPSHIFT));
bit = 1;
}找到合适的 BIN
/* Advance to bin with set bit. There must be one. */
// 从当前map的最小的bin一直找,直到找到合适的bin。
// 这里是一定存在的
while ((bit & map) == 0) {
bin = next_bin(bin);
bit <<= 1;
assert(bit != 0);
}简单检查 CHUNK
/* Inspect the bin. It is likely to be non-empty */
// 获取对应的bin
victim = last(bin);
/* If a false alarm (empty bin), clear the bit. */
// 如果victim=bin,那么我们就将map对应的位清0,然后获取下一个bin
// 这种情况发生的概率应该很小。
if (victim == bin) {
av->binmap[ block ] = map &= ~bit; /* Write through */
bin = next_bin(bin);
bit <<= 1;
}真正取出 CHUNK
else {
// 获取对应victim的大小
size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */
assert((unsigned long) (size) >= (unsigned long) (nb));
// 计算分割后剩余的大小
remainder_size = size - nb;
/* unlink */
unlink(av, victim, bck, fwd);
/* Exhaust */
// 如果分割后不够一个chunk怎么办?
if (remainder_size < MINSIZE) {
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena) set_non_main_arena(victim);
}
/* Split */
// 如果够,尽管分割
else {
// 计算剩余的chunk的偏移
remainder = chunk_at_offset(victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
// 将剩余的chunk插入到unsorted bin中
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__glibc_unlikely(fwd->bk != bck)) {
errstr = "malloc(): corrupted unsorted chunks 2";
goto errout;
}
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
/* advertise as last remainder */
// 如果在small bin范围内,就将其标记为remainder
if (in_smallbin_range(nb)) av->last_remainder = remainder;
if (!in_smallbin_range(remainder_size)) {
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
// 设置victim的使用状态
set_head(victim,
nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
// 设置remainder的使用状态,这里是为什么呢?
set_head(remainder, remainder_size | PREV_INUSE);
// 设置remainder的大小
set_foot(remainder, remainder_size);
}
// 检查
check_malloced_chunk(av, victim, nb);
// chunk状态转换到mem状态
void *p = chunk2mem(victim);
// 如果设置了perturb_type, 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}使用 top chunk
如果所有的 bin 中的 chunk 都没有办法直接满足要求(即不合并),或者说都没有空闲的 chunk。那么我们就只能使用 top chunk 了。
use_top:
/*
If large enough, split off the chunk bordering the end of memory
(held in av->top). Note that this is in accord with the best-fit
search rule. In effect, av->top is treated as larger (and thus
less well fitting) than any other available chunk since it can
be extended to be as large as necessary (up to system
limitations).
We require that av->top always exists (i.e., has size >=
MINSIZE) after initialization, so if it would otherwise be
exhausted by current request, it is replenished. (The main
reason for ensuring it exists is that we may need MINSIZE space
to put in fenceposts in sysmalloc.)
*/
// 获取当前的top chunk,并计算其对应的大小
victim = av->top;
size = chunksize(victim);
// 如果分割之后,top chunk 大小仍然满足 chunk 的最小大小,那么就可以直接进行分割。
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)) {
remainder_size = size - nb;
remainder = chunk_at_offset(victim, nb);
av->top = remainder;
// 这里设置 PREV_INUSE 是因为 top chunk 前面的 chunk 如果不是 fastbin,就必然会和
// top chunk 合并,所以这里设置了 PREV_INUSE。
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
alloc_perturb(p, bytes);
return p;
}
// 否则,判断是否有 fast chunk
/* When we are using atomic ops to free fast chunks we can get
here for all block sizes. */
else if (have_fastchunks(av)) {
// 先执行一次fast bin的合并
malloc_consolidate(av);
/* restore original bin index */
// 判断需要的chunk是在small bin范围内还是large bin范围内
// 并计算对应的索引
// 等待下次再看看是否可以
if (in_smallbin_range(nb))
idx = smallbin_index(nb);
else
idx = largebin_index(nb);
}堆内存不够
如果堆内存不够,我们就需要使用 sysmalloc 来申请内存了。
/*
Otherwise, relay to handle system-dependent cases
*/
// 否则的话,我们就只能从系统中再次申请一点内存了。
else {
void *p = sysmalloc(nb, av);
if (p != NULL) alloc_perturb(p, bytes);
return p;
}_libc_calloc
calloc 也是 libc 中的一种申请内存块的函数。在 libc中的封装为 _libc_calloc,具体介绍如下
/*
calloc(size_t n_elements, size_t element_size);
Returns a pointer to n_elements * element_size bytes, with all locations
set to zero.
*/
void* __libc_calloc(size_t, size_t);sysmalloc
正如该函数头的注释所言,该函数用于当前堆内存不足时,需要向系统申请更多的内存。
/*
sysmalloc handles malloc cases requiring more memory from the system.
On entry, it is assumed that av->top does not have enough
space to service request for nb bytes, thus requiring that av->top
be extended or replaced.
*/基本定义
static void *sysmalloc(INTERNAL_SIZE_T nb, mstate av) {
mchunkptr old_top; /* incoming value of av->top */
INTERNAL_SIZE_T old_size; /* its size */
char *old_end; /* its end address */
long size; /* arg to first MORECORE or mmap call */
char *brk; /* return value from MORECORE */
long correction; /* arg to 2nd MORECORE call */
char *snd_brk; /* 2nd return val */
INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */
INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */
char *aligned_brk; /* aligned offset into brk */
mchunkptr p; /* the allocated/returned chunk */
mchunkptr remainder; /* remainder frOm allocation */
unsigned long remainder_size; /* its size */
size_t pagesize = GLRO(dl_pagesize);
bool tried_mmap = false;我们可以主要关注一下 pagesize,其
#ifndef EXEC_PAGESIZE
#define EXEC_PAGESIZE 4096
#endif
# define GLRO(name) _##name
size_t _dl_pagesize = EXEC_PAGESIZE;所以,pagesize=4096=0x1000。
考虑 mmap
正如开头注释所言如果满足如下任何一种条件
- 没有分配堆。
- 申请的内存大于 mp_.mmap_threshold,并且 mmap 的数量小于最大值,就可以尝试使用 mmap。
默认情况下,临界值为
static struct malloc_par mp_ = {
.top_pad = DEFAULT_TOP_PAD,
.n_mmaps_max = DEFAULT_MMAP_MAX,
.mmap_threshold = DEFAULT_MMAP_THRESHOLD,
.trim_threshold = DEFAULT_TRIM_THRESHOLD,
#define NARENAS_FROM_NCORES(n) ((n) * (sizeof(long) == 4 ? 2 : 8))
.arena_test = NARENAS_FROM_NCORES(1)
#if USE_TCACHE
,
.tcache_count = TCACHE_FILL_COUNT,
.tcache_bins = TCACHE_MAX_BINS,
.tcache_max_bytes = tidx2usize(TCACHE_MAX_BINS - 1),
.tcache_unsorted_limit = 0 /* No limit. */
#endif
};DEFAULT_MMAP_THRESHOLD 为 128*1024 字节,即 128 K。
#ifndef DEFAULT_MMAP_THRESHOLD
#define DEFAULT_MMAP_THRESHOLD DEFAULT_MMAP_THRESHOLD_MIN
#endif
/*
MMAP_THRESHOLD_MAX and _MIN are the bounds on the dynamically
adjusted MMAP_THRESHOLD.
