






1.准备工作
安装GCC,已安装的请跳过该步骤;未安装的,请参考下面步骤安装:
1.确保网络通畅,然后以root用户执行命令:yum -y install gcc
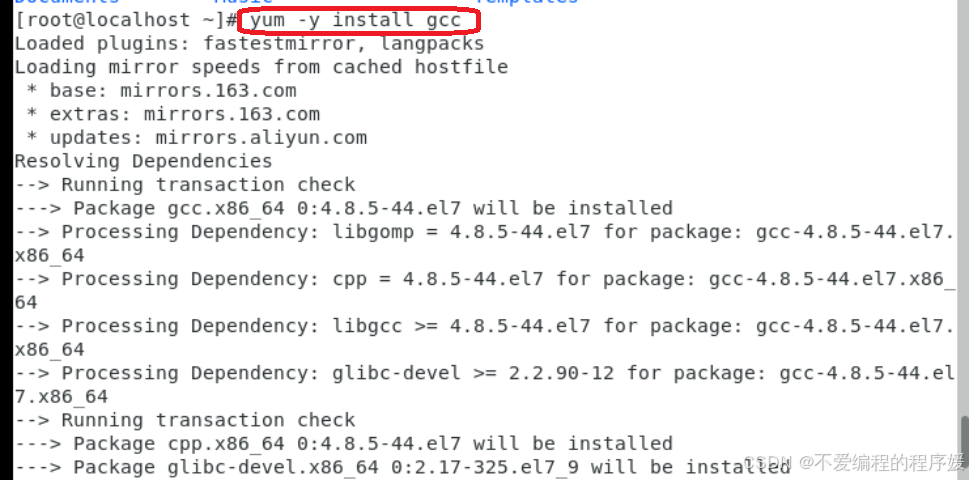
2.安装成功,通过gcc -v命令查看GCC版本,如下图
2.进程的家庭关系
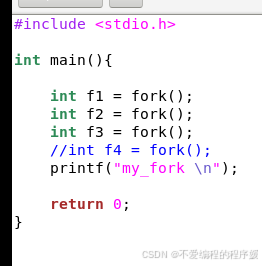
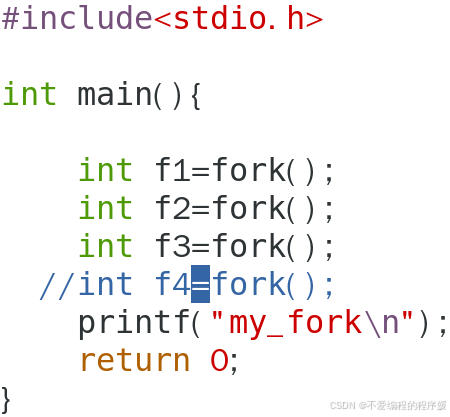
编写一个c程序,在主程序中执行3个fork()调用,最后输出一个字符串“my_fork”(即:printf("my_fork \n");)。运行该程序,并分析其运行结果。
程序如下:
执行结果如下:
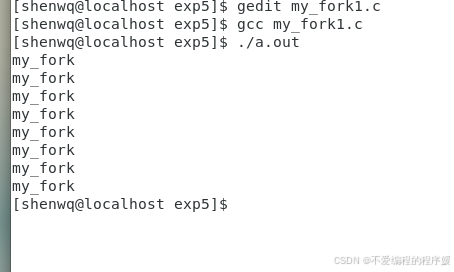
如图所示,
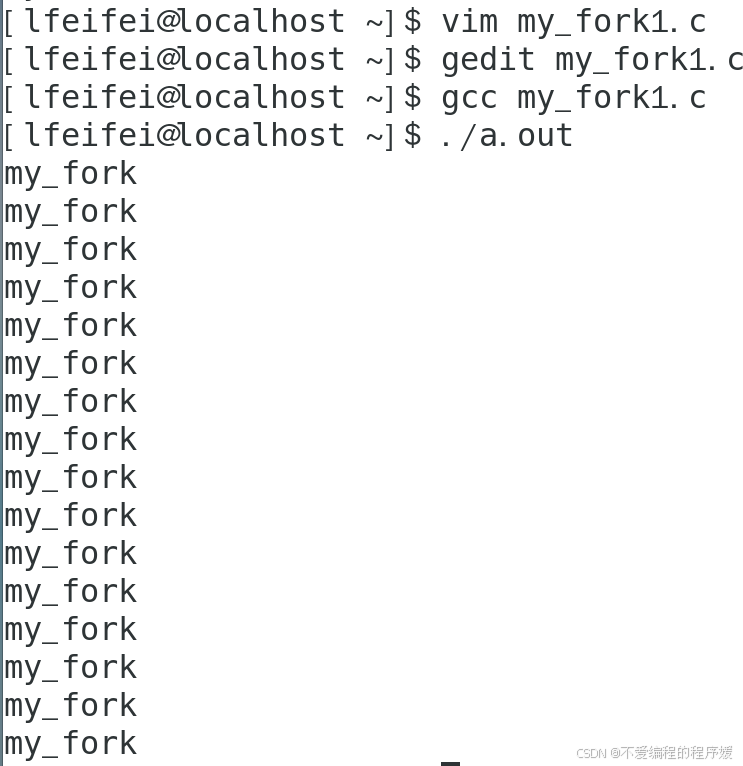
gedit my_fork1.c : gedit 是Linux系统中的一个文本编辑器,它提供了一个图形用户界面(GUI)来编辑文本文件。这条命令的作用是使用gedit编辑器打开名为my_fork1.c的文件,以便用户可以查看或修改文件内容。
gcc my_fork1.c: gcc 是GNU编译器集合(GNU Compiler Collection)的一部分,它是一个用于编译C语言程序的编译器。这条命令的作用是将my_fork1.c文件(C语言源代码文件)编译成可执行文件。默认情况下,gcc编译器生成的可执行文件名为a.out。
