







Types of Agent Programs:
Simple reflex agents It uses just condition-action rules
Model-based reflex agents For the world that is partially observable
Goal-based agents Actions chosen are towards the goal based on
Utility-based agents Utility is higher than goal

1. 简单反射型智能体(Simple Reflex Agents)
核心机制:
- 直接通过「条件-动作规则」(if-then规则)作出反应
- 无内部状态:仅依赖当前感知信息,不记忆历史
- 决策公式:
Action = Lookup(Percept, RuleTable)
典型场景:
- 完全可观察、静态、确定性的环境
- 例如:
- 自动门传感器(检测到人→开门)
- 火灾报警器(检测烟雾→触发警报)
局限性:
- 无法处理部分可观察或动态环境
- 规则表可能无限庞大(如围棋有10^170种状态)
2. 基于模型的反射型智能体(Model-Based Reflex Agents)
核心升级:
- 维护内部世界模型(Internal World Model)
- 通过模型推断当前环境状态(包括不可直接观察的部分)
- 决策公式:
State = UpdateModel(PreviousState, Action, Percept)
Action = RuleBasedOn(State)
典型场景:
- 部分可观察、动态的环境
- 例如:
- 扫地机器人(通过SLAM构建地图,避开临时障碍物)
- 自动驾驶汽车(预测被遮挡车辆的位置)
关键技术:
- 状态估计(如卡尔曼滤波、粒子滤波)
- 环境建模(概率图模型、动态贝叶斯网络)
3. 基于目标的智能体(Goal-Based Agents)
核心机制:
- 引入显式目标(Goal)作为决策导向
- 通过搜索或规划寻找达成目标的最优路径
- 决策公式:
Plan = Search(CurrentState, Goal, ActionSpace)
Action = ExecuteNextStep(Plan)
典型场景:
- 需要长期规划、多步决策的环境
- 例如:
- 路径规划(A*算法寻找最短路线)
- 魔方求解程序(分步骤还原各面颜色)
算法代表:
- 启发式搜索(A*、Dijkstra)
- 规划算法(STRIPS、PDDL)
4. 基于效用的智能体(Utility-Based Agents)
核心突破:
- 引入效用函数(Utility Function)量化状态优劣
- 在多个可能目标间权衡,追求综合效用最大化
- 决策公式:
ExpectedUtility = Σ[P(Outcome|Action) × Utility(Outcome)]
OptimalAction = Argmax(ExpectedUtility)
典型场景:
- 存在冲突目标或风险权衡的环境
- 例如:
- 自动驾驶(平衡时间效率、安全性、能耗)
- 投资机器人(在风险与收益间优化组合)
关键技术:
- 多目标优化(Pareto最优)
- 决策理论(期望效用最大化)
四类智能体的演进关系
| 类型 | 决策依据 | 环境复杂度支持 | 典型算法 |
|---|---|---|---|
| 简单反射型 | 当前感知 | 完全可观察、静态 | 规则引擎 |
| 基于模型的反射型 | 内部状态模型 | 部分可观察、动态 | 贝叶斯网络 |
| 基于目标的智能体 | 显式目标 | 需长期规划 | A*搜索、规划算法 |
| 基于效用的智能体 | 效用函数最大化 | 多目标冲突、不确定性 | 马尔可夫决策过程 |
关键区别示例
-
目标 vs 效用:
- 目标型:到达目的地(二值结果:成功/失败)
- 效用型:以最短时间+最低油耗+最小风险到达(连续优化)
-
反射 vs 模型:
- 简单反射:看到红灯→刹车
- 模型反射:根据车速、距离推断刹车时机,避免急停










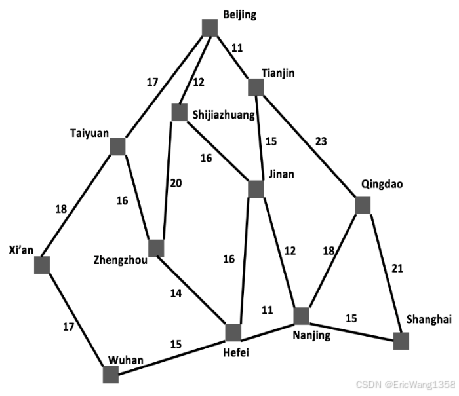
3. What data structure should be used to store the frontier in breadth-first search, uniform-cost search and depth-first search, respectively? (L3: P48-54)
4. In Lecture 3, the solution of a problem is define as a path from the initial state to a state satisfying the goal test. As two examples in the following, please find out the optimal solution with lowest path cost among the given solutions.
