






一、Ext2物理结构
Ext2第二代扩展文件系统(secend extended filesystem),是Linux内核所使用的文件系统。
Ext2文件系统特性:
1.磁盘块分为组
2.支持快速符号链接
3.在启动时支持对文件系统的状态进行自动的一致性检查
4.Ext2的索引节点中引入新的字段(快片、删除逻辑、日志)
1. 磁盘块分为组
Ext2将磁盘空间划分为多个连续的块组(Block Group),每个块组包含数据块、索引节点(inode)和控制结构(如超级块备份、块位图、inode位图)。这种设计的目的是:
- 减少磁头移动:相邻数据块和inode的物理位置靠近,提升连续读写的效率。
- 增强可靠性:每个块组备份超级块和组描述符,即使部分块组损坏,仍可通过备份恢复数据。
- 优化碎片管理:通过块组内的预分配机制(如为文件预留连续块),减少文件碎片。
2. 支持快速符号链接
Ext2对符号链接(Symbolic Link)进行了优化:
- 若符号链接的路径名不超过60字节,则直接存储在inode的
i_block[]字段中,无需额外分配数据块。- 这种设计避免了读取数据块的开销,显著缩短了符号链接的解析时间。
3. 启动时支持自动一致性检查
Ext2通过外部工具
e2fsck(Ext2文件系统检查工具)实现自动一致性检查,触发条件包括:
- 系统崩溃后:检查元数据(如超级块、inode、目录结构)是否一致。
- 挂载次数或时间阈值:例如每挂载30次或超过180天未检查时强制触发。
- 修复机制:例如修复inode硬链接计数错误或孤立文件。
4. 索引节点中的新字段
问题中提到的“快片、删除逻辑、日志”属于Ext2的扩展功能或未来计划,但需注意部分特性并未在原生Ext2中完全实现:
- 块碎片化(Block Fragmentation):
允许将多个小文件片段存储在同一块中,以减少空间浪费。该功能在Ext2设计中被提及,但实际依赖外部补丁或后续文件系统(如Ext4)实现。- 逻辑删除(Undelete):
Ext2的inode预留了逻辑删除支持字段,但原生功能需借助外部工具(如e2undel)恢复已删除文件。- 日志(Journaling):
原生Ext2不支持日志功能,日志功能是Ext3的核心改进。但Ext2的inode结构中预留了字段,允许通过外部补丁或转换为Ext3实现日志。
必须建立各种结构(在内核中定义为 C 语言数据类型),来存放文件系统的数据,包括文件内容、目录层次结构的表示、相关的管理数据(如访问权限或与用户和组的关联),以及用于管理文件系统内部信息的元数据。这些对从块设备读取数据进行分析而言,都是必要的。
这些结构的持久副本显然需要存储在硬盘上,这样数据在两次会话之间不会丢失。下一次启动重新激活内核时,数据仍然是可用的。因为硬盘和物理内存的需求不同,同一数据结构通常会有两个版本。一个用于在磁盘上的持久存储,另一个用于在内存中的处理。
1.Ext2文件系统专注于高性能
支持块变长,使得文件系统能够处理预期的应用;快速符号链接,如果链接目标的路径足够短,则将其存储在inode自身中;将扩展能力集成到设计当中,从旧版本迁移到新版本时,无需重新格式化和重新加载硬盘;Ext2有一个非常大的有点(与现代文件系统相比,Ext2文件系统的代码非常紧凑,与JFS的超过30000行代码,XFS大约90000行代码相比,Ext2用不超过10000行代码足以实现)。
2.块(block)有两个含义
a.有些文件系统存储在面向块的设备上,与设备之间的数据传输都以块为单位进行,不会传输单个字符。
b.Ext2文件系统是一种基于块的文件系统,它将硬盘划分为若干个块,每个块的大小都相同,按块管理元数据和文件内容。