./a.out: 这条命令用于执行上一步编译生成的可执行文件。./ 表示执行当前目录下的文件。a.out 是gcc编译器默认生成的可执行文件名。这条命令的作用是运行编译后的程序,即执行my_fork1.c源代码编译得到的程序。
关于fork函数:fork()函数执行时会复制调用它的进程,创建一个新的进程,新进程的PID(进程ID)会作为fork()函数的返回值。在父进程中,fork()返回新创建的子进程的PID。如果fork()调用成功,返回的PID是一个正整数。在子进程中,fork()返回0。这是区分父进程和子进程的关键:任何时候调用fork(),如果返回值为0,那么当前执行代码的就是子进程。如果fork()调用失败,它会返回一个负值,表示创建子进程时出现了错误,如内存不足等。
如图所示,结果输出8个my_fork,。int f1=fork(),这是第一次调用fork(),它将创建一个新的子进程,子进程的PID将赋值给f1(在父进程中);子进程中的f1将为0。执行int f2=fork();在父进程中,f2将获得新创建的子进程的PID。在之前创建的子进程中,f2也将获得新创建的子进程的PID。执行int f3=fork();:
类似地,f3将在父进程和之前的子进程中获得新创建的子进程的PID。printf("my_fork\n");这行代码将在所有通过fork()创建的进程中执行,包括父进程和所有子进程。