*/
#ifndef DEFAULT_MMAP_THRESHOLD_MIN
#define DEFAULT_MMAP_THRESHOLD_MIN (128 * 1024)
#endif
#ifndef DEFAULT_MMAP_THRESHOLD_MAX
/* For 32-bit platforms we cannot increase the maximum mmap
threshold much because it is also the minimum value for the
maximum heap size and its alignment. Going above 512k (i.e., 1M
for new heaps) wastes too much address space. */
#if __WORDSIZE == 32
#define DEFAULT_MMAP_THRESHOLD_MAX (512 * 1024)
#else
#define DEFAULT_MMAP_THRESHOLD_MAX (4 * 1024 * 1024 * sizeof(long))
#endif
#endif下面为这部分代码,目前不是我们关心的重点,可以暂时跳过。
/*
If have mmap, and the request size meets the mmap threshold, and
the system supports mmap, and there are few enough currently
allocated mmapped regions, try to directly map this request
rather than expanding top.
*/
if (av == NULL ||
((unsigned long)(nb) >= (unsigned long)(mp_.mmap_threshold) &&
(mp_.n_mmaps < mp_.n_mmaps_max))) {
char *mm; /* return value from mmap call*/
try_mmap:
/*
Round up size to nearest page. For mmapped chunks, the overhead
is one SIZE_SZ unit larger than for normal chunks, because there
is no following chunk whose prev_size field could be used.
See the front_misalign handling below, for glibc there is no
need for further alignments unless we have have high alignment.
*/
if (MALLOC_ALIGNMENT == 2 * SIZE_SZ)
size = ALIGN_UP(nb + SIZE_SZ, pagesize);
else
size = ALIGN_UP(nb + SIZE_SZ + MALLOC_ALIGN_MASK, pagesize);
tried_mmap = true;
/* Don't try if size wraps around 0 */
if ((unsigned long)(size) > (unsigned long)(nb)) {
mm = (char *)(MMAP(0, size, PROT_READ | PROT_WRITE, 0));
if (mm != MAP_FAILED) {
/*
The offset to the start of the mmapped region is stored
in the prev_size field of the chunk. This allows us to adjust
returned start address to meet alignment requirements here
and in memalign(), and still be able to compute proper
address argument for later munmap in free() and realloc().
*/
if (MALLOC_ALIGNMENT == 2 * SIZE_SZ) {
/* For glibc, chunk2mem increases the address by 2*SIZE_SZ and
MALLOC_ALIGN_MASK is 2*SIZE_SZ-1. Each mmap'ed area is page
aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */
assert(((INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK) == 0);
front_misalign = 0;
} else
front_misalign = (INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK;
if (front_misalign > 0) {
correction = MALLOC_ALIGNMENT - front_misalign;
p = (mchunkptr)(mm + correction);
set_prev_size(p, correction);
set_head(p, (size - correction) | IS_MMAPPED);
} else {
p = (mchunkptr)mm;
set_prev_size(p, 0);
set_head(p, size | IS_MMAPPED);
}
/* update statistics */
int new = atomic_exchange_and_add(&mp_.n_mmaps, 1) + 1;
atomic_max(&mp_.max_n_mmaps, new);
unsigned long sum;
sum = atomic_exchange_and_add(&mp_.mmapped_mem, size) + size;
atomic_max(&mp_.max_mmapped_mem, sum);
check_chunk(av, p);
return chunk2mem(p);
}
}
}mmap 失败或者未分配堆
/* There are no usable arenas and mmap also failed. */
if (av == NULL)
return 0;如果是这两种情况中的任何一种,其实就可以退出了。。
记录旧堆信息
/* Record incoming configuration of top */
old_top = av->top;
old_size = chunksize(old_top);
old_end = (char *)(chunk_at_offset(old_top, old_size));
brk = snd_brk = (char *)(MORECORE_FAILURE);检查旧堆信息 1
/*
If not the first time through, we require old_size to be
at least MINSIZE and to have prev_inuse set.
*/
assert((old_top == initial_top(av) && old_size == 0) ||
((unsigned long)(old_size) >= MINSIZE && prev_inuse(old_top) &&
((unsigned long)old_end & (pagesize - 1)) == 0));这个检查要求满足其中任何一个条件
- old_top == initial_top(av) && old_size == 0,即如果是第一次的话,堆的大小需要是 0。
- 新的堆,那么
-
- (unsigned long)(old_size) >= MINSIZE && prev_inuse(old_top),堆的大小应该不小于 MINSIZE,并且前一个堆块应该处于使用中。
- ((unsigned long)old_end & (pagesize - 1)) == 0),堆的结束地址应该是页对齐的,由于页对齐的大小默认是 0x1000,所以低 12 个比特需要为 0。
检查旧堆信息 2
/* Precondition: not enough current space to satisfy nb request */
assert((unsigned long)(old_size) < (unsigned long)(nb + MINSIZE));根据 malloc 中的定义
static void *_int_malloc(mstate av, size_t bytes) {
INTERNAL_SIZE_T nb; /* normalized request size */nb 应该是已经加上 chunk 头部的字节,为什么还要加上 MINSIZE呢?这是因为 top chunk 的大小应该至少预留 MINSIZE 空间,以便于合并。
非 main_arena
这里暂时不是关心的重点,暂且不分析。
if (av != &main_arena) {
heap_info *old_heap, *heap;
size_t old_heap_size;
/* First try to extend the current heap. */
old_heap = heap_for_ptr(old_top);
old_heap_size = old_heap->size;
if ((long)(MINSIZE + nb - old_size) > 0 &&
grow_heap(old_heap, MINSIZE + nb - old_size) == 0) {
av->system_mem += old_heap->size - old_heap_size;
set_head(old_top,
(((char *)old_heap + old_heap->size) - (char *)old_top) |
PREV_INUSE);
} else if ((heap = new_heap(nb + (MINSIZE + sizeof(*heap)), mp_.top_pad))) {
/* Use a newly allocated heap. */
heap->ar_ptr = av;
heap->prev = old_heap;
av->system_mem += heap->size;
/* Set up the new top. */
top(av) = chunk_at_offset(heap, sizeof(*heap));
set_head(top(av), (heap->size - sizeof(*heap)) | PREV_INUSE);
/* Setup fencepost and free the old top chunk with a multiple of
MALLOC_ALIGNMENT in size. */
/* The fencepost takes at least MINSIZE bytes, because it might
become the top chunk again later. Note that a footer is set
up, too, although the chunk is marked in use. */
old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK;
set_head(chunk_at_offset(old_top, old_size + 2 * SIZE_SZ),
0 | PREV_INUSE);
if (old_size >= MINSIZE) {
set_head(chunk_at_offset(old_top, old_size),
(2 * SIZE_SZ) | PREV_INUSE);
set_foot(chunk_at_offset(old_top, old_size), (2 * SIZE_SZ));
set_head(old_top, old_size | PREV_INUSE | NON_MAIN_ARENA);
_int_free(av, old_top, 1);
} else {
set_head(old_top, (old_size + 2 * SIZE_SZ) | PREV_INUSE);
set_foot(old_top, (old_size + 2 * SIZE_SZ));
}
} else if (!tried_mmap)
/* We can at least try to use to mmap memory. */
goto try_mmap;
}Main_arena 处理
计算内存
计算可以满足请求的内存大小。
else { /* av == main_arena */
/* Request enough space for nb + pad + overhead */
size = nb + mp_.top_pad + MINSIZE;默认情况下 top_pad定义为
#ifndef DEFAULT_TOP_PAD
# define DEFAULT_TOP_PAD 131072
#endif即 131072 字节,0x20000 字节。
是否连续
如果我们希望堆的空间连续的话,那么其实可以复用之前的内存。
/*
If contiguous, we can subtract out existing space that we hope to
combine with new space. We add it back later only if
we don't actually get contiguous space.
