






 本文详细介绍了数据类型(包括整形、浮点数、构造类型、指针和空类型)在内存中的存储原理,探讨了原码、补码、反码的概念,大小端模式,以及浮点数的存储规则,通过实例解析了整型和浮点数在内存中的转换和输出差异。
本文详细介绍了数据类型(包括整形、浮点数、构造类型、指针和空类型)在内存中的存储原理,探讨了原码、补码、反码的概念,大小端模式,以及浮点数的存储规则,通过实例解析了整型和浮点数在内存中的转换和输出差异。
深度剖析数据在内存中的存储
一、数据类型介绍
1.整形家族
比较常见的有char类型,short类型,int类型,long类型以及long long类型,其中,char类型表面是字符类型,但是其在内存中是以ASC||值的形式存储的,所以还是整形。它们在内存中开辟的空间也不一样,char是占据一个字节,short是两个byte,int类型则是4个byte,long类型的空间并没有一个明确的规定,只是sizeof(long)>=sizeof(int),所以在不同的环境之下long会占据不同的字节。

如图所示,在VS2019的环境中,long占据4个字节的内存空间。此外,long long类型则是占据8个字节的内存。
2.浮点数家族
3.构造类型
构造类型,顾名思义就是自己创造的类型,那么有哪些类型是由我们自己创造的呢?
首先就是数组类型,arr[i],
其次是结构体类型,struct,
然后是两种比较不常见的,一种是联合类型union,另一种是枚举类型 enum。
4.指针类型
指针类型我们就比较熟悉了,存放的数据地址的不同也决定了指针类型的不同,
int*,char*,fioat*,甚至空类型也会有指针类型void*。
5.空类型
二、整形数据在内存中的存储
1.原码,补码,反码
首先,如果我们要探究整形数据在内存中的存储,我们就要先了解整形在计算机中的几种表现形式,探究他们和数据表面之间的关系。
众所周知,计算机只能进行二进制计算,所以数据在计算机内存中存在的方式也只能是二进制。这三种码都是二进制数字串。
原码就是符号位加数值位组成的,每串数字的第一位是符号位,如果这个数是正数则符号位是0,如果是负数则为1.后续则为数字的二进制表达。
补码则为原码除符号位之外按位取反。反码是原码加一,所有数字在内存的存储形式都是反码形式,计算也是用反码形式进行计算。不同类型的二进制数字位数也不同,比如char类型只有1byte的内存,也就是8bit,能存放下8个二进制数字。
2.大小端
大小端是指数据的字节顺序,也是两种模式,
大端模式是指,将数据的高字节位存放在低地址中,然后将低字节位存放在高地址中的字节序。
小端模式恰好相反,大端模式是指,将数据的低字节位存放在低地址中,然后将高字节位存放在高地址中的字节序。
那么,大小端为什么会存在呢?在内存存储中,只有char是占据一个byte类型,像int都是占据4个byte,而寄存器的宽度又大于一个byte,所以就会有不同的字节安排方式,就会产生不同的顺序,所以就产生了大小端这两种模式。
3.signed和unsigned
这两种的区别就是unsigned将signed中的符号位转化成数值位。
三、浮点数数据在内存中的存储
1.一个例子
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
return 0;
}
在这里我们猜猜输出的结果会是什么呢?
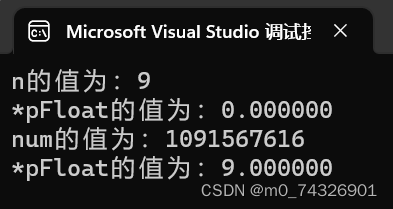
不知道这个结果是不是出乎了你的意料呢?
我们一点一点来分析这段代码。
int n = 9;
float *pFloat = (float *)&n;
首先是n的值,我们输入的是一个int类型的数字,然后输出的也是一个int类型,这里很好理解。
接着就是*pFloat的值,为什么float的内存空间明明跟int一样都是4个字节,但是通过指针输出就跟输入的时候不一样了呢?这说明在不发生内存切割的情况下,可能存在着输入存储方式的不同,并且影响指针。
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
紧接着,我们的*pFloat类型对内存进行改变,理所当然,后者也是正确的输出,而前者的结果就出现了偏差,这是因为float类型的输入方式和int类型不一样,导致%d在按照int类型进行输出的时候,和float的输入并没有相对应上。
那么,在清楚整形的存储方式的基础上,我们一起来探究浮点数的存储方式。
2.float的存储规则
1.在内存中的位置划分
在国际标准IEEE中,所有二进制浮点数都可以按以下形式表示。
a=(-1)SM*2^E,其中S是用来控制符号的一般就是为1或者0,然后M是浮点数的真实值部分,1<M<2,E则为科学计数法部分,用来控制小数点的位置。
而浮点数在内存中的存储就只有这三个部分,S,E,M。float类型占据4个字节,S占据一个bit,E占据8个bit,M占据23个bit,

