







#首先准备好三台centos7版本的虚拟机
- - 输入yum install lrzsz -y ,以便于下面拉取包的操作,如下图所示,将kafka包拉进去
![]()
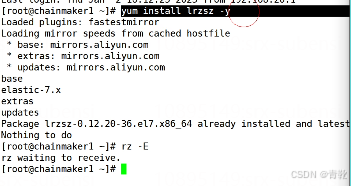
- -发送到所有会话,同时操控三个机器(先将三台虚拟机连接到xshell上面来)

#接下来是环境准备
yum源配置:
cd /etc/yum.repos.d #先进入这个目录
mkdir repo #新建一个repo目录
mv *.repo repo/ #这个命令是将原先的.repo源放进repo里面,为后续换阿里云源腾出位置
下载阿里云源:
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
下载阿里云源可能有点慢,这里可以将在 /etc/yum.repos.d/下新建一个a.repo文件,并将下面的文本内容输入进去:
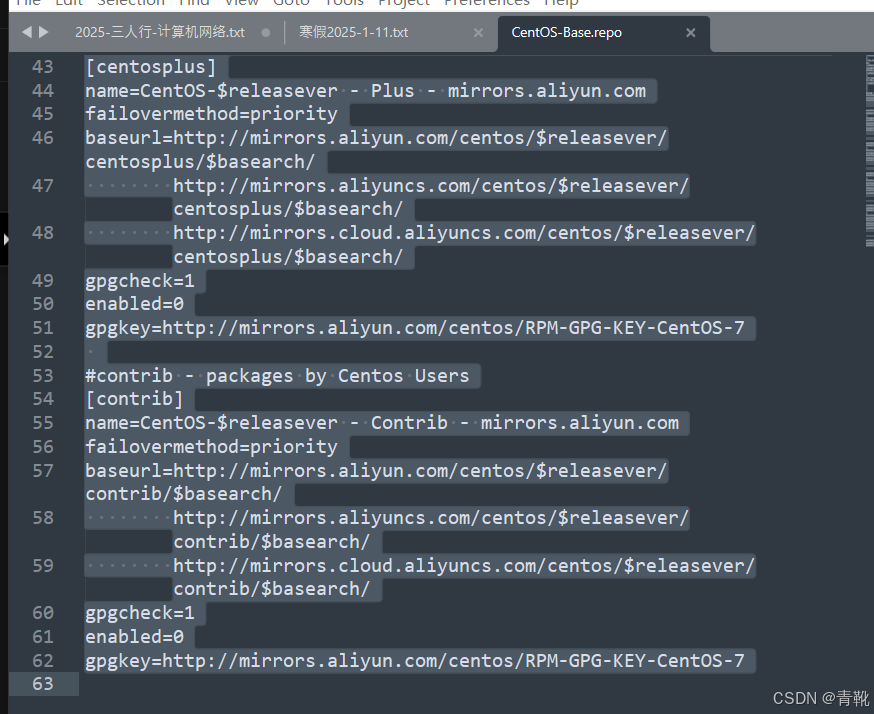
然后再下载阿里云源,这样会更快一点
curl -o /etc/yum.repos.d/a.repo http://mirrors.aliyun.com/repo/Centos-7.repo
下载依赖软件:
yum install epel-release -y
yum install wget vim java-11-openjdk.x86_64 -y
#配置静态ip地址,修改/etc/sysconfig/network-scripts/ifcfg-ens33:
只要修改最后五行