*/
if (contiguous(av))
size -= old_size;对齐页大小
/*
Round to a multiple of page size.
If MORECORE is not contiguous, this ensures that we only call it
with whole-page arguments. And if MORECORE is contiguous and
this is not first time through, this preserves page-alignment of
previous calls. Otherwise, we correct to page-align below.
*/
size = ALIGN_UP(size, pagesize);申请内存
/*
Don't try to call MORECORE if argument is so big as to appear
negative. Note that since mmap takes size_t arg, it may succeed
below even if we cannot call MORECORE.
*/
if (size > 0) {
brk = (char *)(MORECORE(size));
LIBC_PROBE(memory_sbrk_more, 2, brk, size);
}可能成功
if (brk != (char *)(MORECORE_FAILURE)) {
/* Call the `morecore' hook if necessary. */
void (*hook)(void) = atomic_forced_read(__after_morecore_hook);
if (__builtin_expect(hook != NULL, 0))
(*hook)();
}这里竟然调用了一个 hook,有点意思。
失败
失败,考虑 mmap。
else {
/*
If have mmap, try using it as a backup when MORECORE fails or
cannot be used. This is worth doing on systems that have "holes" in
address space, so sbrk cannot extend to give contiguous space, but
space is available elsewhere. Note that we ignore mmap max count
and threshold limits, since the space will not be used as a
segregated mmap region.
*/
/* Cannot merge with old top, so add its size back in */
if (contiguous(av))
size = ALIGN_UP(size + old_size, pagesize);
/* If we are relying on mmap as backup, then use larger units */
if ((unsigned long)(size) < (unsigned long)(MMAP_AS_MORECORE_SIZE))
size = MMAP_AS_MORECORE_SIZE;
/* Don't try if size wraps around 0 */
if ((unsigned long)(size) > (unsigned long)(nb)) {
char *mbrk = (char *)(MMAP(0, size, PROT_READ | PROT_WRITE, 0));
if (mbrk != MAP_FAILED) {
/* We do not need, and cannot use, another sbrk call to find end */
brk = mbrk;
snd_brk = brk + size;
/*
Record that we no longer have a contiguous sbrk region.
After the first time mmap is used as backup, we do not
ever rely on contiguous space since this could incorrectly
bridge regions.
*/
set_noncontiguous(av);
}
}
}ptmalloc动态管理内存是通过brk还是mmap
ptmalloc 动态管理内存时既可能使用 brk 也可能使用 mmap,具体取决于不同的情况和系统。
通常,ptmalloc 在初始化时会使用 mmap 来映射一片大的地址空间作为堆(heap)。这个区域会被划分为不同的 bins,用于存放不同大小的内存块。mmap 在这里的使用有助于获得一块连续的虚拟内存空间。
然后,在运行时,当需要分配一块小内存块时,ptmalloc 会尽量使用 brk 来扩展堆空间。brk 系统调用用于增加或减少进程的数据段(data segment)的大小,从而影响整个进程的堆空间。这使得 ptmalloc 可以灵活地管理堆,动态地调整堆的大小以适应内存分配的需求。
总的来说,ptmalloc 的实现中既包含 mmap 用于初始化时的大范围映射,又包含 brk 用于运行时的小范围调整,以提供灵活且高效的内存管理。这些具体实现细节可能在不同的系统和 glibc 版本中有所不同。
内存可能申请成功
if (brk != (char *)(MORECORE_FAILURE)) {
if (mp_.sbrk_base == 0)
mp_.sbrk_base = brk;
av->system_mem += size;情况 1
/*
If MORECORE extends previous space, we can likewise extend top size.
*/
if (brk == old_end && snd_brk == (char *)(MORECORE_FAILURE))
set_head(old_top, (size + old_size) | PREV_INUSE);情况 2 - 意外内存耗尽
else if (contiguous(av) && old_size && brk < old_end)
/* Oops! Someone else killed our space.. Can't touch anything. */
malloc_printerr("break adjusted to free malloc space");处理其他意外情况
/*
Otherwise, make adjustments:
* If the first time through or noncontiguous, we need to call sbrk
just to find out where the end of memory lies.
* We need to ensure that all returned chunks from malloc will meet
MALLOC_ALIGNMENT
* If there was an intervening foreign sbrk, we need to adjust sbrk
request size to account for fact that we will not be able to
combine new space with existing space in old_top.
* Almost all systems internally allocate whole pages at a time, in
which case we might as well use the whole last page of request.
So we allocate enough more memory to hit a page boundary now,
which in turn causes future contiguous calls to page-align.
*/
else {
front_misalign = 0;
end_misalign = 0;
correction = 0;
aligned_brk = brk;- 第一次分配或非连续空间: 如果是第一次分配(即初次调用 malloc)或者不是连续空间,那么需要调用 sbrk 以找出内存的结束位置。sbrk 用于扩展或缩小进程的数据段,获取新的内存。
- 对齐要求: 需要确保从 malloc 返回的所有块都满足 MALLOC_ALIGNMENT,即内存对齐的要求。
- 外部 sbrk 的影响: 如果在两次 malloc 之间存在外部的 sbrk 调用,需要调整 sbrk 请求的大小,以考虑到不能将新空间与旧的 old_top 空间合并的事实。
- 内存页面对齐: 大多数系统内部以整页的方式分配内存,因此为了优化,这里选择分配足够多的内存,以达到页面边界。这样做会导致将来的连续调用也会在页面边界上对齐。
- front_misalign、end_misalign、correction、aligned_brk 是用于记录对齐和调整的一些变量。
处理连续内存
/* handle contiguous cases */
if (contiguous(av)) {
/* Count foreign sbrk as system_mem. */
if (old_size)
av->system_mem += brk - old_end;
/* Guarantee alignment of first new chunk made from this space */
front_misalign = (INTERNAL_SIZE_T)chunk2mem(brk) & MALLOC_ALIGN_MASK;
if (front_misalign > 0) {
/*
Skip over some bytes to arrive at an aligned position.
