







目录
1. list的介绍及使用
1.1 list的介绍
cplusplus.com/reference/list/list/?kw=list![]() https://cplusplus.com/reference/list/list/?kw=list
https://cplusplus.com/reference/list/list/?kw=list
1.2 list的使用(带头双向循环链表)
1.2.1 list尾插及迭代器遍历链表
int main()
{
list<int> lt1;
//尾插
lt1.push_back(1);
lt1.push_back(2);
lt1.push_back(3);
lt1.push_back(4);
lt1.emplace_back(10);
//支持initializer_list初始化
list<int> lt2 = { 1,2,3,4,5 };
//迭代器 - 返回的底层就是带头双向循环链表
list<int>::iterator it1 = lt1.begin();
while (it1 != lt1.end())
{
cout << *it1 << " ";
it1++;
}
cout << endl;
//支持迭代器就支持范围for
for (auto e : lt2)
{
cout << e << " ";
}
cout << endl;
return 0;
}1.2.2 emplace_front
emplace_front和push_front的区别

int main()
{
list<Pos> lt;
Pos p1(1, 1);
//构造+拷贝构造
lt.push_back(p1);//pushback有名对象
cout << "*******" << endl;
lt.push_back(Pos(2,2));//pushback匿名对象
cout << "*******" << endl;
lt.push_back({3,3});//会隐式类型转换成Pos
cout << "*******" << endl;
lt.emplace_back(p1);
cout << "*******" << endl;
lt.emplace_back(Pos(2, 2));
cout << "*******" << endl;
//lt.emplace_back({ 3,3 });// - err
//可以传多个参数,也可以将初始化pos的值给传过去
//直接构造
lt.emplace_back( 3,3);
return 0;
} 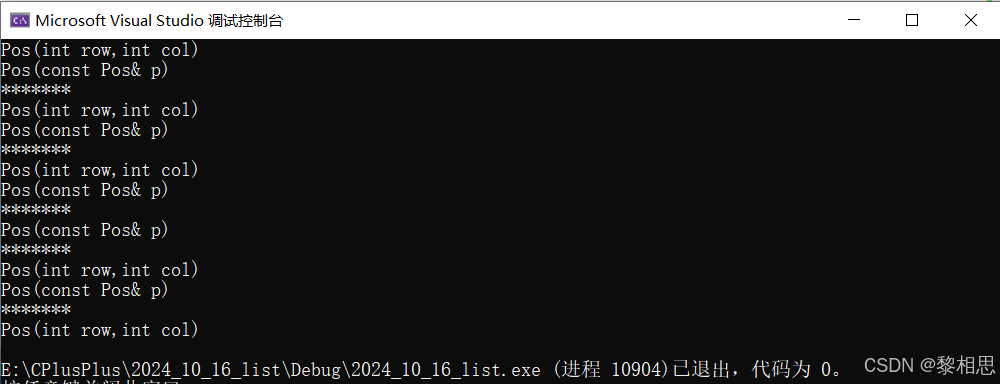
最后一个只有构造,他的优势是不仅仅可以传pos,也可以传构造pos的参数,构造pos的参数可能有很多哥,所以就有可变参数这个概念,接收到参数诸侯不去构造pos,参数直接往下传,传了之后直接去构造,所以其他的用法就是拷贝+构造,而最后一个是直接构造,所以emplace_back高效要看怎么用,像最后一个用法肯定更高效,像上面的用法就和push_back一样,但是不排除有的编译器会优化。
1.2.3 erase
int main()
{
list<int> lt1 = { 1,2,3,4,5 };
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
int x = 0;
cin >> x;
auto it = find(lt1.begin(), lt1.end(),x);
if (it != lt1.end())
{
lt1.erase(it);
}
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
return 0;
} 
1.2.4 swap
list::swap - C++ Reference![]() https://legacy.cplusplus.com/reference/list/list/swap/
https://legacy.cplusplus.com/reference/list/list/swap/
这个swap更高效,因为底层不是走什么深拷贝,只交换这里根节点的指针。
1.2.5 splice
list::splice - C++ Reference![]() https://legacy.cplusplus.com/reference/list/list/splice/将另一个链表的值转移到这个链表(转移不是粘贴)。
https://legacy.cplusplus.com/reference/list/list/splice/将另一个链表的值转移到这个链表(转移不是粘贴)。
// splicing lists
#include <iostream>
#include <list>
int main ()
{
std::list<int> mylist1, mylist2;
std::list<int>::iterator it;
// set some initial values:
for (int i=1; i<=4; ++i)
mylist1.push_back(i); // mylist1: 1 2 3 4
for (int i=1; i<=3; ++i)
mylist2.push_back(i*10); // mylist2: 10 20 30
it = mylist1.begin();
++it; // points to 2
mylist1.splice (it, mylist2); // mylist1: 1 10 20 30 2 3 4
// mylist2 (empty)
// "it" still points to 2 (the 5th element)
mylist2.splice (mylist2.begin(),mylist1, it);
// mylist1: 1 10 20 30 3 4
// mylist2: 2
// "it" is now invalid.
it = mylist1.begin();
std::advance(it,3); // "it" points now to 30
mylist1.splice ( mylist1.begin(), mylist1, it, mylist1.end());
// mylist1: 30 3 4 1 10 20
std::cout << "mylist1 contains:";
for (it=mylist1.begin(); it!=mylist1.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
std::cout << "mylist2 contains:";
for (it=mylist2.begin(); it!=mylist2.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}splice也可以用来调整链表的顺序。
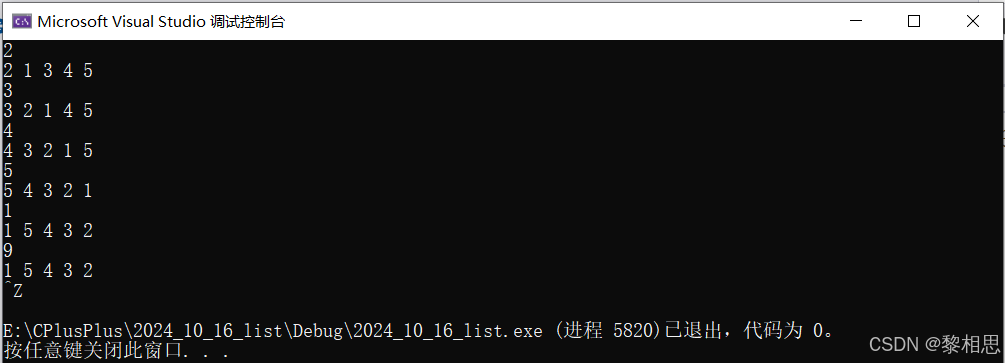
int main()
{
list<int> lt1 = { 1,2,3,4,5 };
//LRU - LRU是Least Recently Used的缩写,即最近最少使用。
int index = 0;
while (cin >> index)
{
auto pos = find(lt1.begin(),lt1.end(), index);
if (pos != lt1.end())
{
lt1.splice(lt1.begin(), lt1, pos);
}
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
}
return 0;
}
1.2.6 sort
list::sort - C++ Reference![]() https://legacy.cplusplus.com/reference/list/list/sort/
https://legacy.cplusplus.com/reference/list/list/sort/
int main()
{
list<int> lt1 = { 1,20,-3,40,5 };
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
lt1.sort();//默认排升序,排降序的话也有仿函数的概念
lt1.sort(greater<int>());//降序 - 归并排序
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
return 0;
}
这里有一个现象,list里面有一个sort的接口,而vector中没有,而vector用的话得去调算法库的sort,
int main()
{
vector<int> v1 = { 1,20,-3,40,5 };
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
//sort(v1.begin(), v1.end());//升序
sort(v1.begin(), v1.end(), greater<int>());//降序
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
return 0;
}
因为算法库的sort在链表中是不能用的,那就不得不说到迭代器的功能角度的分类,之前的迭代器就是const迭代器,const反向迭代器,反向迭代器,这些都是从使用上的角度分的,其实还有从功能的角度上分的:
单向迭代器:单向就只支持++,不支持-- forwad_list/unordered_xxx
双向迭代器:双向就是支持++也支持-- list
随机迭代器:随机就是支持++,也支持--,还支持+和- string/vector

