







一、spark on yark的本质:
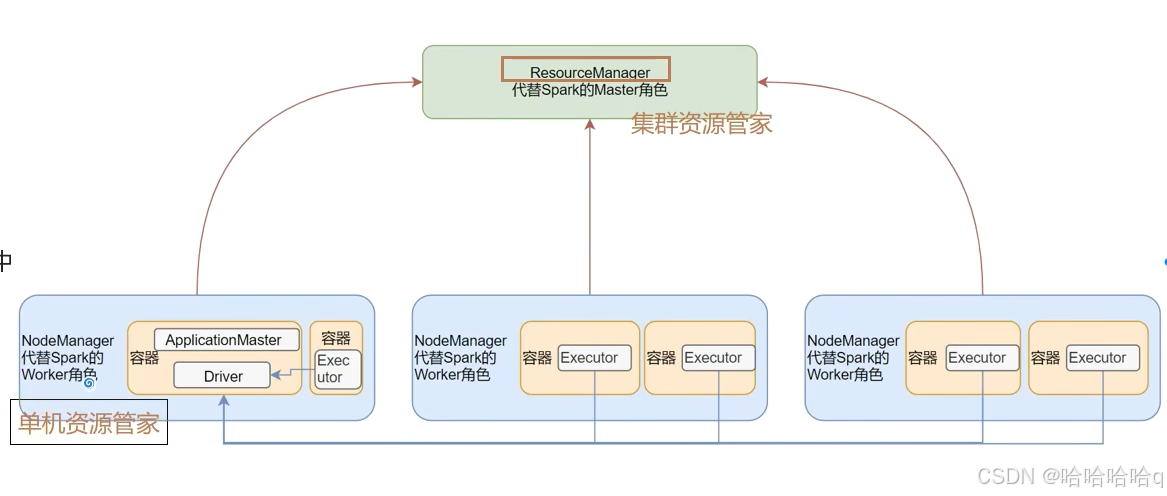
master角色由yarn的resourcemanager担任(集群资源管家)。
worker角色由nodemanager担任(单机资源管家)。
driver运行在yarn容器内或者提交任务的客户端过程内。
干活的executor运行在yarn提供的容器内。
需要什么?
yarn集群
spark客户端
被提交的代码程序
部署:
Hadoop和yarn的环境变量
袁神启动!
在此之前要启动Hadoop-yarn。并进入expert里面的spark文件夹,启动。
bin/pyspark --master yarn
集群调度交给yarn,计算交给spark的executor。
两种运行模式:
1.cluster模式:driver运行在yarn容器内部
spark-submit --master yarn --deploy-mode cluster my_spark_app.py
2.client模式:driver运行在客户端,以上指令为客户端。
1)
-
pyspark是 Spark 的交互式 PySpark Shell,通常用于在交互式 Python 环境(如 Jupyter Notebook 或终端)中运行 Spark 作业。pyspark --master yarn -
是 Spark 的应用程序提交工具,用于将打包好的 Spark 应用程序(如
.py或.jar文件)提交到集群上运行。spark-submit --master yarn --deploy-mode my_spark_app.py

















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