由于fork()可以递归地调用,所以最终的进程数取决于fork()调用的次数。在这个程序中,fork()被调用了3次,所以最多可以创建 23=8个进程(包括初始的父进程)。每个进程都将执行printf,所以在在控制台上看到“my_fork”被打印8次。
修改程序,在主程序中多增加1个fork()调用,即在主程序中执行4个fork()调用,最后的输出结果有何变化?试分析原因。
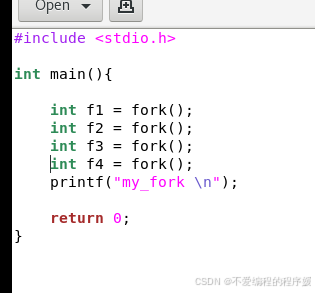
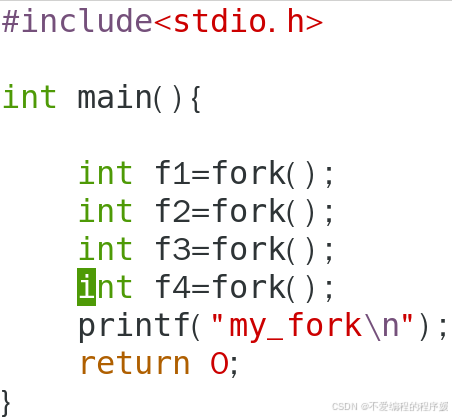
修改后的程序如下:
执行结果如下:
如图所示,输出了16个my_fork,int f4=fork();:它将再次创建一个新的子进程,并且f4将在父进程和之前的子进程中获得新创建的子进程的PID。fork()被调用了3次,所以最多可以创建 24=16个进程,每个进程都将执行printf,所以在控制台上看到“my_fork”被打印16次。
3.进程的创建
编写一个c程序,在主程序中使用系统调用fork()创建两个子进程。当此程序运行时,在系统中有1个父进程和2个子进程并发执行。让每个进程在屏幕上显示一串字符:父进程显示字符“a”,即putchar(‘a’),子进程分别显示字符“b”和“c”。请运行若干次(如10-20次),请观察记录每次屏幕上的显示结果,并分析原因。

该程序的逻辑是:
- 父进程尝试执行 fork() 来创建第一个子进程。
- 如果 fork() 成功,父进程得到子进程的 PID,而子进程得到 0。