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
NAME=ens33
UUID=0f3239b9-6ba7-406e-94e8-fa7b680a4d82
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.223.163
NETMASK=255.255.255.0
GATEWAY=192.168.223.2 #这里是自己机器的网关(前三位)+后面一个2,也就是说这个223不是一样的,每个电脑都有自己所在的网关,而且三台机器必须是同一个网关才行
DNS1=114.114.114.114
配置完静态ip地址之后可以试着ping一下网络,看能不能通(按ctrl+c结束)
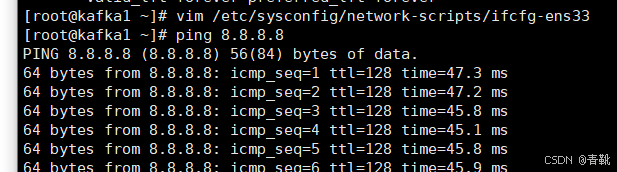
#配置主机名(做这一步的时候记得关掉“发送所有会话”,因为每个机器主机名不一样)
hostnamectl set-hostname kafka1
hostnamectl set-hostname kafka2
hostnamectl set-hostname kafka3
#修改/etc/hosts文件,添加主机名和ip地址映射(到这一步的时候可以打开发送所有会话了)
192.168.223.161 kafka1
192.168.223.162 kafka2
192.168.223.163 kafka3
#关闭防火墙与selinux
关闭防火墙:
iptables -F
systemctl stop firewalld
systemctl disable firewalld
关闭selinux,编辑/etc/selinux/config 文件
