







马尔科夫链#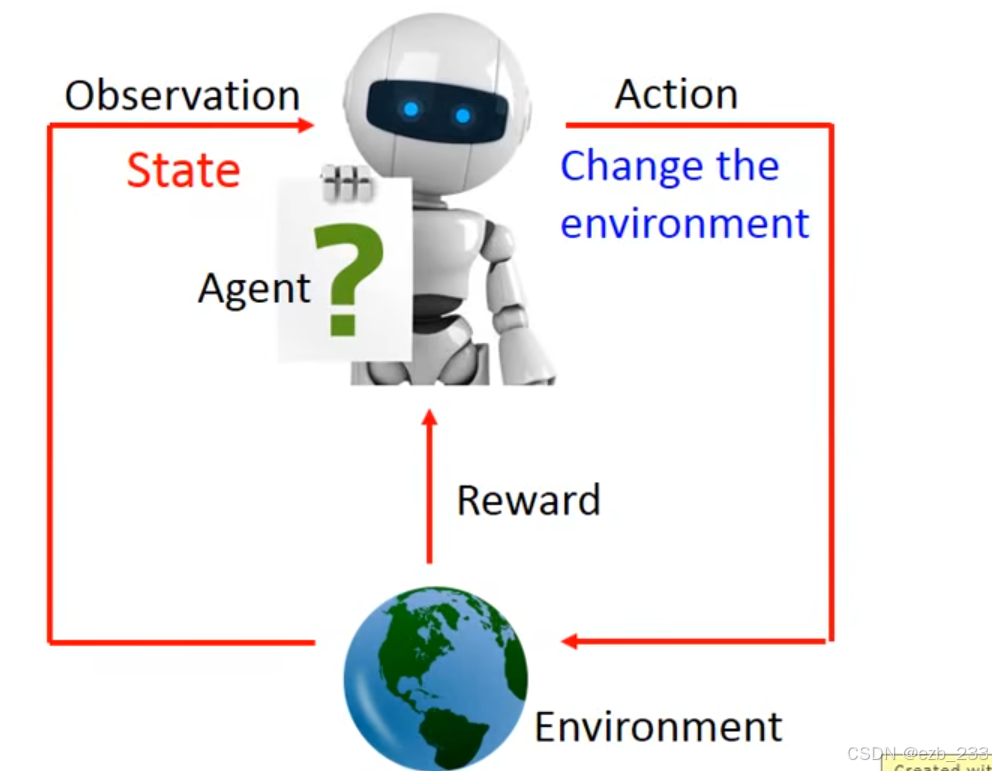
RL分类
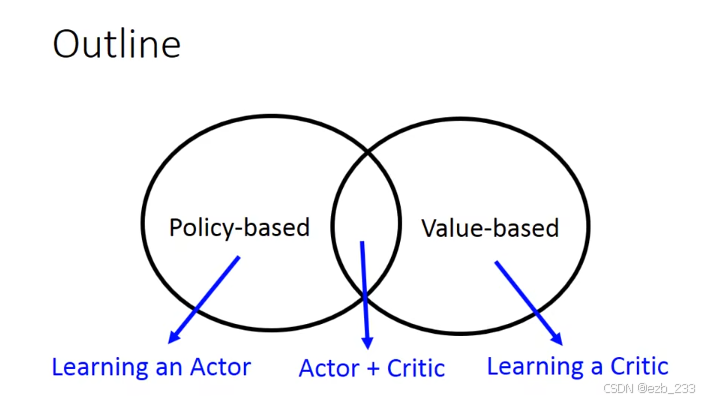
policy-based
基于策略的,mm输出是下一步的各种可能的期望,从而直接做出策略,该怎么走
value-based
基于值的,mm输出的是当前状态到终点可以获得的奖励(R)的期望。
actor
目标:最大化E(R)
episode:被认为是轨迹
τ
\tau
τ(从开始到结束)
- τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 . . . , s T , a T , r T } \tau=\{s_1,a_1,r_1,s_2,a_2,r_2...,s_T,a_T,r_T\} τ={s1,a1,r1,s2,a2,r2...,sT,aT,rT}
- R ( τ ) = Σ n = 1 N r n R(\tau)=\Sigma_{n=1}^Nr_n R(τ)=Σn=1Nrn
- P ( τ ∣ Θ ) P(\tau|\varTheta) P(τ∣Θ):表示 τ \tau τ的发生概率和 Θ \varTheta Θ有关
-
R
Θ
‾
=
∑
τ
R
(
τ
)
P
(
τ
∣
Θ
)
≈
1
N
Σ
n
=
1
N
R
(
τ
n
)
\overline{R_\varTheta}=\sum\limits_{\tau}R(\tau)P(\tau|\varTheta)≈\dfrac{1}{N}\Sigma_{n=1}^NR(\tau^n)
RΘ=τ∑R(τ)P(τ∣Θ)≈N1Σn=1NR(τn)
1 N Σ n = 1 N R ( τ n ) \dfrac{1}{N}\Sigma_{n=1}^NR(\tau^n) N1Σn=1NR(τn)
使用 π Θ \pi_\varTheta πΘ去玩N次游戏,得到轨迹抽样。单个样本被抽中的几率就是 N ∗ P ( τ ∣ Θ ) N*P(\tau|\varTheta) N∗P(τ∣Θ),再乘上 1 N \dfrac{1}{N} N1再求和就近似前一项。
gradient ascent 梯度上升
- 从 Θ 0 \varTheta^0 Θ0开始
- Θ 1 ← Θ 0 + η ∇ R Θ 0 ‾ \varTheta^1\gets\varTheta^0+\eta\nabla\overline{R_{\varTheta^0}} Θ1←Θ0+η∇RΘ0
- Θ 2 ← Θ 1 + η ∇ R Θ 1 ‾ \varTheta^2\gets\varTheta^1+\eta\nabla\overline{R_{\varTheta^1}} Θ2←Θ1+η∇RΘ1