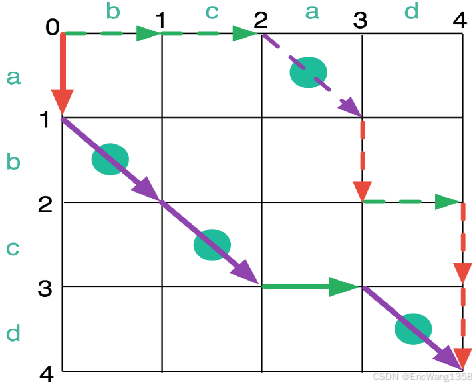
- UCS是Dijkstra算法在路径搜索中的具体实现
- 通过优先队列实现节点的动态排序
在广度优先搜索(BFS)、统一成本搜索(UCS)和深度优先搜索(DFS)中,边界节点集合(frontier) 的数据结构选择取决于算法遍历节点的顺序规则。以下是具体对应关系:
1. 广度优先搜索(BFS)
数据结构:队列(Queue)
- 原因:BFS按“先进先出(FIFO)”的顺序扩展节点,保证优先探索浅层节点。
- 操作方式:
enqueue():新发现的节点加入队尾dequeue():从队头取出节点进行扩展
- 示例:二叉树的层序遍历、社交网络中的朋友关系扩散。
2. 统一成本搜索(UCS)
数据结构:优先队列(Priority Queue,通常基于最小堆实现)
- 原因:UCS始终选择当前路径成本(累计代价)最小的节点扩展,需动态维护节点的优先级。
- 操作方式:
insert():插入节点时按路径成本排序extract_min():取出成本最小的节点
- 关键点:若节点已存在于队列中且发现更低成本路径,需更新其优先级(如使用更高效的斐波那契堆)。
- 示例:地图导航中寻找最短行车距离的路径。
3. 深度优先搜索(DFS)
数据结构:栈(Stack)
- 原因:DFS按“后进先出(LIFO)”的顺序扩展节点,优先深入探索分支。
- 操作方式:
push():新节点压入栈顶pop():从栈顶取出节点扩展
- 注意:显式栈(手动维护) vs 隐式栈(递归调用栈)。
- 示例:迷宫回溯问题、拓扑排序。
对比总结
| 算法 | 数据结构 | 扩展顺序规则 | 适用场景 |
|---|---|---|---|
| 广度优先搜索 (BFS) | 队列(FIFO) | 按层级逐层扩展 | 最短路径(边数最少) |
| 统一成本搜索 (UCS) | 优先队列(最小堆) | 按路径成本升序扩展 | 最优路径(累积代价最小) |
| 深度优先搜索 (DFS) | 栈(LIFO) | 单路径深度优先,回溯探索 | 解空间穷举、存在性验证 |
补充说明
- BFS的队列实现:可用链表或循环数组。
- UCS的优先级更新:若节点已在队列中且发现更优路径,需降低其优先级(某些数据结构如二叉堆对此支持较差)。
- DFS的变体:若需避免重复访问,需额外维护
visited集合(尤其是图结构)。
理解这些数据结构的选择逻辑,能帮助你在实际编码中正确实现搜索算法,并分析其时间/空间复杂度(例如BFS的空间复杂度为O(b^d),而DFS为O(bm),其中b是分支因子,d是目标深度,m是最大深度)。

问题8解答
根据题目中给出的完全二叉树结构,以下是BFS和DFS的详细分析:
二叉树结构
8
/ \
4 12
/ \ / \
2 6 10 14
/ \ / \ / \ / \
1 3 5 7 9 11 13 15 1. 广度优先搜索(BFS)
遍历顺序:
按层级逐层访问(8 → 4 → 12 → 2 → 6 → 10 → 14 → 1 → 3 → 5 → 7 → 9 → 11 → 13 → 15)