SELINUX=disabled
重启系统:
reboot
##接下来就是部署kafka集群了
#下载kafka
进入到opt目录下,没有就随便新建一个空目录
cd /opt
wget https://archive.apache.org/dist/kafka/3.6.1/kafka_2.13-3.6.1.tgz #到官方网站下载kafka,但速度可能有点慢(也可以事先下载好然后再拖进shell终端)
下面展示直接将下载好的压缩包拉取进去(每个机器拉取一次):
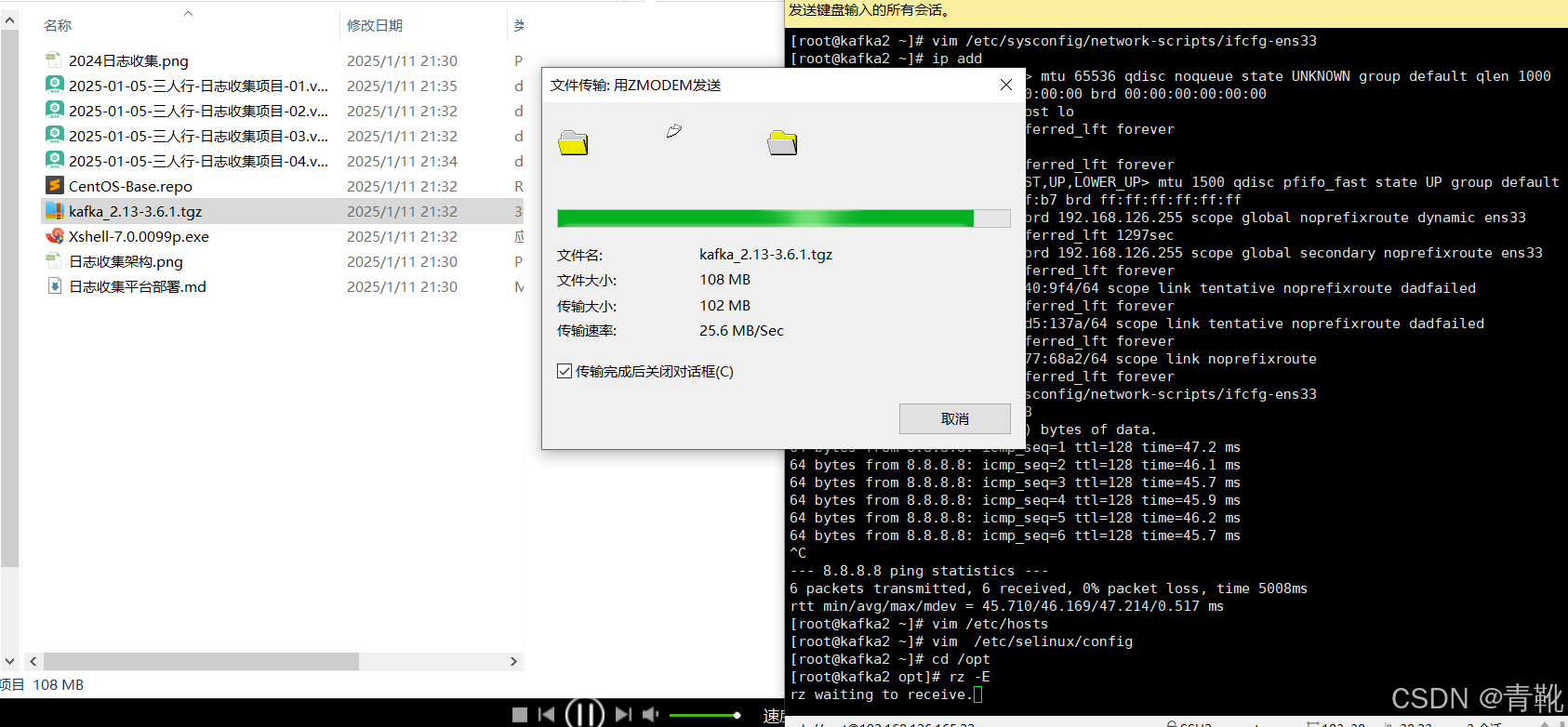
#解压缩
tar xf kafka_2.13-3.6.1.tgz
cd kafka_2.13-3.6.1
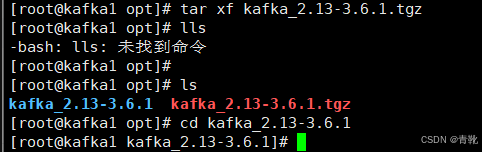
#修改配置文件,位于kafka目录下config/kraft/server.properties
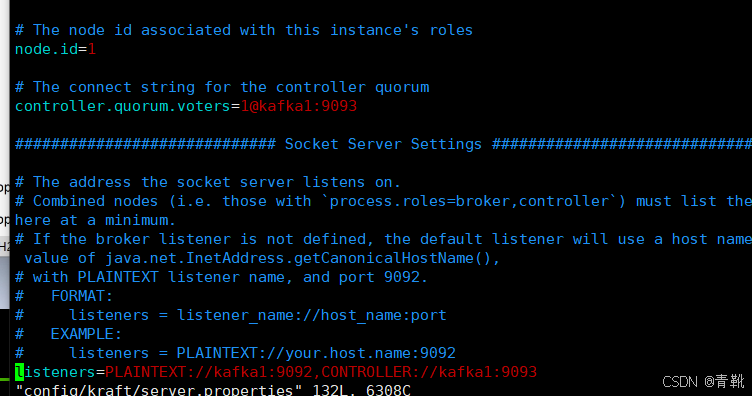
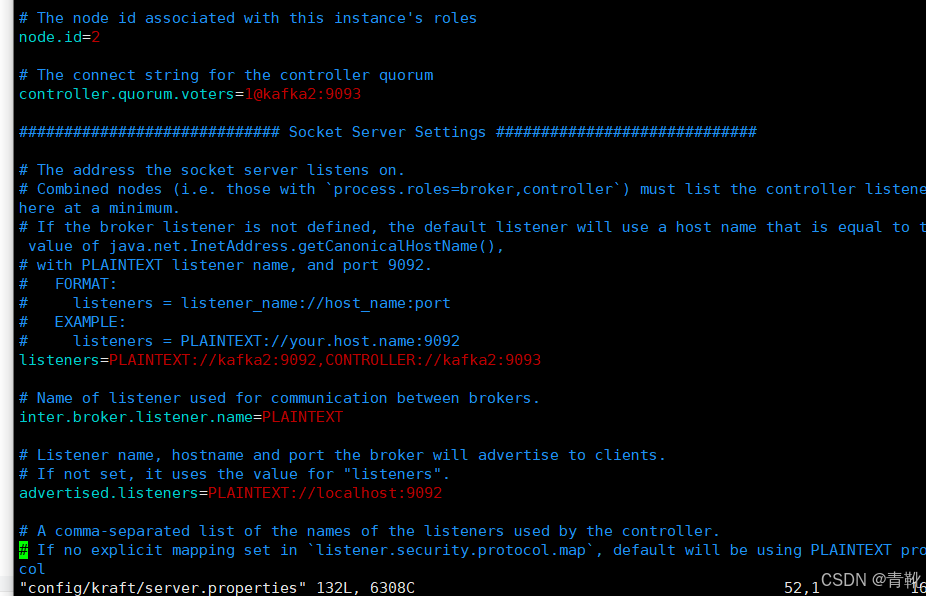
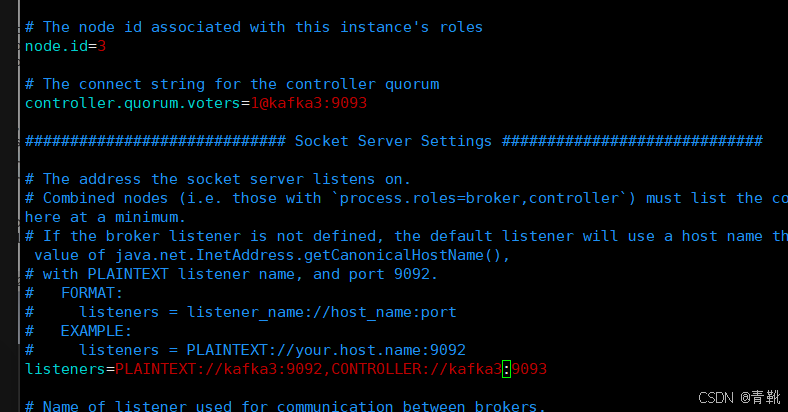
#修改节点id,每个节点唯一
node.id=1
##### -》修改这个的时候要关闭发送所有会话,第一个机器node.id=1,第二个机器 node.id=2,第三个机器node.id=3
#修改控制器投票列表
controller.quorum.voters=1@192.168.223.161:9093,2@192.168.223.162:9093,3@192.168.223.163:9093