块组是该文件系统的基本成分,容纳文件系统其他结构,每个文件系统都由大量块组成,直接在硬盘上相继排列。

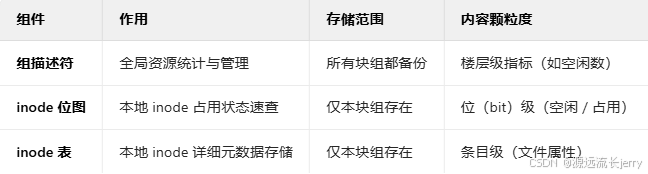
1. 超级块
- 作用:超级块是存储文件系统自身元数据的核心结构,包含文件系统的整体信息(如块大小、块组数量、inode 总数等)。
- 特性:内核仅通过第一个块组的超级块读取文件系统元信息,它是文件系统初始化、挂载等操作的关键依据,记录着文件系统的 “全局配置”。
2. 组描述符
- 作用:反映文件系统中各个块组的状态,例如块组中空闲块数量、空闲 inode 数量、块位图位置、inode 位图位置等。
- 特性:每个块组都保存了文件系统中所有块组的组描述符信息。这意味着无论访问哪个块组,都能获取到整个文件系统块组的状态,便于统一管理和资源分配。
3. 数据块位图和 inode 位图
- 作用:
- 数据块位图:通过二进制位(比特位)记录块组中数据块的使用状态,每一位对应一个块(如 “0” 表示空闲,“1” 表示已占用)。
- inode 位图:同样以二进制位记录块组中 inode 的使用状态,标记哪些 inode 已分配给文件 / 目录,哪些空闲。
- 特性:两者是文件系统管理存储资源(块与 inode)的 “地图”,通过位图可快速定位空闲或已用资源。
4. inode 表
- 作用:保存块组中所有 inode 的数据。每个 inode 记录了文件或目录的元数据,包括文件大小、权限、所有者、数据块指针(指向文件内容所在的数据块)等关键信息。
- 特性:文件系统通过 inode 表管理文件 / 目录的属性和数据关联,是文件元数据的核心存储单元,读取文件属性或定位文件内容时,都依赖 inode 表的信息。
二、Ext2数据结构
1.超级块
超级块是文件系统的核心结构,保存了文件系统所有的特征数据。内核在装载文件系统时,最先看到的就是超级块的内容,使用ext2_super_block定义。
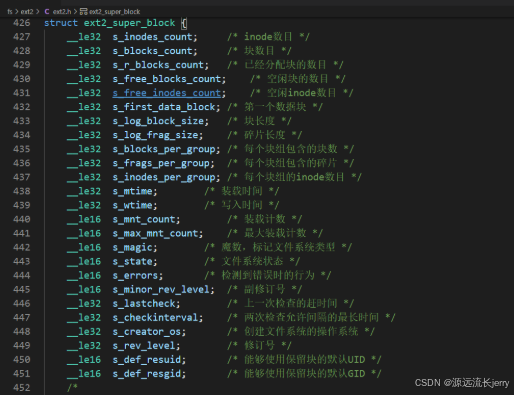
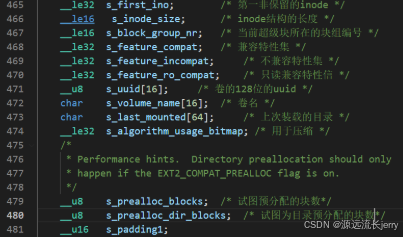
s_magic字段存储一个魔数,该数值确认装载的文件系统确实是Ext2类型,s_minor_rev_level用于区分文件系统的不同版本。
2.组描述符
每个块组都是一个组描述符的集合,紧随超级块之后。其中保存的信息反映了文件系统每个块组的内容,因此不仅关系到当前块组的数据块,还与其他块组的数据块和inode块相关。用于定义单个组描述符的数据结构比超级块结构短得多。
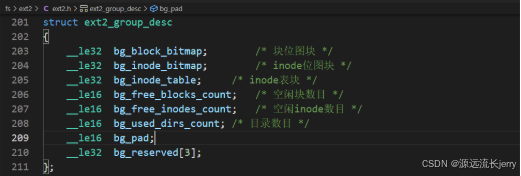
1. 组描述符的作用:楼层管理员的 “全局地图”
- 每个楼层管理员(块组)都有一张完整的 “图书馆地图”:
组描述符记录了整个文件系统中所有块组的状态,比如每个楼层(块组)有多少空书架(空闲 inode)、多少空位置(空闲数据块)、以及这些空位置的具体分布(位图位置)。
这意味着,即使你在第 3 层(块组 3),也能通过组描述符知道第 1 层(块组 1)是否有空书架,方便快速分配资源。2. 组描述符的结构:比超级块更 “精简”
- 超级块相当于图书馆的 “总规划图”,记录整个图书馆的总面积、楼层数、书籍存储规则等全局信息。
- 组描述符则像楼层管理员的 “速查表”,只关注每个楼层的实时状态(如当前空书架数量、空位置分布),数据结构更短,读取更快。
例如:
- 总规划图(超级块)可能有几十页纸,而速查表(组描述符)每页只记录关键指标,如 “第 3 层:空书架 3 个,空位置 5 个,位图在第 X 页”。
3. 为什么每个块组都要保存所有组描述符?