库里面的sort虽然是模板啥都能传,但是名字以及暗示了必须传随机迭代器,因为sort的底层是快排,快排的底层为了效率会考虑三数取中,那就需要随机访问,底层走的是快排,需要随机访问,这样它的效率才会高,因为list不是随机迭代器,因为list会进行减,不是随机迭代器就不支持减,链表的双向迭代器不支持减,只有底层是连续的空间,两个位置减就算出距离了,链表可以减,但是效率太低了, 得遍历链表,所以以后用的时候得看名称,看它支持哪些迭代器,
看容器的迭代器是什么类型?



其实receres这个逆置函数得传双向迭代器。

那么问题就来了,如果要求是双向迭代器,那么传随机有没有问题,比如说上面的reverse传string或者vector的迭代器区间支持不?
其实是支持的, 其实这三种迭代器的关系可以说是继承关系,随机迭代器是特殊的双向迭代器,或者特殊的单向迭代器,随机迭代器的话就只能传随机,双向的话就只能传双向和随机,单向的话三个都可以传,
对比:
void test_op1()
{
srand(time(0));
const int N = 1000000;
list<int> lt1;
list<int> lt2;
vector<int> v;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
v.push_back(e);
}
int begin1 = clock();
// 排序
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
void test_op2()
{
srand(time(0));
const int N = 1000000;
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
lt1.push_back(e);
lt2.push_back(e);
}
int begin1 = clock();
// 拷贝vector
vector<int> v(lt2.begin(), lt2.end());
// 排序
sort(v.begin(), v.end());
// 拷贝回lt2
lt2.assign(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("list copy vector sort copy list sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
int main()
{
test_op1();
test_op2();
return 0;
}
vector算法底层用的是sort,sort底层是快排,快排底层用的是递归,也不是完全递归,使用了自省排序 ,递归在DeBug版本下特别吃亏,因为DeBug版本不会优化,一直建立栈帧,所以在测试递归的时候用Release。测试性能我们还要以Release为主,因为实践环境当中都是Release。
 test_op2()函数:
test_op2()函数:

把链表中的数据拷贝到vector中排好序然后再拷贝回来都比链表中的sort函数排序要快,所以list的sort如果有少量的数据排序还可以,如果数据量多就不要使用list中的sort, 因为它的效率相比vector还是差很多。
2. list源码
3. list的模拟实现
3.1 注意点
3.1.1 list中的迭代器
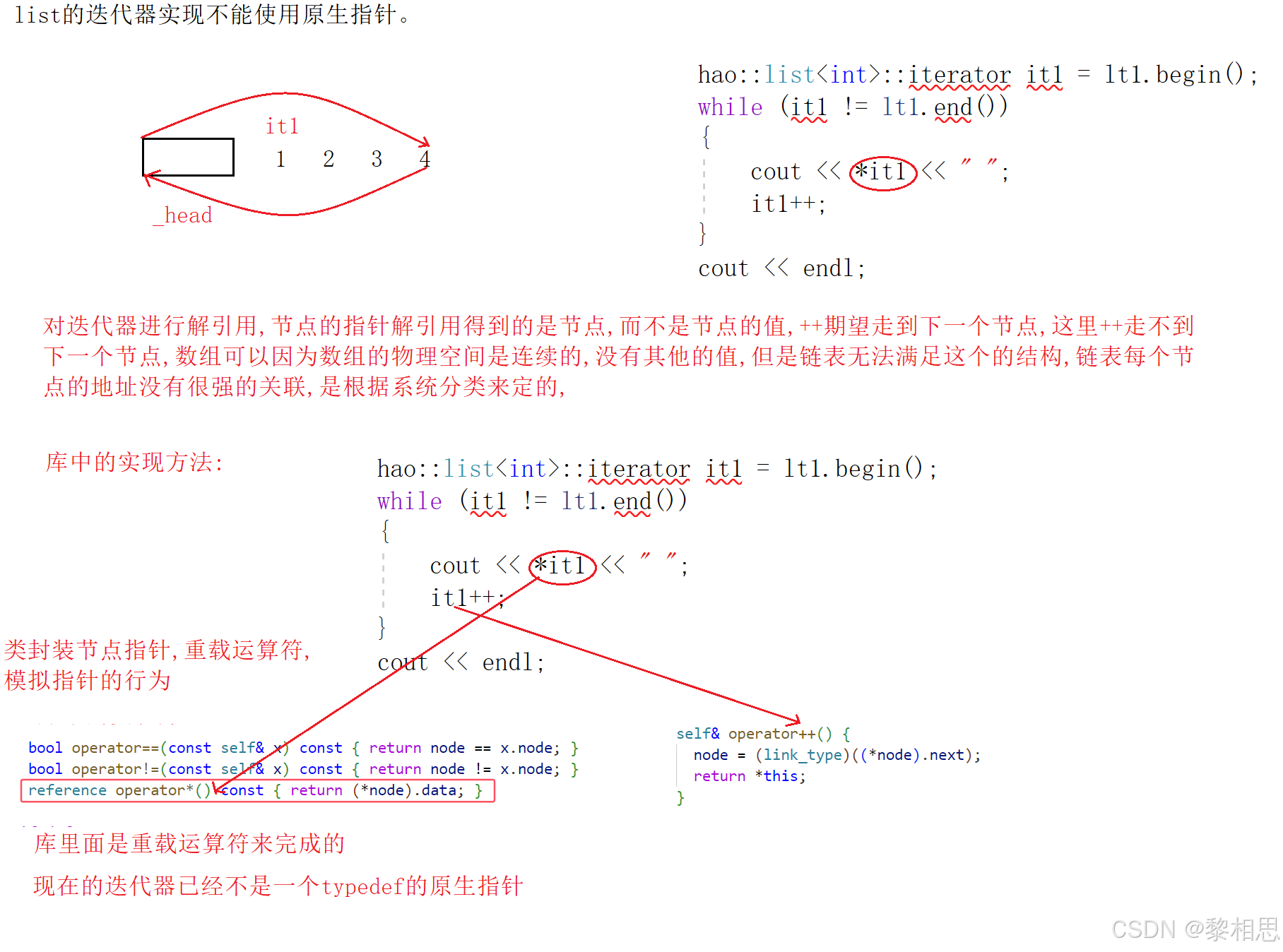
3.1.2 const迭代器

3.1.3 迭代器的构造

3.1.4 swap接口

3.1.5 size
size的话就要遍历链表,效率有点低,所以我们可以添加一个成员变量。
3.2 知识点
3.2.1 operator->

3.2.2 封装

3.2.3 类里面可以不加模板参数


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