##### -》地址部分改为每个机器对应的主机名(用IP地址也行,但为了方便推荐改为主 机名)
#修改监听器和控制器,绑定ip。其中kafka1为主机名,可用本机ip地址代替
listeners=PLAINTEXT://kafka1:9092,CONTROLLER://kafka1:9093
# 侦听器名称、主机名和代理将向客户端公布的端口.(broker 对外暴露的地址)
# 如果未设置,则使用"listeners"的值.
advertised.listeners=PLAINTEXT://kafka3:9092
只需改变以下三个地方,下图分别为kafka1,kafka2,kafka3机器:
-->配置文件的详解,详细讲解可见“日志收集平台部署配置文件详解”一文
#创建集群(这里一定要注意什么时候只在一台机器执行,什么时候发送所有会话)
cd /opt/kafka_2.13-3.6.1
# 在其中一台执行,生成集群UUID命令,拿到集群UUID保存在当前tmp_random文件中
bin/kafka-storage.sh random-uuid >tmp_random
# 查看uuid
[root@chainmaker1 kafka_2.13-3.6.1]# cat tmp_random
z3oq9M4IQguOBm2rt1ovmQ
# 在所有机器上执行,它会初始化存储区域,为 Kafka 集群的元数据存储和后续操作做好准备。z3oq9M4IQguOBm2rt1ovmQ为自己生成的集群uuid
bin/kafka-storage.sh format -t z3oq9M4IQguOBm2rt1ovmQ -c /opt/kafka_2.13-3.6.1/config/kraft/server.properties
#启动(有两种启动方式,推荐第二种)
第一种直接命令启动,但输入命令比较麻烦:
启动:
bin/kafka-server-start.sh -daemon /opt/kafka_2.13-3.6.1/config/kraft/server.properties
关闭:
bin/kafka-server-stop.sh
第二种使用systemctl管理服务启动 (为了方便管理,交给systemctl来启动):
##(进入以下文件,然后复制以下文本,要知道这些配置信息各有什么作用)
## 编辑文件 vim /usr/lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (KRaft mode)
Documentation=http://kafka.apache.org/documentation.html
After=network.target
[Service]
Type=forking
User=root
Group=root
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/lib/jvm/java-11-openjdk-11.0.23.0.9-2.el7_9.x86_64/bin/"
ExecStart=/opt/kafka_2.13-3.6.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.13-3.6.1/config/kraft/server.properties
ExecStop=/opt/kafka_2.13-3.6.1/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
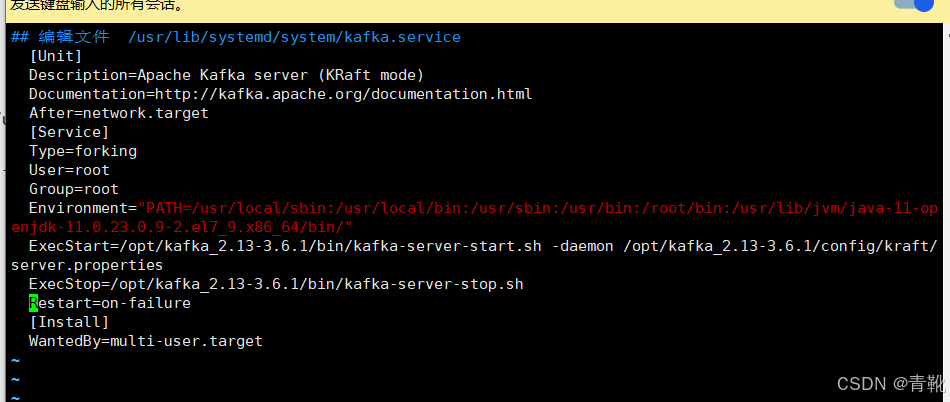
#输入前两个命令,启动kafka服务