- 冗余备份,防止单点故障:
如果所有组描述符只保存在第 1 层(块组 0),一旦第 1 层损坏,整个图书馆的管理就会瘫痪。
因此,每个楼层都复制一份完整的组描述符,这样即使某个楼层着火,其他楼层的管理员仍能通过自己手中的地图继续管理整个图书馆。
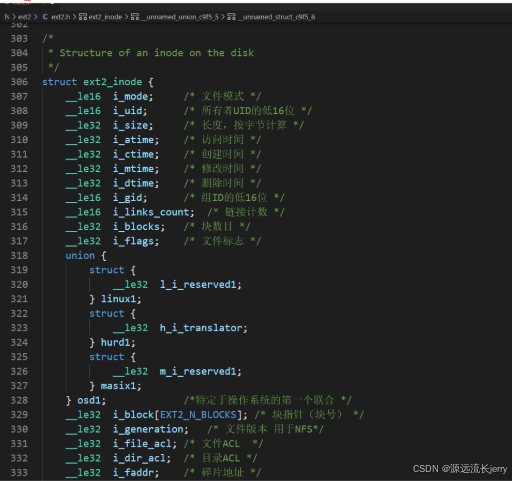
3.inode
每个块组都包含一个inode位图和一个本地inode表,inode表可能延续到几个块。位图的内容与本地块组相关,不会复制到文件系统的任何其他位置。inode位图用于概述块组中已用的和空闲的inode。
4.目录和文件
文件系统的拓扑结构,在经典UNIX文件系统中,目录不过是一种特殊的文件,其中是inode指针和对应的文件名列表,表示了当前目录下的文件和子目录。对于Ext2文件系统也是这样。每个目录表示为一个inode,会对其分配数据块。数据块中包含了用于描述目录项的结构。

5.访问文件流程
1. 用户发起请求:“我要读 /home/user/doc.txt”
- 类比:读者对图书管理员说:“我要借 1 楼 / 科技区 / 张三 / 文档.txt”。
- 系统响应:从根目录开始,逐层解析路径,找到文件的 inode。
2. 第一步:解析路径,找到文件的 inode
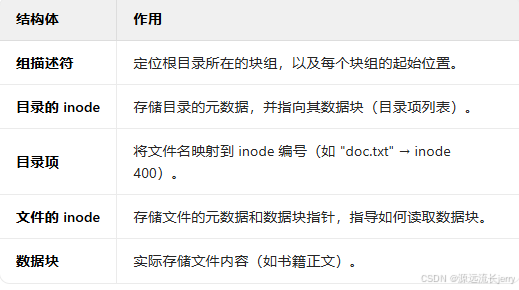
(1)根目录(/)的 inode
- 组描述符:记录根目录所在的块组(假设在块组 1)。
- 根目录的 inode 表:在块组 1 的 inode 表中找到根目录的 inode(通常是 inode 2)。
- 根目录的数据块:存储目录项,例如:
(2)进入 home 目录
- 根据 inode 100:找到 home 目录的元数据(权限、大小等),并读取其数据块。
- home 目录的数据块:存储子目录项,例如:
(3)进入 user 目录
- 根据 inode 300:找到 user 目录的元数据,并读取其数据块。
- user 目录的数据块:存储文件和子目录项,例如:
(4)找到目标文件 doc.txt 的 inode
- 根据 inode 400:获取文件的元数据(如文件大小、创建时间、数据块指针)。
3. 第二步:通过 inode 读取数据块
(1)inode 的数据块指针结构
假设 inode 400 的数据块指针如下:
- 直接块指针:指向前 12 个数据块(块号 1000~1011)。