- … …
∇ R Θ 1 ‾ \nabla\overline{R_{\varTheta^1}} ∇RΘ1表示的是在 Θ 1 \varTheta^1 Θ1策略下获得的总奖励关于 Θ 1 \varTheta^1 Θ1的梯度,举个例子,当奖励是正的,说明这个策略是好的,那么就让当前的趋势,也就是奖励 R R R相对于 Θ \varTheta Θ的梯度,让 Θ \varTheta Θ保持这样的趋势,就是加上它。
求梯度
- R Θ ‾ = ∑ τ R ( τ ) P ( τ ∣ Θ ) \overline{R_\varTheta}=\sum\limits_{\tau}R(\tau)P(\tau|\varTheta) RΘ=τ∑R(τ)P(τ∣Θ)
∇ R Θ ‾ = ? \nabla\overline{R_{\varTheta}}=? ∇RΘ=?
-
∇
R
Θ
‾
=
∑
τ
R
(
τ
)
∇
P
(
τ
∣
Θ
)
=
∑
τ
R
(
τ
)
P
(
τ
∣
Θ
)
∇
P
(
τ
∣
Θ
)
P
(
τ
∣
Θ
)
\nabla\overline{R_{\varTheta}}=\sum\limits_{\tau}R(\tau)\nabla P(\tau|\varTheta)=\sum\limits_{\tau}R(\tau)P(\tau|\varTheta)\dfrac{\nabla P(\tau|\varTheta)}{P(\tau|\varTheta)}
∇RΘ=τ∑R(τ)∇P(τ∣Θ)=τ∑R(τ)P(τ∣Θ)P(τ∣Θ)∇P(τ∣Θ)
这里的 R ( τ ) R(\tau) R(τ)不一定是可微的,当成黑箱子也没关系
根据之前的公式 ∑ τ R ( τ ) P ( τ ∣ Θ ) ≈ 1 N Σ n = 1 N R ( τ n ) \sum\limits_{\tau}R(\tau)P(\tau|\varTheta)≈\dfrac{1}{N}\Sigma_{n=1}^NR(\tau^n) τ∑R(τ)P(τ∣Θ)≈N1Σn=1NR(τn),代入上式。 - ≈ 1 N Σ n = 1 N R ( τ n ) ∇ log P ( τ ∣ Θ ) ≈\dfrac{1}{N}\Sigma_{n=1}^NR(\tau^n)\nabla \log P(\tau|\varTheta) ≈N1Σn=1NR(τn)∇logP(τ∣Θ)
∇
log
P
(
τ
∣
Θ
)
=
?
\nabla \log P(\tau|\varTheta)=?
∇logP(τ∣Θ)=?