#重新加载systemd配置
systemctl daemon-reload
#启动kafka服务
systemctl start kafka
#关闭kafka服务
systemctl stop kafka
#设置开机自启
systemctl enable kafka
#设置开机不自启
systemctl disable kafka
然后输入ps -ef|grep kafka看看kafka进程有没有启动,下面这样就表示kafka进程启动成功了
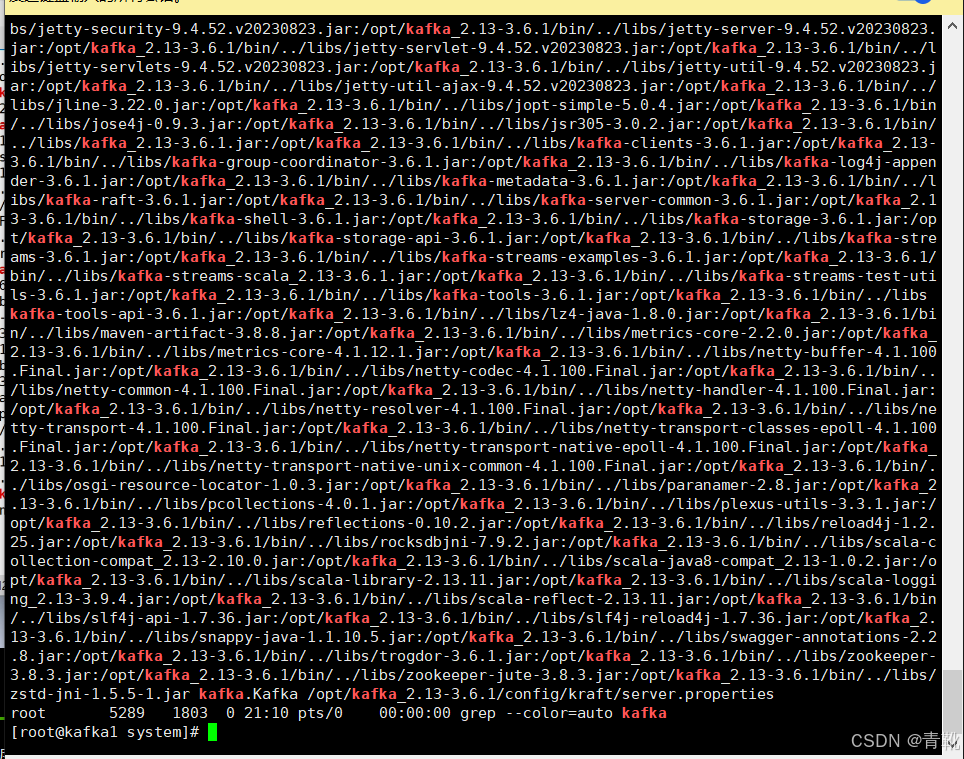
插入小知识:

后面两篇文章会详细介绍以下部分
#测试集群Kraft模式下Kafka脚本的使用-阿里云开发者社区 (aliyun.com)
# 创建topic
bin/kafka-topics.sh --create --bootstrap-server kafka3:9092 --replication-factor 3 --partitions 3 --topic my_topic
** --replication-factor指定副本因子,--partitions指定分区数,--topic指定主题名称。
# 查看topic
bin/kafka-topics.sh --list --bootstrap-server kafka3:9092
#创建生产者,发送消息,测试用
bin/kafka-console-producer.sh --broker-list kafka3:9092 --topic my_topic
#创建消费者,获取数据,测试用
bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic my_topic --from-beginning
#部署filebeat
安装:
1、rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
2、编辑 vim /etc/yum.repos.d/fb.repo
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3、yum安装
yum install filebeat -y
rpm -qa |grep filebeat #可以查看filebeat有没有安装 rpm -qa 是查看机器上安装的所有软件包
rpm -ql filebeat 查看filebeat安装到哪里去了,牵扯的文件有哪些
配置,修改配置文件/etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/messages
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.20.161:9092","192.168.20.162:9092","192.168.20.163:9093"]
topic: messagelog
keep_alive: 10s
创建主题
cd /opt/kafka_2.13-3.6.1
bin/kafka-topics.sh --create --bootstrap-server chainmaker3:9092 --replication-factor 3 --partitions 3 --topic messagelog
#nginx反向代理集群搭建
http://whois.pconline.com.cn/ipJson.jsp?ip=123.123.123.123&json=true


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