We don't need to specially mark these wasted front bytes.
They will never be accessed anyway because
prev_inuse of av->top (and any chunk created from its start)
is always true after initialization.
*/
correction = MALLOC_ALIGNMENT - front_misalign;
aligned_brk += correction;
}
/*
If this isn't adjacent to existing space, then we will not
be able to merge with old_top space, so must add to 2nd request.
*/
correction += old_size;
/* Extend the end address to hit a page boundary */
end_misalign = (INTERNAL_SIZE_T)(brk + size + correction);
correction += (ALIGN_UP(end_misalign, pagesize)) - end_misalign;
assert(correction >= 0);
snd_brk = (char *)(MORECORE(correction));
/*
If can't allocate correction, try to at least find out current
brk. It might be enough to proceed without failing.
Note that if second sbrk did NOT fail, we assume that space
is contiguous with first sbrk. This is a safe assumption unless
program is multithreaded but doesn't use locks and a foreign sbrk
occurred between our first and second calls.
*/
if (snd_brk == (char *)(MORECORE_FAILURE)) {
correction = 0;
snd_brk = (char *)(MORECORE(0));
} else {
/* Call the `morecore' hook if necessary. */
void (*hook)(void) = atomic_forced_read(__after_morecore_hook);
if (__builtin_expect(hook != NULL, 0))
(*hook)();
}
}处理不连续内存
/* handle non-contiguous cases */
else {
if (MALLOC_ALIGNMENT == 2 * SIZE_SZ)
/* MORECORE/mmap must correctly align */
assert(((unsigned long)chunk2mem(brk) & MALLOC_ALIGN_MASK) == 0);
else {
front_misalign =
(INTERNAL_SIZE_T)chunk2mem(brk) & MALLOC_ALIGN_MASK;
if (front_misalign > 0) {
/*
Skip over some bytes to arrive at an aligned position.
We don't need to specially mark these wasted front bytes.
They will never be accessed anyway because
prev_inuse of av->top (and any chunk created from its start)
is always true after initialization.
*/
aligned_brk += MALLOC_ALIGNMENT - front_misalign;
}
}
/* Find out current end of memory */
if (snd_brk == (char *)(MORECORE_FAILURE)) {
snd_brk = (char *)(MORECORE(0));
}
}调整
/* Adjust top based on results of second sbrk */
if (snd_brk != (char *)(MORECORE_FAILURE)) {
av->top = (mchunkptr)aligned_brk;
set_head(av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE);
av->system_mem += correction;
/*
If not the first time through, we either have a
gap due to foreign sbrk or a non-contiguous region. Insert a
double fencepost at old_top to prevent consolidation with space
we don't own. These fenceposts are artificial chunks that are
marked as inuse and are in any case too small to use. We need
two to make sizes and alignments work out.
*/
if (old_size != 0) {
/*
Shrink old_top to insert fenceposts, keeping size a
multiple of MALLOC_ALIGNMENT. We know there is at least
enough space in old_top to do this.
*/
old_size = (old_size - 4 * SIZE_SZ) & ~MALLOC_ALIGN_MASK;
set_head(old_top, old_size | PREV_INUSE);
/*
Note that the following assignments completely overwrite
old_top when old_size was previously MINSIZE. This is
intentional. We need the fencepost, even if old_top otherwise
gets lost.
*/
set_head(chunk_at_offset(old_top, old_size),
(2 * SIZE_SZ) | PREV_INUSE);
set_head(chunk_at_offset(old_top, old_size + 2 * SIZE_SZ),
(2 * SIZE_SZ) | PREV_INUSE);
/* If possible, release the rest. */
if (old_size >= MINSIZE) {
_int_free(av, old_top, 1);
}
}
}
}需要注意的是,在这里程序将旧的 top chunk 进行了释放,那么其会根据大小进入不同的 bin 或 tcache 中。
tcache 是 glibc 中的一种线程本地缓存,用于加速小块内存的分配和释放操作。这是在 glibc 2.26 版本引入的,目的是通过减少线程间的竞争来提高性能。
tcache 是一个特定大小的缓存,用于存储特定大小的内存块。每个线程都有自己的 tcache,这样就避免了多个线程之间的锁竞争,提高了并发性。tcache 主要用于管理小块内存,通常是 16 字节到 512 字节之间。
以下是 tcache 的一些特点:
- 线程本地: 每个线程都有自己的 tcache,减少了线程之间的竞争。
- 特定大小的内存块:tcache 以特定的大小存储内存块。这个大小通常是 16 字节的倍数,取决于具体的实现。
- 分配和释放快速: 对于小块内存的分配和释放,线程可以直接使用自己的 tcache,而无需进行全局锁的竞争。
- 有限的缓存:tcache 是有限的,一旦达到容量上限,就需要从全局的空闲链表中获取内存块或者将内存块释放到全局链表中。
- 调整参数: 可以通过环境变量(例如 TCACHE_MAX_SIZE、TCACHE_COUNT)来调整 tcache 的参数,以适应不同的应用场景。
tcache的内存是哪来的
tcache 中的内存主要来自于应用程序通过 malloc 函数申请的小块内存。当应用程序释放这些小块内存时,tcache 会将其存储在线程本地的缓存中,以备后续的分配使用。这样,线程在分配小块内存时可以直接从自己的 tcache 中获取,而无需进行全局的内存分配管理,从而提高了性能。
以下是 tcache 的基本工作流程:
- 分配内存: 应用程序通过 malloc 或类似的内存分配函数请求一块小块内存。
- 线程本地缓存: 如果请求的内存大小适合存储在 tcache 中(通常是 16 字节到 512 字节之间),tcache 会将这块内存存储在线程本地的缓存中。
- 快速分配: 当线程再次请求相同大小的内存块时,可以直接从自己的 tcache 中获取,而无需进行全局的锁竞争和搜索操作。这使得小块内存的分配速度更快。
- 缓存限制:tcache 是有限的,每个线程的 tcache 都有一个最大容量。当 tcache 达到容量上限时,线程可能需要从全局的空闲链表中获取内存块,或将内存块释放到全局链表中。
需要注意的是,对于大块内存,或者在某些情况下 tcache 不适用的情况,系统仍然会通过其他机制(例如 bins、mmap)来处理内存的分配和释放。
更新最大内存
if ((unsigned long)av->system_mem > (unsigned long)(av->max_system_mem))
av->max_system_mem = av->system_mem;
check_malloc_state(av);分配内存块
获取大小
/* finally, do the allocation */
p = av->top;
size = chunksize(p);切分 TOP
/* check that one of the above allocation paths succeeded */
if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE)) {
remainder_size = size - nb;
remainder = chunk_at_offset(p, nb);
av->top = remainder;
set_head(p, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, p, nb);
return chunk2mem(p);
}捕捉所有错误
/* catch all failure paths */
__set_errno(ENOMEM);
return 0;释放内存块
__libc_free
类似于 malloc,free 函数也有一层封装,命名格式与 malloc 基本类似。代码如下
void __libc_free(void *mem) {
mstate ar_ptr;
mchunkptr p; /* chunk corresponding to mem */
// 判断是否有钩子函数 __free_hook
void (*hook)(void *, const void *) = atomic_forced_read(__free_hook);
if (__builtin_expect(hook != NULL, 0)) {
(*hook)(mem, RETURN_ADDRESS(0));
return;
}
// free NULL没有作用
if (mem == 0) /* free(0) has no effect */
return;
// 将mem转换为chunk状态
p = mem2chunk(mem);
// 如果该块内存是mmap得到的
if (chunk_is_mmapped(p)) /* release mmapped memory. */
{
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold && chunksize_nomask(p) > mp_.mmap_threshold &&
chunksize_nomask(p) <= DEFAULT_MMAP_THRESHOLD_MAX &&
!DUMPED_MAIN_ARENA_CHUNK(p)) {
mp_.mmap_threshold = chunksize(p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE(memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk(p);
return;
}
// 根据chunk获得分配区的指针
ar_ptr = arena_for_chunk(p);
// 执行释放
_int_free(ar_ptr, p, 0);
}_int_free
函数初始时刻定义了一系列的变量,并且得到了用户想要释放的 chunk 的大小
static void _int_free(mstate av, mchunkptr p, int have_lock) {
INTERNAL_SIZE_T size; /* its size */
mfastbinptr * fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
const char *errstr = NULL;
int locked = 0;
size = chunksize(p);简单的检查
/* Little security check which won't hurt performance: the
allocator never wrapps around at the end of the address space.