- 第一个 if(p1==0) 判断是子进程1,打印 'b'。
- 父进程接着尝试执行 fork() 来创建第二个子进程。
- 如果 fork() 成功,父进程和第一个子进程都得到第二个子进程的 PID,而第二个子进程得到 0。
- 第二个 if(p2==0) 判断是子进程2,打印 'c'。
- else 判断是父进程,打印 'a'。
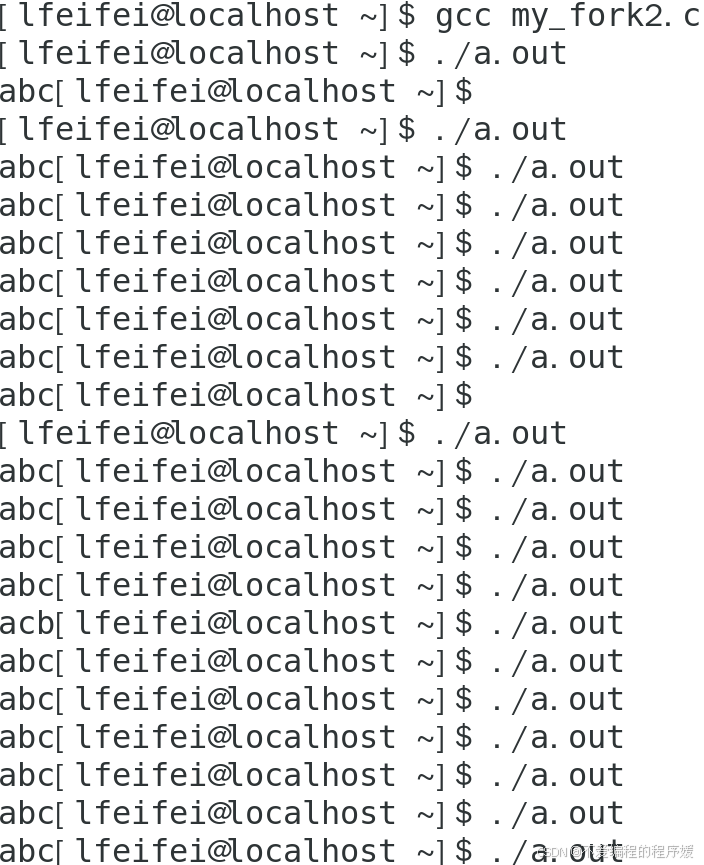
如图所示,程序执行多次,结果有abc、acb,这两种结果都符合程序逻辑,尽管子进程是按照创建顺序启动的,但它们的执行顺序是由操作系统的调度器决定的,可能是并发的。第一个子进程p1和第二个子进程p2的执行顺序是不确定的,所以这两种执行结果都是父进程和子进程执行putchar的可能顺序。
4.进程的控制
修改实验内容“5.5.3进程的创建”中的程序,将每个进程的输出由单个字符改为连续打印10次字符串并换行,每次打印完休眠1s或1ms。如:子进程1连续printf(“child-p1\n”),每次打印完休眠1s或1ms;子进程2连续printf(“child-p2\n”),每次打印完休眠1s或1ms;父进程连续printf(“father\n”),每次打印完休眠1s或1ms;观察程序执行时屏幕上出现的现象,并分析其原因。
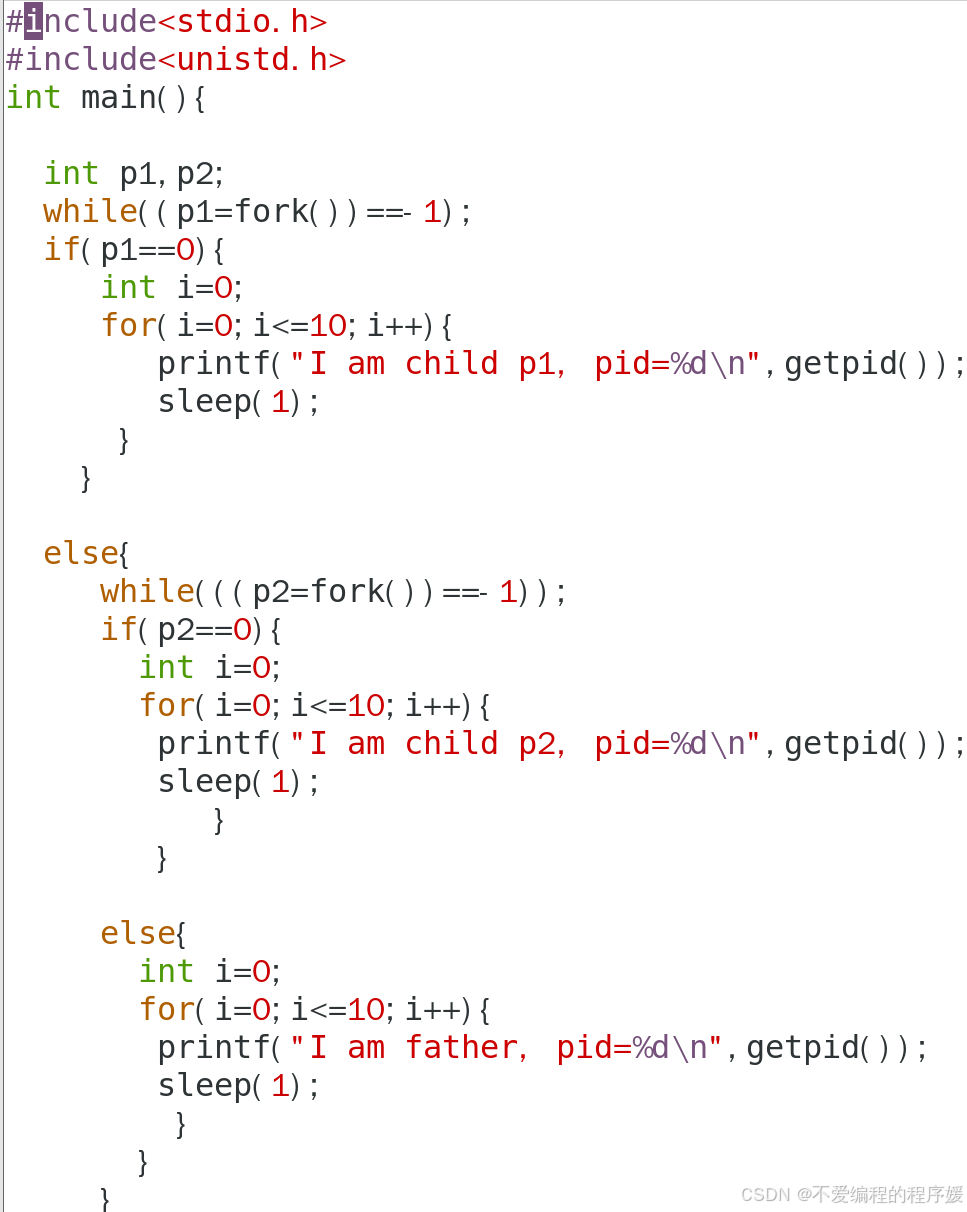
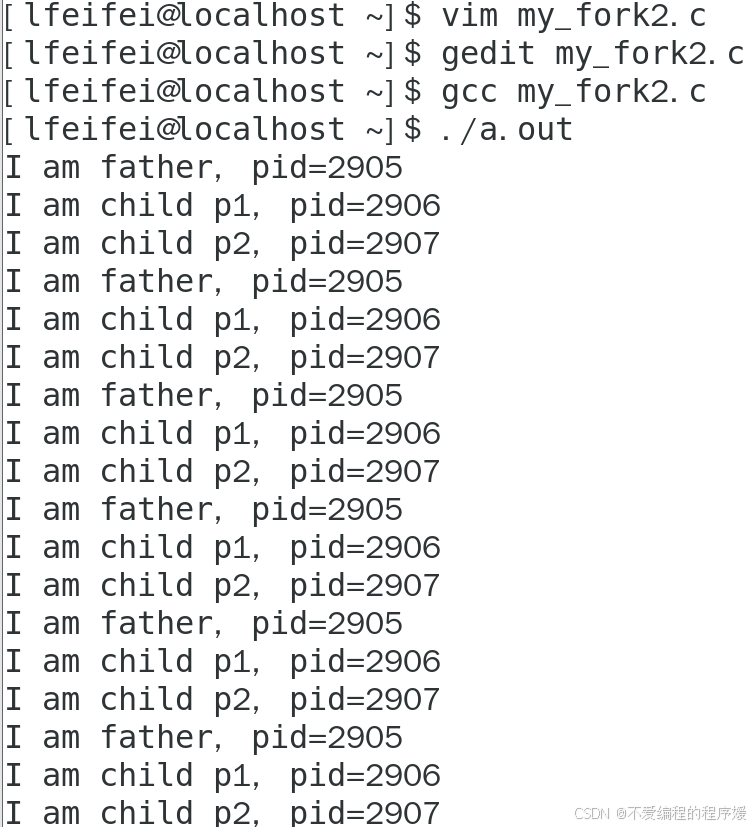