关键指标:
| 属性 | 数值/复杂度 |
|---|---|
| 生成节点数量 | 15(所有节点均被访问) |
| 时间复杂度 | O(n)(n=15,线性时间) |
| 空间复杂度 | O(n)(存储最后一层8个节点) |
解释:
- BFS使用队列结构,确保按层扩展节点。
- 空间复杂度由最宽层(第四层8个节点)决定,严格为O(n)级别。
2. 深度优先搜索(DFS)
遍历顺序(以先序遍历为例):
8 → 4 → 2 → 1 → 3 → 6 → 5 → 7 → 12 → 10 → 9 → 11 → 14 → 13 → 15
关键指标:
| 属性 | 数值/复杂度 |
|---|---|
| 生成节点数量 | 15(所有节点均被访问) |
| 时间复杂度 | O(n)(n=15,线性时间) |
| 空间复杂度 | O(h)(h=4,树的高度) |
解释:
- DFS(递归实现)的空间复杂度由递归栈深度决定,完全二叉树高度为 h=log₂(n+1)=4,因此空间复杂度为 O(log n)。
- 若使用显式栈迭代实现,空间复杂度仍为O(h)。
复杂度对比总结
| 方法 | 节点数量 | 时间复杂度 | 空间复杂度 | 核心数据结构 |
|---|---|---|---|---|
| BFS | 15 | O(n) | O(n)(队列) | 队列 |
| DFS | 15 | O(n) | O(log n)(栈) | 栈/递归栈 |
关键结论
- 节点访问数量相同:BFS和DFS均需遍历所有15个节点。
- 时间复杂度等价:均为O(n),但实际常数因子可能因实现方式不同而异。
- 空间复杂度差异显著:
- BFS需存储整层节点(如第四层8节点),空间占用较高。
- DFS仅需存储当前路径的节点(如根到叶的路径4节点),空间效率更优。
应用场景建议:
- BFS:适用于寻找最短路径(如二叉树最小深度)、层序分析。
- DFS:适用于路径存在性检查、回溯问题、内存敏感场景。
此分析严格依据题目中的完全二叉树结构,实际应用中需根据树的具体形态调整复杂度评估。
普通二叉树的BFS与DFS复杂度分析
对于普通二叉树(不一定是完全二叉树),广度优先搜索(BFS)和深度优先搜索(DFS)的复杂度特性如下:
1. 广度优先搜索(BFS)
- 生成节点数量:所有节点均被访问,数量为
n(n为树的总节点数)。 - 时间复杂度:
O(n),每个节点进出队列一次。 - 空间复杂度:O(w),其中
w是树的最大宽度(即最宽层的节点数)。- 最坏情况:当树退化为链状结构(每层仅1个节点),
w=1,空间复杂度为O(1); - 一般情况:
w可达O(n)(如完全二叉树的最后一层)。
- 最坏情况:当树退化为链状结构(每层仅1个节点),
示例:
若二叉树退化为链状(根→左→左→…),BFS的空间复杂度为 O(1);若为完全二叉树,空间复杂度为 O(n/2)(最后一层宽度)。
2. 深度优先搜索(DFS)
- 生成节点数量:所有节点均被访问,数量为
n。 - 时间复杂度:
O(n),每个节点被压入/弹出栈一次。 - 空间复杂度:O(h),其中
h是树的高度(根到最深叶节点的路径长度)。- 最坏情况:树退化为链状结构,
h=n,空间复杂度为O(n); - 平衡树情况:
h=O(log n),空间复杂度为O(log n)。
- 最坏情况:树退化为链状结构,
示例:
对于完全二叉树(原题中的树),h=log₂(n+1),空间复杂度为 O(log n);若树左倾严重(如根→左→左→…),则 h=O(n)。
关键对比总结
| 指标 | BFS | DFS |
|---|---|---|
| 节点数量 | O(n)(全访问) | O(n)(全访问) |
| 时间复杂度 | O(n) | O(n) |
| 空间复杂度 | **O(w)**(最大层宽决定) | **O(h)**(树的高度决定) |
普通二叉树的特殊性影响
-
BFS空间复杂度:
- 树越“宽胖”,空间需求越大(如完全二叉树最后一层占半数节点)。
- 树越“瘦高”,空间需求越小(如链状树仅需常数空间)。
-
DFS空间复杂度:
- 树越“平衡”(h接近log n),空间效率越高;
- 树越“不平衡”(h接近n),空间效率越低。
应用建议
-
优先选择BFS:
- 需要最短路径(如二叉树最小深度)、层序遍历分析。
- 当树较平衡且宽度可控时(避免内存爆炸)。
-
优先选择DFS:
- 内存受限场景(平衡树下空间复杂度低)。
- 路径存在性问题(如根到叶的特定和检查)。
总结:无论二叉树是否完全,BFS和DFS的节点生成数量和时间复杂度均为 O(n),但空间复杂度由树的结构特征(宽度/高度)决定,需根据具体问题权衡选择。
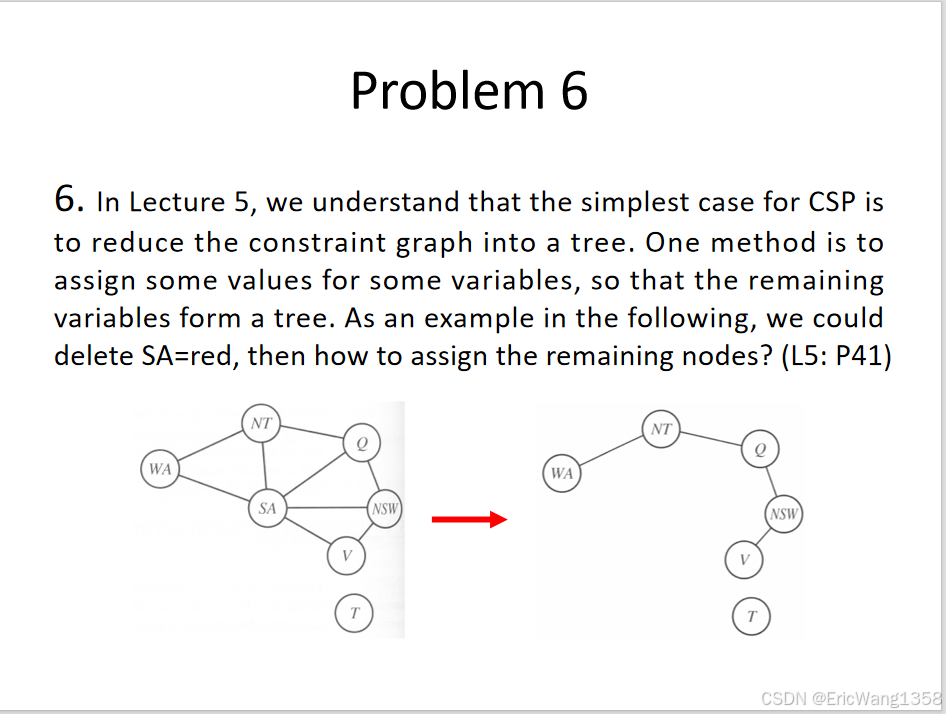
问题6解答
根据题目要求,需通过为部分变量赋值将约束图简化为树形结构,以下是详细的解题步骤和答案:
原图结构分析
初始约束图节点:SA、NT、WA、Q、NSW、V、T
相邻关系(根据典型澳大利亚地图着色问题):
- SA连接:WA、NT、Q、NSW、V
- 其他连接:
- NT ↔ WA、Q
- Q ↔ NSW
- NSW ↔ V
- V ↔ T
简化目标
通过删除SA节点(设为红色)并为其相邻节点分配值,使得剩余节点的约束图形成树形结构(无环且连通)。
解题步骤
-
删除SA节点:
- SA设为红色后,其相邻节点(WA、NT、Q、NSW、V)不可为红色。
- 剩余节点:NT、WA、Q、NSW、V、T
-
验证树形结构条件:
- 无环性:删除SA后,剩余节点的连接关系需确保无环路。
- 连通性:所有剩余节点需通过边连通。
剩余连接关系:
NT — WA NT — Q Q — NSW NSW — V V — T- 该结构为链状树(无环且连通),满足树形条件。
-
赋值策略(以三色问题为例,颜色选项:红、蓝、绿):
- SA已固定为红色,其相邻节点(WA、NT、Q、NSW、V)需从蓝、绿中选择。
- 逐步赋值(从根节点WA开始,按层级分配):
节点 父节点 可用颜色(排除父节点颜色) 赋值示例 WA - 蓝、绿 蓝 NT WA 绿 绿 Q NT 蓝 蓝 NSW Q 绿 绿 V NSW 蓝 蓝 T V 绿 绿 -