Therefore we can exclude some size values which might appear
here by accident or by "design" from some intruder. */
// 指针不能指向非法的地址, 必须小于等于-size,为什么???
// 指针必须得对齐,2*SIZE_SZ 这个对齐得仔细想想
if (__builtin_expect((uintptr_t) p > (uintptr_t) -size, 0) ||
__builtin_expect(misaligned_chunk(p), 0)) {
errstr = "free(): invalid pointer";
errout:
if (!have_lock && locked) __libc_lock_unlock(av->mutex);
malloc_printerr(check_action, errstr, chunk2mem(p), av);
return;
}
/* We know that each chunk is at least MINSIZE bytes in size or a
multiple of MALLOC_ALIGNMENT. */
// 大小没有最小的chunk大,或者说,大小不是MALLOC_ALIGNMENT的整数倍
if (__glibc_unlikely(size < MINSIZE || !aligned_OK(size))) {
errstr = "free(): invalid size";
goto errout;
}
// 检查该chunk是否处于使用状态,非调试状态下没有作用
check_inuse_chunk(av, p);- 指针合法性检查:
-
- if (__builtin_expect((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect(misaligned_chunk(p), 0))
- 这一部分主要是检查释放的指针 p 是否合法。其中:
-
-
- (uintptr_t) p > (uintptr_t) -size 检查释放的指针是否指向合法的地址,确保没有出现指针溢出的情况。
- misaligned_chunk(p) 检查释放的指针是否按照要求对齐。misaligned_chunk 的实现可能检查指针是否满足特定的对齐要求。
-
-
- 如果上述条件中任何一个不满足,就表示释放的指针不合法,会输出错误信息并返回。
- 大小合法性检查:
-
- if (__glibc_unlikely(size < MINSIZE || !aligned_OK(size)))
- 这一部分检查释放的块的大小是否合法。其中:
-
-
- size < MINSIZE 确保块的大小不小于最小的合法块大小。
- !aligned_OK(size) 检查块的大小是否符合内存对齐要求。
-
-
- 如果上述条件中任何一个不满足,就表示释放的块的大小不合法,同样会输出错误信息并返回。
- 检查块的使用状态:
-
- check_inuse_chunk(av, p);
- 这一部分是对于调试状态下的检查。它会检查释放的块是否被标记为已使用。如果块没有被标记为已使用,说明存在内存错误,会输出相应的错误信息。
其中
/* Check if m has acceptable alignment */
#define aligned_OK(m) (((unsigned long) (m) &MALLOC_ALIGN_MASK) == 0)
#define misaligned_chunk(p) \
((uintptr_t)(MALLOC_ALIGNMENT == 2 * SIZE_SZ ? (p) : chunk2mem(p)) & \
MALLOC_ALIGN_MASK)fast bin
如果上述检查都合格的话,判断当前的 bin 是不是在 fast bin 范围内,在的话就插入到 fastbin 头部,即成为对应 fastbin 链表的第一个 free chunk。
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long) (size) <= (unsigned long) (get_max_fast())
#if TRIM_FASTBINS
/*
If TRIM_FASTBINS set, don't place chunks
bordering top into fastbins
*/
//默认 #define TRIM_FASTBINS 0,因此默认情况下下面的语句不会执行
// 如果当前chunk是fast chunk,并且下一个chunk是top chunk,则不能插入
&& (chunk_at_offset(p, size) != av->top)
#endif
) {
// 下一个chunk的大小不能小于两倍的SIZE_SZ,并且
// 下一个chunk的大小不能大于system_mem, 一般为132k
// 如果出现这样的情况,就报错。
if (__builtin_expect(
chunksize_nomask(chunk_at_offset(p, size)) <= 2 * SIZE_SZ, 0) ||
__builtin_expect(
chunksize(chunk_at_offset(p, size)) >= av->system_mem, 0)) {
/* We might not have a lock at this point and concurrent
modifications
of system_mem might have let to a false positive. Redo the test
after getting the lock. */
if (have_lock || ({
assert(locked == 0);
__libc_lock_lock(av->mutex);
locked = 1;
chunksize_nomask(chunk_at_offset(p, size)) <= 2 * SIZE_SZ ||
chunksize(chunk_at_offset(p, size)) >= av->system_mem;
})) {
errstr = "free(): invalid next size (fast)";
goto errout;
}
if (!have_lock) {
__libc_lock_unlock(av->mutex);
locked = 0;
}
}
// 将chunk的mem部分全部设置为perturb_byte
free_perturb(chunk2mem(p), size - 2 * SIZE_SZ);
// 设置fast chunk的标记位
set_fastchunks(av);
// 根据大小获取fast bin的索引
unsigned int idx = fastbin_index(size);
// 获取对应fastbin的头指针,被初始化后为NULL。
fb = &fastbin(av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
// 使用原子操作将P插入到链表中
mchunkptr old = *fb, old2;
unsigned int old_idx = ~0u;
do {
/* Check that the top of the bin is not the record we are going to
add
(i.e., double free). */
// so we can not double free one fastbin chunk
// 防止对 fast bin double free
if (__builtin_expect(old == p, 0)) {
errstr = "double free or corruption (fasttop)";
goto errout;
}
/* Check that size of fastbin chunk at the top is the same as
size of the chunk that we are adding. We can dereference OLD
only if we have the lock, otherwise it might have already been
deallocated. See use of OLD_IDX below for the actual check. */
if (have_lock && old != NULL)
old_idx = fastbin_index(chunksize(old));
p->fd = old2 = old;
} while ((old = catomic_compare_and_exchange_val_rel(fb, p, old2)) !=
old2);
// 确保fast bin的加入前与加入后相同
if (have_lock && old != NULL && __builtin_expect(old_idx != idx, 0)) {
errstr = "invalid fastbin entry (free)";
goto errout;
}
}合并非 mmap 的空闲 chunk
只有不是 fast bin 的情况下才会触发 unlink
首先我们先说一下为什么会合并 chunk,这是为了避免 heap 中有太多零零碎碎的内存块,合并之后可以用来应对更大的内存块请求。合并的主要顺序为
- 先考虑物理低地址空闲块
- 后考虑物理高地址空闲块
合并后的 chunk 指向合并的 chunk 的低地址。
在没有锁的情况下,先获得锁。
/*
Consolidate other non-mmapped chunks as they arrive.