- 间接块指针:指向一个块,该块存储额外的块号(如块 1012)。
- 双重间接块指针:指向一个块,该块存储多个间接块指针(适用于大文件)。
(2)读取所有数据块
- 小文件:直接通过直接块指针读取前 12 个块。
- 中等文件:读取直接块后,再读取间接块中的额外块号。
- 大文件:递归读取双重间接块、三重间接块等。
(3)示例流程
假设 doc.txt 占用 15 个块:
- 读取直接块指针指向的 12 个块(1000~1011)。
- 读取间接块指针指向的块 1012,其中包含块号 1013~1024。
- 最终读取块 1000~1024 的内容,拼接成完整文件。
4. 第三步:将数据块内容返回给用户
- 内核将数据块内容从磁盘读取到内存缓冲区。
- 用户程序通过系统调用获取内存中的数据,完成读取操作。
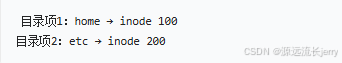
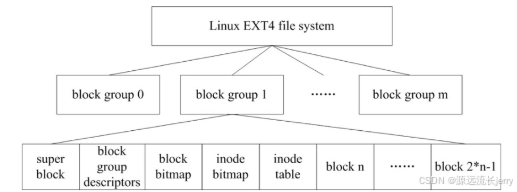
可以这样理解磁盘中有多个块组,一个块组有多个块,每个块为4KB,每个块组都有超级块,当然其他块组的超级快都是第一个块组超级块的备份,每个块组还有组描述符,inode位图、表以及数据块。可以类比以下图片:
三、Ext2文件系统操作
虚拟文件系统和具体实现之间的关联大体上有3个结构建立,结构中包含一系列函数指针。所有的文件系统都必须实现该关联。

Ext2文件系统对不同的文件类型提供了不同的file_operations实例。很自然,最常用的变体适用于普通文件。
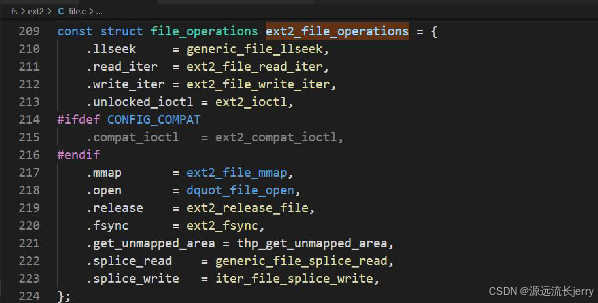
目录也有自身的file_operations实例:
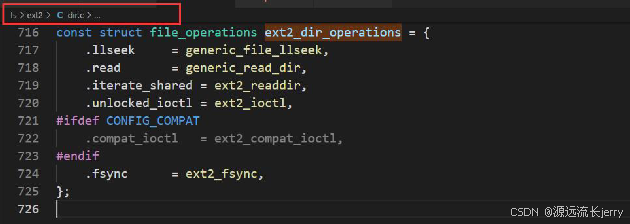
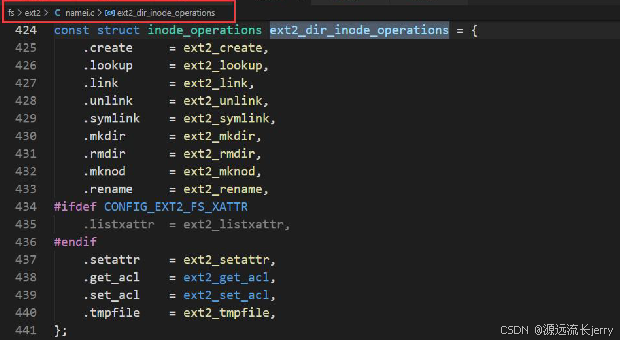
目录有更多可用的inode操作:
文件系统和块层通过address_space_operations关联:
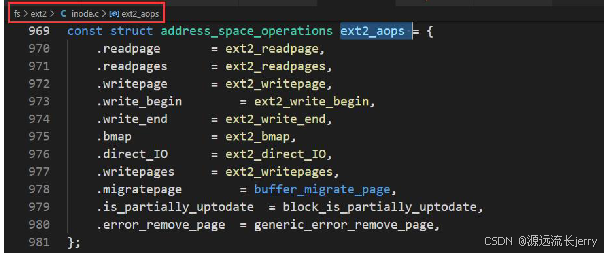
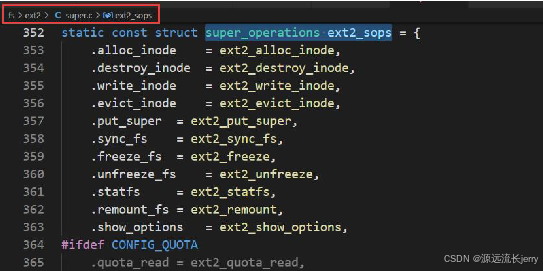
此结构用于与超级块交互:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