验证约束满足:
- 相邻节点颜色均不同(如NT(绿)与WA(蓝)、Q(蓝)与NT(绿)等)。
- 结构无环且连通,形成有效树形CSP。
关键结论
-
简化后的树形结构:
WA(蓝) │ NT(绿) │ Q(蓝) │ NSW(绿) │ V(蓝) │ T(绿) -
算法意义:
- 通过固定SA的值并剪枝其相邻节点的颜色选项,将原图的环路(SA作为中心节点形成的星型环路)消除。
- 树形CSP可用高效算法(如弧相容+拓扑排序)在线性时间内求解。
复杂度与优化
| 指标 | 原图(普通图) | 简化后(树) |
|---|---|---|
| 求解时间 | 指数级 O(d^n) | 线性 O(n) |
| 空间占用 | 高(存储约束) | 低(树结构) |
| 适用算法 | 回溯法 | 动态规划/消息传递 |
此方法通过牺牲部分变量赋值自由度(固定SA颜色),换取计算效率的指数级提升,是CSP问题中典型的结构简化策略。
Syntax(句法)的深度解析
结合图片中的逻辑学定义,Syntax(句法) 的核心含义是:规定语言中合法句子的形式化结构规则。它关注的是符号的组合方式而非其实际含义,类似于编程语言的语法规则或自然语言的文法结构。
1. 句法的核心作用
- 定义合法句子:
句法规定哪些符号序列是合法的,例如命题逻辑中(P ∧ Q) → R是合法句子,而P ∧ → Q则因连接词顺序错误被排除。 - 构建形式化框架:
通过逻辑连接词(如¬、∨、∧、→、↔)的优先级和嵌套规则,确保句子无歧义。例如:- 合法:
A ∨ B → C(隐含括号:(A ∨ B) → C) - 非法:
A ∨ → B(连接词连续出现违反句法)
- 合法:
2. 句法的具体表现(以命题逻辑为例)
| 句法规则 | 合法示例 | 非法示例 | 违反原因 |
|---|---|---|---|
| 原子命题 | P | P1(若未定义) | 非基础命题符号 |
| 连接词使用 | P ∧ Q | P ∧ Q R | 缺少连接词或括号 |
| 括号匹配 | (P → Q) ∨ R | P → Q) ∨ R | 括号不闭合 |
3. 句法与语义的对比
| 维度 | Syntax(句法) | Semantics(语义) |
|---|---|---|
| 关注点 | 符号的排列规则 | 符号的真实含义和逻辑真值 |
| 判断 | 句子是否“形式正确” | 句子是否“有意义”或“为真” |
| 例子 | P ∨∨ Q 非法(连接词重复) | 猪会飞 → 1+1=3 合法但语义上为真(F→F=T) |
4. 实际应用中的句法
-
编程语言:
- 句法错误:
if x = 5 { print("OK") }(缺少冒号或括号) - 语义错误:
x = "5" + 3(类型不匹配但句法合法)
- 句法错误:
-
自然语言:
- 句法正确但语义荒谬:
绿色的思想愤怒地睡觉(中文句法合规但无意义)
- 句法正确但语义荒谬:
-
数学公式:
- 句法错误:
5 + × 3(运算符位置错误)
- 句法错误:
5. 为什么句法重要?