*/
else if (!chunk_is_mmapped(p)) {
if (!have_lock) {
__libc_lock_lock(av->mutex);
locked = 1;
}
nextchunk = chunk_at_offset(p, size);轻量级的检测
/* Lightweight tests: check whether the block is already the
top block. */
// 当前free的chunk不能是top chunk
if (__glibc_unlikely(p == av->top)) {
errstr = "double free or corruption (top)";
goto errout;
}
// 当前free的chunk的下一个chunk不能超过arena的边界
/* Or whether the next chunk is beyond the boundaries of the arena. */
if (__builtin_expect(contiguous(av) &&
(char *) nextchunk >=
((char *) av->top + chunksize(av->top)),
0)) {
errstr = "double free or corruption (out)";
goto errout;
}
// 当前要free的chunk的使用标记没有被标记,double free
/* Or whether the block is actually not marked used. */
if (__glibc_unlikely(!prev_inuse(nextchunk))) {
errstr = "double free or corruption (!prev)";
goto errout;
}
// 下一个chunk的大小
nextsize = chunksize(nextchunk);
// next chunk size valid check
// 判断下一个chunk的大小是否不大于2*SIZE_SZ,或者
// nextsize是否大于系统可提供的内存
if (__builtin_expect(chunksize_nomask(nextchunk) <= 2 * SIZE_SZ, 0) ||
__builtin_expect(nextsize >= av->system_mem, 0)) {
errstr = "free(): invalid next size (normal)";
goto errout;
}释放填充
//将指针的mem部分全部设置为perturb_byte
free_perturb(chunk2mem(p), size - 2 * SIZE_SZ);后向合并 - 合并低地址 chunk
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size(p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}下一块不是 top chunk - 前向合并 - 合并高地址 chunk
需要注意的是,如果下一块不是 top chunk ,则合并高地址的 chunk ,并将合并后的 chunk 放入到 unsorted bin 中。
// 如果下一个chunk不是top chunk
if (nextchunk != av->top) {
/* get and clear inuse bit */
// 获取下一个 chunk 的使用状态
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
// 如果不在使用,合并,否则清空当前chunk的使用状态。
/* consolidate forward */
if (!nextinuse) {
unlink(av, nextchunk, bck, fwd);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
/*
Place the chunk in unsorted chunk list. Chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
*/
// 把 chunk 放在 unsorted chunk 链表的头部
bck = unsorted_chunks(av);
fwd = bck->fd;
// 简单的检查
if (__glibc_unlikely(fwd->bk != bck)) {
errstr = "free(): corrupted unsorted chunks";
goto errout;
}
p->fd = fwd;
p->bk = bck;
// 如果是 large chunk,那就设置nextsize指针字段为NULL。
if (!in_smallbin_range(size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);
}下一块是 top chunk - 合并到 top chunk
/*
If the chunk borders the current high end of memory,
consolidate into top
*/
// 如果要释放的chunk的下一个chunk是top chunk,那就合并到 top chunk
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}向系统返还内存
/*
If freeing a large space, consolidate possibly-surrounding
chunks. Then, if the total unused topmost memory exceeds trim
threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins
bordering top, so we cannot tell for sure whether threshold
has been reached unless fastbins are consolidated. But we
don't want to consolidate on each free. As a compromise,
consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD
is reached.
*/
// 如果合并后的 chunk 的大小大于FASTBIN_CONSOLIDATION_THRESHOLD
// 一般合并到 top chunk 都会执行这部分代码。
// 那就向系统返还内存
if ((unsigned long) (size) >= FASTBIN_CONSOLIDATION_THRESHOLD) {
// 如果有 fast chunk 就进行合并
if (have_fastchunks(av)) malloc_consolidate(av);
// 主分配区
if (av == &main_arena) {
#ifndef MORECORE_CANNOT_TRIM
// top chunk 大于当前的收缩阙值
if ((unsigned long) (chunksize(av->top)) >=
(unsigned long) (mp_.trim_threshold))
systrim(mp_.top_pad, av);
#endif // 非主分配区,则直接收缩heap
} else {
/* Always try heap_trim(), even if the top chunk is not
large, because the corresponding heap might go away. */
heap_info *heap = heap_for_ptr(top(av));
assert(heap->ar_ptr == av);
heap_trim(heap, mp_.top_pad);
}
}
if (!have_lock) {
assert(locked);
__libc_lock_unlock(av->mutex);
}释放 mmap 的 chunk
} else {
// If the chunk was allocated via mmap, release via munmap().