其实double类型和float类型的布局类似,S占据一个bit,E占据11个bit,M占据52个bit,M的位置多少决定着这个类型的精准程度。

而十进制的浮点数怎么转化成二进制呢?
我们要分开进行转化,小数点前面的我们就正常进行转化,小数点后的我们就把2的指数变成负数,
比如0.5转化成二进制就是0.1,小数点后面的1就是2的-1次方。
所以这就面临着可能会凑不齐的情况,那么计算机会一直往后加数字进行凑整。
2.E和M的输入
从上面我们可以知道,E是浮点数的指数位,M是浮点数的真实值。E是指数位,就是用科学计数法所表示的数字,从数学角度理解,E是可以为负数的,用来表示原值是小数的情况。但是在内存中只能以二进制的形式,所以我们要在这里加上一个中间值,保证E是一个正数,float类型是加上127,double类型是加上1023.
在浮点数的存储中,1<M<2,所以M的个位都是1,于是可以进行省略,在M区我们只存放小数点之后的数字。
3.E和M的输出
在输入之后,我们就面临着输出的结果, E和M的输出是紧密相连的,大体上分为三种情况。
当E中间有0有1
这种是绝大部分情况,我们在输出E的时候直接减去127就行,然后在M的最前方加上个位数是1,然后其余位置补0就行了。
当E全部为0
如果内存中的E全部为0,那么说明指数应该是-127,这说明这个真实数据是非常接近0的数字,这个时候,我们就将E区的数字直接表示为1-127或者1-1023,然后M区直接输出0.xxxxxx,这样的话,这个数也是一个接近1的数字。
当E全部为1
如果内存中的E全部为1,那么说明指数应该是128,这说明这个数字的真实数据,是一个非常大的数字,当M全部为0的时候,就是等于+/-无穷,取决于S的取值。
3.一个例子(解疑版)
这个时候我们再来看最初的例子。
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
return 0;
}
这个整形的9存储在int类型下就是
int n = 9;
00000000000000000000000000001001
然后经历第二步的强制类型转换,
*pFloat所指向的内存的空间存储的也是
0 00000000 00000000000000000001001
printf("*pFloat的值为:%f\n",*pFloat);
这句话就是将这段二进制数字用浮点数的方式进行输出,
这里对应E全为0的情况,(-1)SE*M=2^(-126)*0.00000000000000000001001,这显然是一个很小的数字,用十进制来表示也就是0.000000.
然后再来看下一个部分
*pFloat = 9.0;
9在浮点数的存储是
0 10000010 00100000000000000000000
printf("num的值为:%d\n",n);
而在整形的输出的情况下,因为是正数,所以补码和原码相同,我们就是直接将这串二进制数字转化成十进制数字进行输出。

然后我们将这段二进制数字进行十进制转化可以看出这就是我们最开始进行输出的错误数字。
四、结语
到这里我们分析了整形和浮点数在内存中的存储的不同,其实还是有比较大的区别的,这些可以帮助我们更好的理解整形和浮点数的输出和输出。
创作不易,感谢阅读。

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









