








一、数据库约束
1.1 not null
not null:指定某列不能为null值
create table student (
id int not null,
sn int,
name varchar(20),
qq_mail varchar(20)
);此时再往id这一列存入null值,就会报错
1.2 unique
unique:加上unique后,可以确保某一列或多列的值是不重复的,该列的每一行的值都是唯一的
create table student (
id int not null,
sn int unique,
name varchar(20),
qq_mail varchar(20)
);加上unique约束后,在对该列插入或修改数据时,会先查询你要插入或修改的值在该列的其他行有没有(确保没有重复),如果有则操作失败,没有则操作成功
1.3 default
default:设置默认值
代码示例:
create table student (
name varchar(20) default 'unknow',
qq_mail varchar(20)
);1.4 主键:primary key
主键相当于unique + not null,主键可以唯一地标识表中的每一行数据,通过主键,可以确保表中每一条数据都有唯一的标识符
一般指定id为主键:
create table student (
id int primary key auto_increment,
sn int unique,
name varchar(20),
qq_mail varchar(20)
);一般将整数设置为主键,且主键一般会配合auto_increments使用,其作用是自增,这样每次我们在表中新增一条数据时,不用手动设置主键的值,它会自动设置并且每次+1
注意:一个表中只能有一个主键
1.5 外键:foreign key
外键用于关联其他表的主键或唯一键(primary key 或 unique)
首先创建一个班级表t_class
drop table if exists t_class;
create table t_class (
id int primary key auto_increment,
name varchar(20)
);
创建一个学生表,将班级id字段设为外键
drop table if exists t_students;
create table t_students(
id int primary key,
name varchar(10),
class_id int,
foreign key (class_id) references t_class(id)
);向这两个表中插入相关数据:

此时班级表被称为父表
- 学生表中的这两名学生的class_id的值在班级表的id字段都存在,如果向学生表中再添加一行数据,使其class_id字段为100,那么结果会报错:
Error Code: 1452. Cannot add or update a child row: a foreign key constraint fails (`test_db`.`t_students`, CONSTRAINT `t_students_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `t_class` (`id`))
上述报错信息简单来说就是在插入和更新的数据中包含外键值,而这个外键值在父表中没有
- 如果将班级表中id = 2的数据删除,结果也会报错:
Error Code: 1451. Cannot delete or update a parent row: a foreign key constraint fails (`test_db`.`t_students`, CONSTRAINT `t_students_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `t_class` (`id`))
该错误信息表示不能删除该父行,因为该行被其他表的外键所引用
二、聚合查询
2.1 聚合函数
常见的计算总数、计算平均值等操作可以通过sql提供的聚合函数来完成:
| 函数 | 说明 |
| count ( [ distinct ] expr ) | 返回查询到的数据的数量 |
| sum ( [ distinct ] expr ) | 返回查询到的数据的总和,不是数字没有意义 |
| avg ( [ distinct ] expr ) | 返回查询到的数据的平均值,不是数字没有意义 |
| max ( [ distinct ] expr ) | 返回查询到的数据的最大值,不是数字没有意义 |
| min ( [ distinct ] expr ) | 返回查询到的数据的最小值,不是数字没有意义 |
注意事项:
- expr 可以是一个列名、表达式、*
- distinct 为可选关键字(可加可不加),如果加上则返回的数量是去除重复数据后的数量
下面用几个实例来讲解,依然采用 exam_result 这个表
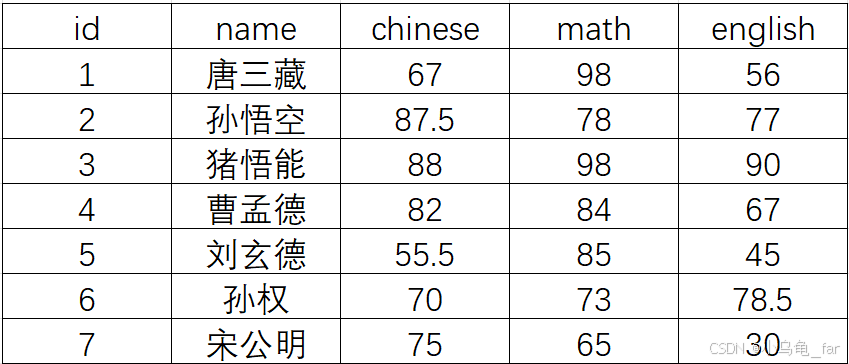
1. count ([distinct] expr)
#查询表格有几行
select count(*) from exam_result; #结果为7
#查询表格有几个 math
select count(math) from exam_result; #结果为72. sum ([distinct] expr)
#统计数学成绩的总分
select sum(math) from exam_result;
#统计英语不及格成绩的总分
select sum(english) from exam_result where english < 60;3. avg ([distinct] expr)
#统计全班总分的平均分
select avg(chinese + math + english) from exam_result;4. max ([distinct] expr)
#返回英语最高分
select max(english) from exam_result; #结果为905. min ([distinct] expr)
#返回60分以上的数学最低分
select min(math) from exam_result where math > 60; #结果为652.2 分组查询:group by
group by 子句可以指定某个列,针对这个列进行分组,然后可以对每个组进行聚合查询,下面来看具体的例子
创建一个临时表emp:
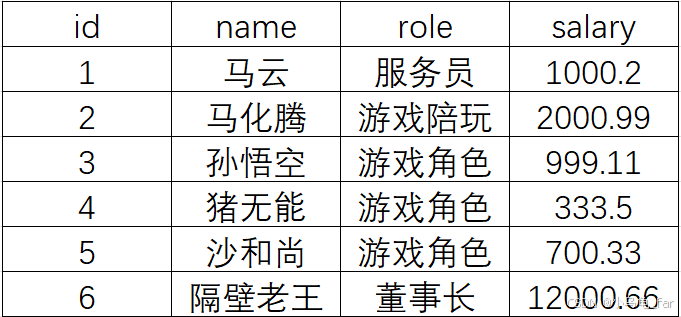
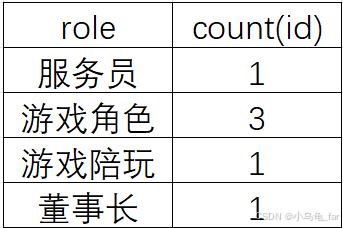
#查询每个岗位下有多少个人
select role count(id) from emp group by role;上述sql语句的执行逻辑如下:
- 首先查询所有role 和 id
- 将查询到的数据按照role进行分组
- 针对每一组进行聚合查询:count
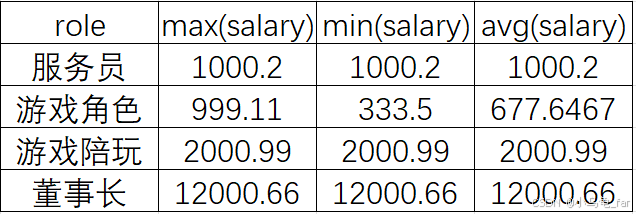
#查询每个岗位的最高工资、最低工资、平均工资
select role, max(salary), min(salary), avg(salary) from emp group by role;
2.3 having
having 就是给聚合函数指定条件,通常写在group by 之后
#显示平均工资低于1500的角色和它的平均工资
select role max(salary), min(salary), avg(salary) from emp group by role having avg(salary) < 1500;
如果要加where,则必须写在group by 的前面
#排除孙悟空的查询结果
select role max(salary), min(salary), avg(salary) from emp where name != '孙悟空' group by role having avg(salary) < 1500;

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