munmap_chunk(p);
}systrim
systrim 不是标准的 C 函数,而是 glibc 内部用于执行堆收缩的一个函数。它被设计为在特定条件下调用,以向操作系统释放多余的堆内存。
具体来说,systrim 的作用是通过系统调用来返还多余的堆内存给操作系统。这种返还的行为被称为堆收缩,目的是减小程序的内存占用,提高系统资源的利用率。
在 glibc 的源代码中,systrim 函数通常会调用底层的系统调用来释放多余的内存。具体的实现可能涉及到平台相关的系统调用,例如 brk 或 mmap。不同的操作系统和体系结构可能有不同的方式来实现堆收缩。
heap_trim
heap_trim 是 glibc 中用于堆收缩的函数之一。它的作用是通过调用系统调用来返还多余的堆内存给操作系统,从而减小程序的内存占用。
具体来说,heap_trim 会根据参数传入的 top_pad 值,将多余的堆内存返还给操作系统。top_pad 表示顶部块(top chunk)的大小,多余的内存是指 top chunk 中未被使用的部分。
函数原型通常是:
cCopy code
void heap_trim(heap_info *heap, size_t top_pad);其中,heap_info 结构用于表示堆的信息,包括堆的起始地址、结束地址等。top_pad 参数表示 top chunk 的大小,即未被使用的部分。
heap_trim 的具体实现可能会涉及平台相关的系统调用,例如 brk 或 mmap。这个函数的主要目的是在适当的时机,根据 top_pad 的值,调用系统调用将多余的内存返回给操作系统,实现堆收缩的效果。
区别
heap_trim 和 systrim 都是用于堆收缩的函数,它们的目标都是将多余的内存返还给操作系统,以减小程序的内存占用。然而,它们在实现细节和调用时机上存在一些区别。
- 实现细节:
-
- heap_trim 是 glibc 中的函数,用于堆收缩。其实现会涉及一些 glibc 内部的逻辑,可能包括特定于平台的系统调用,例如 brk 或 mmap,以及对堆结构的管理。
- systrim 不是公开的 glibc 接口,而是可能由 malloc 或类似的分配函数在适当的时机调用的内部函数。它的实现细节和调用方式可能在不同版本的 glibc 中有所不同。
- 调用时机:
-
- heap_trim 通常由 malloc 等函数在释放大块内存后主动调用,以优化内存的使用。它可以有选择性地在释放后的特定时机进行堆收缩。
- systrim 的调用时机可能更加自动化,可能会在一些特定的条件下被调用,以执行全局的堆收缩。这样的条件可能涉及到 top chunk 的大小和一些运行时的策略。
tcache
tcache 是 glibc 2.26 (ubuntu 17.10) 之后引入的一种技术(see commit),目的是提升堆管理的性能。但提升性能的同时舍弃了很多安全检查,也因此有了很多新的利用方式。
主要参考了 glibc 源码,angelboy 的 slide 以及 tukan.farm,链接都放在最后了。
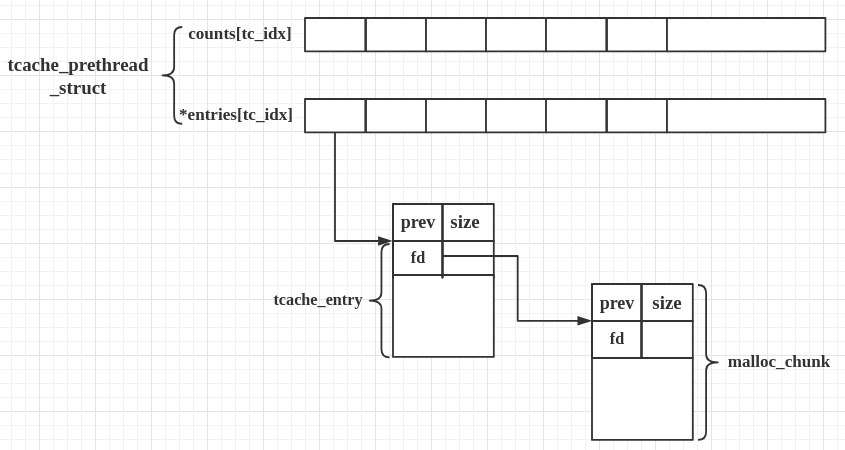
相关结构体
tcache 引入了两个新的结构体,tcache_entry 和 tcache_perthread_struct。
这其实和 fastbin 很像,但又不一样。
tcache_entry
/* We overlay this structure on the user-data portion of a chunk when
the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;tcache_entry 用于链接空闲的 chunk 结构体,其中的 next 指针指向下一个大小相同的 chunk。
需要注意的是这里的 next 指向 chunk 的 user data,而 fastbin 的 fd 指向 chunk 开头的地址。
而且,tcache_entry 会复用空闲 chunk 的 user data 部分。
tcache_perthread_struct
/* There is one of these for each thread, which contains the
per-thread cache (hence "tcache_perthread_struct"). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
# define TCACHE_MAX_BINS 64
static __thread tcache_perthread_struct *tcache = NULL;每个 thread 都会维护一个 tcache_perthread_struct,它是整个 tcache 的管理结构,一共有 TCACHE_MAX_BINS 个计数器和 TCACHE_MAX_BINS项 tcache_entry,其中
- tcache_entry 用单向链表的方式链接了相同大小的处于空闲状态(free 后)的 chunk,这一点上和 fastbin 很像。
- counts 记录了 tcache_entry 链上空闲 chunk 的数目,每条链上最多可以有 7 个 chunk。
用图表示大概是:
基本工作方式
- 第一次 malloc 时,会先 malloc 一块内存用来存放 tcache_perthread_struct 。
- free 内存,且 size 小于 small bin size 时
- tcache 之前会放到 fastbin 或者 unsorted bin 中
- tcache 后:
-
- 先放到对应的 tcache 中,直到 tcache 被填满(默认是 7 个)
- tcache 被填满之后,再次 free 的内存和之前一样被放到 fastbin 或者 unsorted bin 中
- tcache 中的 chunk 不会合并(不取消 inuse bit)
- malloc 内存,且 size 在 tcache 范围内
- 先从 tcache 取 chunk,直到 tcache 为空
- tcache 为空后,从 bin 中找
- tcache 为空时,如果 fastbin/smallbin/unsorted bin 中有 size 符合的 chunk,会先把 fastbin/smallbin/unsorted bin 中的 chunk 放到 tcache 中,直到填满。之后再从 tcache 中取;因此 chunk 在 bin 中和 tcache 中的顺序会反过来
源码分析
接下来从源码的角度分析一下 tcache。
__libc_malloc
第一次 malloc 时,会进入到 MAYBE_INIT_TCACHE ()
void *
__libc_malloc (size_t bytes)
{
......
......
#if USE_TCACHE
/* int_free also calls request2size, be careful to not pad twice. */
size_t tbytes;
// 根据 malloc 传入的参数计算 chunk 实际大小,并计算 tcache 对应的下标
checked_request2size (bytes, tbytes);
size_t tc_idx = csize2tidx (tbytes);
// 初始化 tcache
MAYBE_INIT_TCACHE ();
DIAG_PUSH_NEEDS_COMMENT;
if (tc_idx < mp_.tcache_bins // 根据 size 得到的 idx 在合法的范围内
/*&& tc_idx < TCACHE_MAX_BINS*/ /* to appease gcc */
&& tcache
&& tcache->entries[tc_idx] != NULL) // tcache->entries[tc_idx] 有 chunk
{
return tcache_get (tc_idx);
}
DIAG_POP_NEEDS_COMMENT;
#endif
......
......