- 机器可处理性:计算机需依赖严格句法解析指令(如SQL查询、逻辑推理引擎)。
- 无歧义沟通:确保逻辑表达式在不同场景下被一致解读。
- 知识表示基础:在人工智能中,句法是构建知识图谱和推理系统的前提。
总结:Syntax是形式化语言的“骨架”,它不关心“句子是否合理或真实”,只确保符号组合符合既定规则。理解句法是掌握逻辑学、编程和自然语言处理的基石。
KB ╞ α 与 KB → α 的核心区别
根据图片中关于逻辑学语法(Syntax)和语义(Semantics)的定义,这两个符号分属逻辑学的不同层面,以下是详细分析:
1. 概念层级不同
| 符号 | 所属层面 | 定义核心 |
|---|---|---|
| KB ╞ α | 语义层面 | 表示知识库 KB 语义蕴含 α,即所有满足 KB 的模型(赋值)也满足 α |
| KB → α | 语法层面 | 表示将 KB 和 α 通过蕴含连接词(→)组合成一个新的逻辑句子(句法合法性验证) |
2. 具体区别解析
(1)KB ╞ α(语义蕴含)
- 含义:在所有可能的模型(真值赋值)中,只要 KB 为真,α 必然为真。
- 关注点:逻辑结论的真值关系,不关心具体推导过程。
- 示例:
- 若 KB = {A, A → B},则 KB ╞ B(语义上 B 必定为真)。
(2)KB → α(语法蕴含)
- 含义:将 KB 视为一个逻辑句子(通常是 KB 中所有命题的合取),与 α 组合成蕴含式。
- 关注点:句子本身的句法结构是否符合规则,以及该句子是否逻辑有效(即在所有模型中为真)。
- 示例:
- 若 KB = {A, A → B},则 KB → α 对应的句子是
(A ∧ (A → B)) → B,该句子是逻辑有效的(永真式)。
- 若 KB = {A, A → B},则 KB → α 对应的句子是
3. 关键对比表
| 维度 | KB ╞ α | KB → α |
|---|---|---|
| 所属层面 | 语义学(Semantics) | 句法学(Syntax) |
| 有效性判断 | 模型真值关系 | 句子形式是否永真 |
| 实际意义 | KB 是 α 的充分条件 | KB 与 α 的蕴含式是否逻辑有效 |
| 等价性 | KB ╞ α 当且仅当 KB → α 是永真式 | 仅在命题逻辑中成立(命题逻辑完备性) |
4. 实际应用中的区别
- 知识推理:
KB ╞ α用于验证 α 是否是 KB 的逻辑结论(如自动推理系统)。KB → α用于构建复合命题,检查其是否在所有情况下成立(如形式化验证)。
- 编程逻辑:
- 语义蕴含对应程序执行的正确性(输入满足条件则输出必正确)。
- 语法蕴含对应代码中的条件语句(如
if (KB) then alpha的结构合法性)。
总结
- KB ╞ α 是语义层面的逻辑推导关系,强调“从 KB 可得出 α”。
- KB → α 是语法层面的命题组合,强调“KB 蕴含 α 的句子是否永真”。
- 联系:在命题逻辑中,若
KB ╞ α,则KB → α是永真式(由逻辑完备性保证);反之亦然。
理解这一区别对构建逻辑系统至关重要:语义关注“真值”,语法关注“形式”,两者共同构成逻辑推理的基础。
1. Answer the following questions:
(h)Please list a few examples for the following definitions: 1) Positive/Negative Literals, and 2) Pure Horn Clauses/Negative Clauses/Non-Horn Clauses. (L6: P39) Note that A horn clause is a disjunction of literals of which at most one is positive.
(i)What about resolution algorithm, including Unit Resolution and Resolution Rule? (L6: P33-35)




L6
1. Answer the following questions:
(a) What difference between PL (Propositional Logic) and FOL (First-Order Logic)? (L7: P4,7)

(b) Please explain some new concepts: 1) Object, 2) function, 3) property, 4) relation, and 5) predicate. (L7: P5-6)

(c) What about the model for FOL? Which component is required in FOL model? (L7: P-9)

(d) In FOL, what are: 1) variable symbols; 2) connectives; 3) quantifiers; 4) ground terms? (L7: P12-13)
(e) What is the difference between ∀x ∃y P(x,y) and ∃x ∀y P(x,y)? Please give an example. (L7: P16)


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









