







注:本文所有代码均在Spyder中正常运行
一、实验基本原理
运用Anaconda搭建的Jupyter notebook平台编写实例Python程序。
二、实验目的:
1、熟悉Python集成开发系统背景。
2、熟悉Jupyter Notebook开发环境。
3、熟悉编写程序的基本过程。
三、具体要求:
1、熟悉Python的基本语法,理解常量、变量、数据类型、运算符、复合数据类型、列表和字典等基本概念,灵活使用列表、字典等数据类型。
2、通过程序实例,熟练操作Jupyter Notebook平台,初步掌握Python程序设计的基本概念、编程规则和开发过程。
四、实验环境:
1、Windows 10电脑一台。
2、Anaconda、Python、Jupyter notebook平台。
五、实验内容:
实例1:简历卡片。
以卡片形式显示自己的简历:班级、学号、姓名、年龄、电话、QQ、通信地址等,界面越美观成绩越高。提示:使用print函数。

代码:
class_name = input("请输入班级:")
student_id = input("请输入学号:")
name = input("请输入姓名:")
age = input("请输入年龄:")
phone = input("请输入电话:")
qq = input("请输入 QQ:")
address = input("请输入通信地址:")
print("*"*20)
print(f"*班级:{class_name} ")
print(f"*学号:{student_id} ")
print(f"*姓名:{name}")
print(f"*年龄:{age} ")
print(f"*电话:{phone} ")
print(f"*QQ:{qq} ")
print(f"*通信地址:{address} ")
print("*"*20)实验结果:
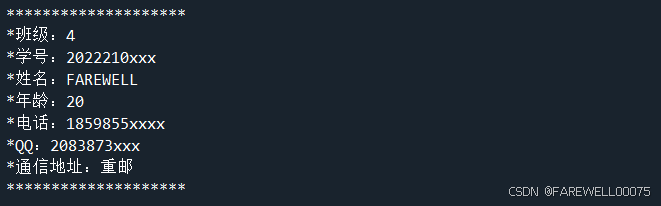
实例2:四则运算。
要求用户从键盘输入两个浮点型运算数(使用input函数),然后计算并输出二者的和、差、积、商。举例:如果输入的两个数是5.0与2.0,那么:
和值的输出格式为“5.00与2.00和的为:7.00”,使用占位符%f实现;
差值的输出使用占位符%d实现;
乘积的输出使用format()方法实现;
商值的输出使用f-strings方式实现;
要求输入的两个数,每个同学都不一样。
代码:
num1 = float(input("请输入第一个数:"))
num2 = float(input("请输入第二个数:"))
sum_result = num1 + num2
diff_result = int(num1 - num2)
product_result = num1 * num2
quotient_result = num1 / num2
print("%.2f 与 %.2f 和的为:%.2f" % (num1, num2, sum_result))
print("%d 与 %d 的差为:%d" % (int(num1), int(num2), diff_result))
print("{}与{}的积为:{}".format(num1, num2, product_result))#用format实现
print(f"{num1}与{num2}的商为:{quotient_result}")#用f-string实现运行结果:

实例3:字符串切片。
设计一个程序,输入是一个字符串“*重庆邮电大学-通信与信息工程学院-通信工程专业*”(样本字符串)。然后按下列要求操作。
(1)输出这个字符串的长度。
(2)用切片的方式用一句Python语句输出“重庆邮电大学”。
(3)用切片的方式用一句Python语句输出“重邮通信”。(提示:两次切片再拼接)
(4)用切片的方式用一句Python语句输出“通信”。(要求起始和结束使用反向索引)
(5)使用split方法切出三个子串,并逆序输出第二个子串。
(6)输出字符串中“通信”出现的次数。
(7)使用replace()方法将串中的“通信与信息工程”用“通信”替换,并输出替换后的串。
输出示例如下:
代码:
s = "*重庆邮电大学-通信与信息工程学院-通信工程专业*"
# 输出字符串的长度
print(len(s))
# 输出“重庆邮电大学”
print(s[1:7])
# 输出“重邮通信”
print(s[1]+s[3] + s[8:10])
# 输出“通信”(要求起始和结束使用反向索引)
print(s[-17:-15])
# 使用 split 方法切出三个子串,并逆序输出第二个子串
sub_strings = s[1:-1].split('-')
print(sub_strings[2])
# 输出字符串中“通信”出现的次数
print(s.count('通信'))
# 使用 replace()方法将串中的“通信与信息工程”用“通信”替换,并输出替换后的串
print(s.replace('通信与信息工程', '通信'))运行结果:

实例4:计算三角形面积。

代码:
import math
# 函数:计算三角形的面积
def calculate_triangle_area(a, b, c):
# 计算半周长
s = (a + b + c) / 2
# 使用海伦公式计算面积
area = math.sqrt(s * (s - a) * (s - b) * (s - c))
return area
# 主程序
def main():
print("请输入三角形的三边长度:")
# 接收用户输入
a = float(input("边长 a: "))
b = float(input("边长 b: "))
c = float(input("边长 c: "))
# 检查输入的边长是否能构成三角形
if a + b > c and a + c > b and b + c > a:
# 计算面积
area = calculate_triangle_area(a, b, c)
print(f"三角形的面积为: {area:.2f}")
else:
print("输入的边长无法构成三角形,请重新输入。")
if __name__ == "__main__":
main()
运行结果:

实例5:列表操作。
功能如下:
(1)从键盘输入5个城市的名字,存入一个列表中。要求:
① 第一个城市是你所在家乡的城市名。
② 用一个input函数完成5个城市名字的输入,如:
input("请输入5个城市的名字,用空格分隔:") 。
(2)将该列表中元素,即5个城市的名字用for循环遍历输出。
(3)用索引值输出列表中你家乡的名字。再切片输出所有其它城市名字。
(4)对该列表进行逆序输出。要求用两种方法完成。
方法一:切片法;方法二:使用reverse()方法,不改变原列表。
(5)对该列表进行降序排序,并输出。要求用两种方法完成。
方法一:sorted();方法二:sort()。
(6)对降序排序后的列表,用切片方法,输出你家乡的名字及其前面和后面的名字(如果有的话)。注:不能直接使用0、1、2、……这样的索引值,即你家乡城市名的索引值使用index()函数获得。提示:需要用if 语句。
(7)将你家乡城市的名字前面和后面的城市(如果有的话),改名为任意其他城市的名字,并输出。注:还是不能直接用数字作为索引值。提示:需要用if 语句,index()函数。
(8)将刚才改名的1个(如果你家乡所在城市排在第一位或最后一位)或2个城市的名字删除,并输出剩下的城市名字。注:还是不能直接用数字作为索引值。提示:需要用if 语句,index()函数。
代码:
# 主程序
def main():
# (1) 输入5个城市的名字
cities_input = input("请输入5个城市的名字,用空格分隔:")
cities = cities_input.split() # 将输入的城市名分割成列表
# 确保列表中有5个城市
if len(cities) != 5:
print("请确保输入5个城市的名字。")
return
# (2) 遍历输出列表中每个城市的名字
print("您输入的城市有:")
for city in cities:
print(city)
# (3) 输出家乡的名字及其他城市名字
hometown = cities[0] # 家乡是第一个城市
print(f"家乡城市名:{hometown}")
other_cities = cities[1:] # 切片输出其他城市
print("其他城市:", other_cities)
# (4) 逆序输出列表
# 方法一:切片法
reversed_cities_slice = cities[::-1]
print("逆序输出(切片法):", reversed_cities_slice)
# 方法二:使用 reverse() 方法
cities_reversed = cities.copy() # 复制原列表
cities_reversed.reverse() # 逆序
print("逆序输出(reverse() 方法):", cities_reversed)
# (5) 降序排序并输出
# 方法一:sorted()
sorted_cities = sorted(cities, reverse=True)
print("降序排序(sorted()):", sorted_cities)
# 方法二:使用 sort()
cities.sort(reverse=True)
print("降序排序(sort()):", cities)
# (6) 切片输出家乡及其前后城市
hometown_index = cities.index(hometown)
print("家乡及其前后城市:", end=' ')
if hometown_index > 0:
print(cities[hometown_index - 1], end=' ') # 前面的城市
print(hometown, end=' ')
if hometown_index < len(cities) - 1:
print(cities[hometown_index + 1]) # 后面的城市
# (7) 改名为其他城市
if hometown_index > 0:
cities[hometown_index - 1] = input("请输入一个新名字替换前面城市:")
if hometown_index < len(cities) - 1:
cities[hometown_index + 1] = input("请输入一个新名字替换后面城市:")
print("改名后的城市列表:", cities)
# (8) 删除改名的城市(如果有的话)
if hometown_index > 0:
del cities[hometown_index - 1] # 删除前面的城市
if hometown_index < len(cities) - 1:
del cities[hometown_index+1] # 删除后面的城市(现在的位置是删除后的索引)
print("剩下的城市名字:", cities)
if __name__ == "__main__":
main()
运行结果:

实例6:字典操作。
定义一个字典变量:
dic_country={"China":"Beijing","America":"Washington","Norway":"Oslo","Japan":"Tokyo","Germany":"Berlin","Canada":"Ottawa","France":"Paris","Thailand":"Bangkok"}。
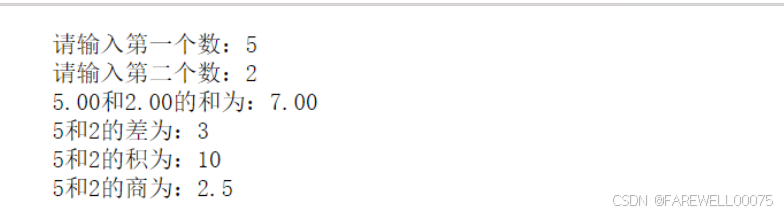
用input函数“请输入国家名:”,如果国家存在,用format函数输出首都名。格式为首都名:Beijing。如果这个国家不存在,请输出"未查询到该国家名!"。如:
请输入国家名:CHINA
首都名:Beijing
请输入国家名:SDG
未查询到该国家名!
代码:
# 定义字典,所有国家名转换为小写
dic_country = {
"china": "Beijing",
"america": "Washington",
"norway": "Oslo",
"japan": "Tokyo",
"germany": "Berlin",
"canada": "Ottawa",
"france": "Paris",
"thailand": "Bangkok"
}
# 主程序
def main():
# 输入国家名
country_name = input("请输入国家名:").strip().lower() # 去除前后空格并转换为小写
# 查找首都并输出
capital = dic_country.get(country_name) # 使用小写形式查找
if capital:
print("首都名:{}".format(capital))
else:
print("未查询到该国家名!")
if __name__ == "__main__":
main()
运行结果:
六:思考题
实例1:列表嵌套。
编写一个与嵌套列表相关的程序。功能如下:
(1)用语句:nested_list_XYY= [[1,3,2], [6,4,5], [8,9,7]]定义一个嵌套列表。说明:
- 其中X是你的班号,YY是你的一位或两位学号, 9个数字依次是学号,以及以学号为中心前后各4个数字。如题目中的9个数字是学号为5的示例。最小的3个数字保证在第一行,3个数字的顺序随意;中间3个数字保证在第二行,3个数字顺序随意;最大的3个数字保证在第三行,3个数字的顺序随意);
- 每个同学需要修改此样本数据,方法:5改成你的一位或两位学号,如:15号同学的实验用数据可以是[ [13,11,12], [16, 15, 14], [18, 17,19]]。
- 若有1到4号的同学,学号请改为: 60+你的学号。
(2)将该嵌套列表中的每一行中的3个数字升序排序,并输出排序后的嵌套列表。
(3)将排序后的嵌套列表转化成一个非嵌套列表(俗称压平),名字为:list_XYY,其中X是你的班号,YY是你的两位学号。并遍历输出压平后的列表。
代码:
# 定义嵌套列表
nested_list_420 = [[17, 16, 18], [19, 21, 20], [24, 22, 23]]
# (2) 将每一行中的3个数字升序排序
sorted_nested_list = []
for row in nested_list_420:
sorted_row = sorted(row) # 对每一行进行排序
sorted_nested_list.append(sorted_row) # 将排序后的行添加到新列表
# 输出排序后的嵌套列表
print("排序后的嵌套列表:")
for row in sorted_nested_list:
print(row)
# (3) 将排序后的嵌套列表转化为一个非嵌套列表
list_420 = [] # 创建一个空列表用于存放压平后的结果
for row in sorted_nested_list:
for num in row:
list_420.append(num) # 将每个数字添加到非嵌套列表
# 遍历输出压平后的列表
print("\n压平后的列表:", end=" ")
for num in list_420:
print(num, end=" ")
运行结果:

实例2:成绩统计。
假设已有字典变量dic_score存储了学生的成绩信息,姓名为键。语文、数学、英语、计算机的成绩为值。
dic_score={"张三":[88,90,98,95],"李四":[85,92,95,98],"王五":[89,89,90,92],"丁六":[82,86,89,90]}
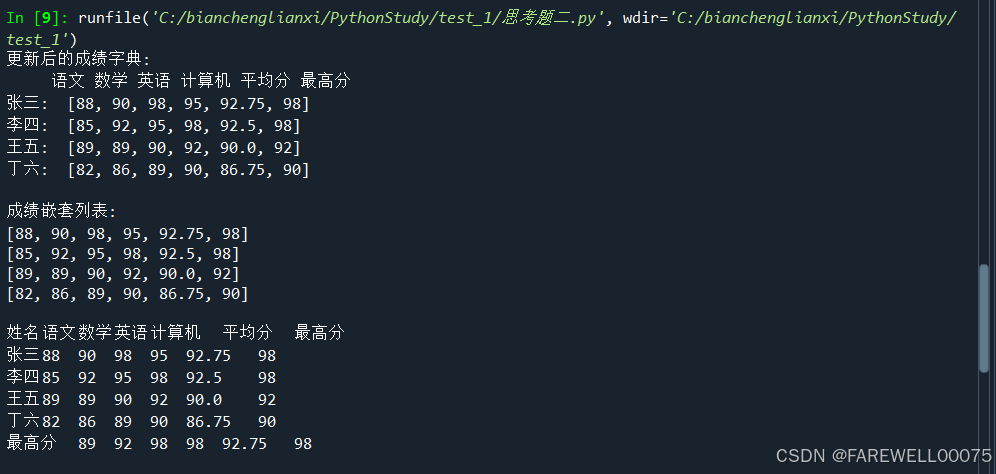
(1)试编写程序,统计每名学生的平均成绩和最高成绩,添加至每个学生成绩的后面,最后将字典输出。
(2)将(1)中的成绩形成嵌套列表输出。
(3)求每门课的最高分,作为新的键和值存入字典,并按照如下格式输出。
姓名 语文 数学 英语 计算机 平均分 最高分
张三 88 90 98 95 92.75 98
李四 85 92 95 98 92.5 98
王五 89 89 90 92 90.0 92
丁六 82 86 89 90 86.75 90
最高分 89 92 98 98 92.75 98
代码:
# 定义字典
dic_score = {
"张三": [88, 90, 98, 95],
"李四": [85, 92, 95, 98],
"王五": [89, 89, 90, 92],
"丁六": [82, 86, 89, 90]
}
# (1) 统计每名学生的平均成绩和最高成绩
for name, scores in dic_score.items():
avg_score = sum(scores) / len(scores) # 计算平均分
max_score = max(scores) # 计算最高分
scores.append(avg_score) # 添加平均分
scores.append(max_score) # 添加最高分
# 输出更新后的字典
print("更新后的成绩字典:")
print(" 语文 数学 英语 计算机 平均分 最高分")
for name, scores in dic_score.items():
print(f"{name}: {scores}")
# (2) 将成绩形成嵌套列表输出
nested_scores = [scores for scores in dic_score.values()]
print("\n成绩嵌套列表:")
for scores in nested_scores:
print(scores)
# (3) 求每门课的最高分
subject_scores = list(zip(*nested_scores)) # 转置嵌套列表
highest_scores = [max(subject) for subject in subject_scores] # 计算每门课的最高分
# 输出表头
print("\n姓名\t语文\t数学\t英语\t计算机\t平均分\t最高分")
for i, (name, scores) in enumerate(dic_score.items()):
print(f"{name}\t" + "\t".join(f"{score}" for score in scores))
# 输出最高分
print("最高分\t" + "\t".join(f"{score}" for score in highest_scores))
运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