}__tcache_init()
其中 MAYBE_INIT_TCACHE () 在 tcache 为空(即第一次 malloc)时调用了 tcache_init(),直接查看 tcache_init()
tcache_init(void)
{
mstate ar_ptr;
void *victim = 0;
const size_t bytes = sizeof (tcache_perthread_struct);
if (tcache_shutting_down)
return;
arena_get (ar_ptr, bytes); // 找到可用的 arena
victim = _int_malloc (ar_ptr, bytes); // 申请一个 sizeof(tcache_perthread_struct) 大小的 chunk
if (!victim && ar_ptr != NULL)
{
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
/* In a low memory situation, we may not be able to allocate memory
- in which case, we just keep trying later. However, we
typically do this very early, so either there is sufficient
memory, or there isn't enough memory to do non-trivial
allocations anyway. */
if (victim) // 初始化 tcache
{
tcache = (tcache_perthread_struct *) victim;
memset (tcache, 0, sizeof (tcache_perthread_struct));
}
}tcache_init() 成功返回后,tcache_perthread_struct 就被成功建立了。
申请内存
接下来将进入申请内存的步骤
// 从 tcache list 中获取内存
if (tc_idx < mp_.tcache_bins // 由 size 计算的 idx 在合法范围内
/*&& tc_idx < TCACHE_MAX_BINS*/ /* to appease gcc */
&& tcache
&& tcache->entries[tc_idx] != NULL) // 该条 tcache 链不为空
{
return tcache_get (tc_idx);
}
DIAG_POP_NEEDS_COMMENT;
#endif
// 进入与无 tcache 时类似的流程
if (SINGLE_THREAD_P)
{
victim = _int_malloc (&main_arena, bytes);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}在 tcache->entries 不为空时,将进入 tcache_get() 的流程获取 chunk,否则与 tcache 机制前的流程类似,这里主要分析第一种 tcache_get()。这里也可以看出 tcache 的优先级很高,比 fastbin 还要高( fastbin 的申请在没进入 tcache 的流程中)。
tcache_get()
看一下 tcache_get()
/* Caller must ensure that we know tc_idx is valid and there's
available chunks to remove. */
static __always_inline void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]); // 获得一个 chunk,counts 减一
return (void *) e;
}tcache_get() 就是获得 chunk 的过程了。可以看出这个过程还是很简单的,从 tcache->entries[tc_idx] 中获得第一个 chunk,tcache->counts 减一,几乎没有任何保护。
__libc_free()
看完申请,再看看有 tcache 时的释放
void
__libc_free (void *mem)
{
......
......
MAYBE_INIT_TCACHE ();
ar_ptr = arena_for_chunk (p);
_int_free (ar_ptr, p, 0);
}__libc_free() 没有太多变化,MAYBE_INIT_TCACHE () 在 tcache 不为空失去了作用。
_int_free()
跟进 _int_free()
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
......
......
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache
&& tc_idx < mp_.tcache_bins // 64
&& tcache->counts[tc_idx] < mp_.tcache_count) // 7
{
tcache_put (p, tc_idx);
return;
}
}
#endif
......
......判断 tc_idx 合法,tcache->counts[tc_idx] 在 7 个以内时,就进入 tcache_put(),传递的两个参数是要释放的 chunk 和该 chunk 对应的 size 在 tcache 中的下标。
tcache_put()
/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
assert (tc_idx < TCACHE_MAX_BINS);
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}tcache_puts() 完成了把释放的 chunk 插入到 tcache->entries[tc_idx] 链表头部的操作,也几乎没有任何保护。并且 没有把 p 位置零。
malloc_state 相关函数
malloc_init_state
/*
Initialize a malloc_state struct.
This is called only from within malloc_consolidate, which needs
be called in the same contexts anyway. It is never called directly
outside of malloc_consolidate because some optimizing compilers try
to inline it at all call points, which turns out not to be an
optimization at all. (Inlining it in malloc_consolidate is fine though.)
*/
static void malloc_init_state(mstate av) {
int i;
mbinptr bin;
/* Establish circular links for normal bins */
for (i = 1; i < NBINS; ++i) {
bin = bin_at(av, i);
bin->fd = bin->bk = bin;
}
#if MORECORE_CONTIGUOUS
if (av != &main_arena)
#endif
set_noncontiguous(av);
if (av == &main_arena) set_max_fast(DEFAULT_MXFAST);
// 设置 flags 标记目前没有fast chunk
av->flags |= FASTCHUNKS_BIT;
// 就是 unsorted bin
av->top = initial_top(av);
}malloc_consolidate
该函数主要有两个功能
- 若 fastbin 未初始化,即 global_max_fast 为 0,那就初始化 malloc_state。
- 如果已经初始化的话,就合并 fastbin 中的 chunk。
基本的流程如下
初始
static void malloc_consolidate(mstate av) {
mfastbinptr *fb; /* current fastbin being consolidated */
mfastbinptr *maxfb; /* last fastbin (for loop control) */
mchunkptr p; /* current chunk being consolidated */
mchunkptr nextp; /* next chunk to consolidate */
mchunkptr unsorted_bin; /* bin header */
mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */
mchunkptr nextchunk;
INTERNAL_SIZE_T size;
INTERNAL_SIZE_T nextsize;
INTERNAL_SIZE_T prevsize;
int nextinuse;
mchunkptr bck;
mchunkptr fwd;合并 chunk
/*
If max_fast is 0, we know that av hasn't
yet been initialized, in which case do so below
*/
// 说明 fastbin 已经初始化
if (get_max_fast() != 0) {
// 清空 fastbin 标记
// 因为要合并 fastbin 中的 chunk 了。
clear_fastchunks(av);
//
unsorted_bin = unsorted_chunks(av);
/*
Remove each chunk from fast bin and consolidate it, placing it
then in unsorted bin. Among other reasons for doing this,
placing in unsorted bin avoids needing to calculate actual bins
until malloc is sure that chunks aren't immediately going to be
reused anyway.
*/
// 按照 fd 顺序遍历 fastbin 的每一个 bin,将 bin 中的每一个 chunk 合并掉。
maxfb = &fastbin(av, NFASTBINS - 1);
fb = &fastbin(av, 0);
do {
p = atomic_exchange_acq(fb, NULL);
if (p != 0) {
do {
check_inuse_chunk(av, p);
nextp = p->fd;
/* Slightly streamlined version of consolidation code in
* free() */
size = chunksize(p);
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (!prev_inuse(p)) {
prevsize = prev_size(p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}
if (nextchunk != av->top) {
// 判断 nextchunk 是否是空闲的。
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink(av, nextchunk, bck, fwd);
} else
// 设置 nextchunk 的 prev inuse 为0,以表明可以合并当前 fast chunk。
clear_inuse_bit_at_offset(nextchunk, 0);
first_unsorted = unsorted_bin->fd;
unsorted_bin->fd = p;
first_unsorted->bk = p;
if (!in_smallbin_range(size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
set_head(p, size | PREV_INUSE);
p->bk = unsorted_bin;
p->fd = first_unsorted;
set_foot(p, size);
}
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
} while ((p = nextp) != 0);
}
} while (fb++ != maxfb);初始化
说明 fastbin 还没有初始化。
} else {
malloc_init_state(av);
// 在非调试情况下没有什么用,在调试情况下,做一些检测。
check_malloc_state(av);
}
















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