∇
log
P
(
τ
∣
Θ
)
=
Σ
t
=
1
T
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla \log P(\tau|\varTheta)=\Sigma_{t=1}^T \nabla \log p(a_t|s_t,\varTheta)
∇logP(τ∣Θ)=Σt=1T∇logp(at∣st,Θ)
综上
∇
R
Θ
‾
=
1
N
Σ
n
=
1
N
Σ
t
=
1
T
n
R
(
τ
n
)
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla\overline{R_{\varTheta}}=\dfrac{1}{N}\Sigma_{n=1}^N\Sigma_{t=1}^{T_n}R(\tau^n)\nabla \log p(a_t|s_t,\varTheta)
∇RΘ=N1Σn=1NΣt=1TnR(τn)∇logp(at∣st,Θ)
我说一下我对下面公式的理解,取N次抽象的路径,每个路径的总收益计算为R,每次actor的几率取log再微分,再总和这个路径上各个时间的类似操作,乘上之前的R,计算N次相加再平均。
直觉
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla \log p(a_t|s_t,\varTheta)
∇logp(at∣st,Θ) 为什么不是
∇
p
(
a
t
∣
s
t
,
Θ
)
\nabla p(a_t|s_t,\varTheta)
∇p(at∣st,Θ) 基于直觉的解释:

当上面情形出现的时候,如果选择
∇
p
(
a
t
∣
s
t
,
Θ
)
\nabla p(a_t|s_t,\varTheta)
∇p(at∣st,Θ)我们会认为执行动作b可以带来3的回报,与预期不符。选择
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla \log p(a_t|s_t,\varTheta)
∇logp(at∣st,Θ) 也就是除以
p
(
a
t
∣
s
t
,
Θ
)
p(a_t|s_t,\varTheta)
p(at∣st,Θ),可以展现每个动作的真实回报。
baseline
上述公式从
∇
R
Θ
‾
=
1
N
Σ
n
=
1
N
Σ
t
=
1
T
n
R
(
τ
n
)
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla\overline{R_{\varTheta}}=\dfrac{1}{N}\Sigma_{n=1}^N\Sigma_{t=1}^{T_n}R(\tau^n)\nabla \log p(a_t|s_t,\varTheta)
∇RΘ=N1Σn=1NΣt=1TnR(τn)∇logp(at∣st,Θ)
变为
∇
R
Θ
‾
=
1
N
Σ
n
=
1
N
Σ
t
=
1
T
n
(
R
−
b
)
(
τ
n
)
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla\overline{R_{\varTheta}}=\dfrac{1}{N}\Sigma_{n=1}^N\Sigma_{t=1}^{T_n}(R-b)(\tau^n)\nabla \log p(a_t|s_t,\varTheta)
∇RΘ=N1Σn=1NΣt=1Tn(R−b)(τn)∇logp(at∣st,Θ)
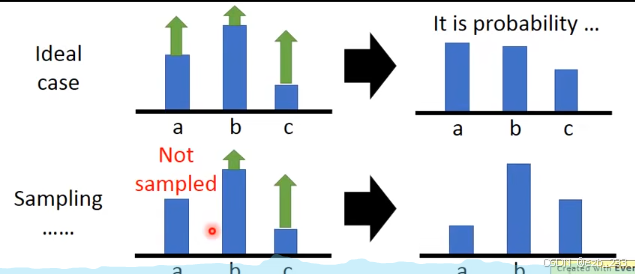
这是因为假如某个动作带来的回报很大,但是没有被抽样到,此时其他的动作带来的回报就会变得更大(抽样更多)。此时设置b为baseline,让其他回报小但抽样多的动作,得到的是负回报,这样最终的结果可以趋向于真实值。
从分类问题的角度看policy grandient
分类的目标函数
Minimize:
−
Σ
i
=
1
3
y
i
ˆ
log
y
i
-\Sigma_{i=1}^{3}\^{y_i}\log y_i
−Σi=13yiˆlogyi
也就是
Maximize:
Σ
i
=
1
3
log
y
i
\Sigma_{i=1}^{3}\log y_i
Σi=13logyi
我们的问题:
Maximize:
1
N
Σ
n
=
1
N
R
(
τ
n
)
∇
log
P
(
τ
∣
Θ
)
\dfrac{1}{N}\Sigma_{n=1}^NR(\tau^n)\nabla \log P(\tau|\varTheta)
N1Σn=1NR(τn)∇logP(τ∣Θ)
也就是
Maximize:
Σ
n
=
1
N
log
P
(
τ
∣
Θ
)
\Sigma_{n=1}^N \log P(\tau|\varTheta)
Σn=1NlogP(τ∣Θ)
所以可以说,我们的问题就类似于分类的问题
∇
R
Θ
‾
=
1
N
Σ
n
=
1
N
Σ
t
=
1
T
n
R
(
τ
n
)
∇
log
p
(
a
t
∣
s
t
,
Θ
)
\nabla\overline{R_{\varTheta}}=\dfrac{1}{N}\Sigma_{n=1}^N\Sigma_{t=1}^{T_n}R(\tau^n)\nabla \log p(a_t|s_t,\varTheta)
∇RΘ=N1Σn=1NΣt=1TnR(τn)∇logp(at∣st,Θ)
可以看成完全按照规定的轨迹走
R
(
τ
n
)
R(\tau^n)
R(τn)则是在N次抽样中,按照该轨迹走的次数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