如图所示,上面是代码的部分运行结果,在5.5.3的基础上加了for循环,连续打印10次字符换行并休眠1s,输出具有顺序性,每个进程都打印了11次,每次的结果都是先输出父进程,再输出子进程p1,子进程p2,其PID顺序也是连续的。虽然进程的调度具有不确定性,但通过休眠1s,使该程序的进程的减少了输出竞争,减少了交错输出的可能性,故与没有休眠之前的程序相比,该程序的进程输出顺序一致的可能性加大。
继续修改程序,在程序中使用系统调用lockf()给每个进程加锁,以实现进程之间的互斥。执行程序,观察并分析出现的现象。
【注:lockf()调用方法】
#include <unistd.h> //头文件
int lockf(int fd, int cmd, int len) //函数原型
lockf函数对指定区域的资源进行加锁或解锁,以实现进程的同步或互斥。
① fd 是打开文件的文件描述符。
② cmd 是指定要采取的操作的控制值。1是进行锁定,0是解锁。
③ len是要锁定或解锁的连续字节数。
对于这个函数我们主要掌握两个常用命令
1)当len = 0时是个特殊情况,它代表锁定区域从该函数到程序结尾。lockf(1,1,0)意思是该进程的编号为1,并对进程的资源进行锁定,锁定区域从该函数到程序结尾。
2)lockf(1,0,0)意思是对编号为1的进程进行解锁,释放资源。
示例程序如下:

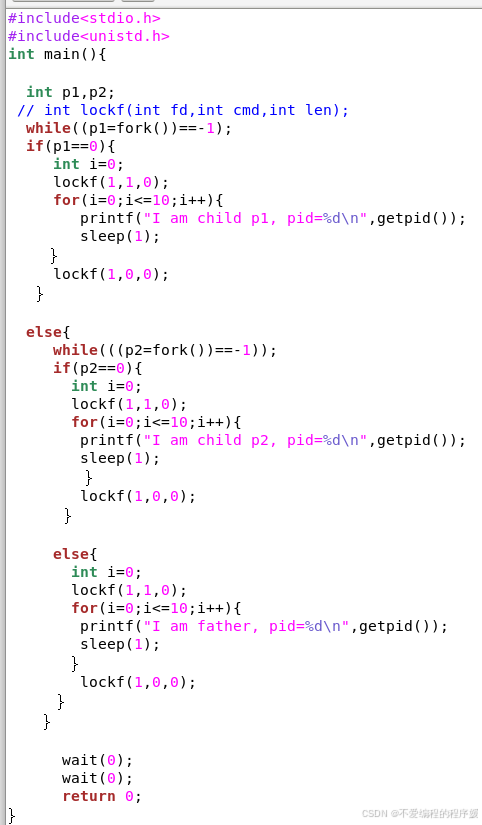
如图所示,在上一个程序的基础上,给每个进程都进行上锁与解锁
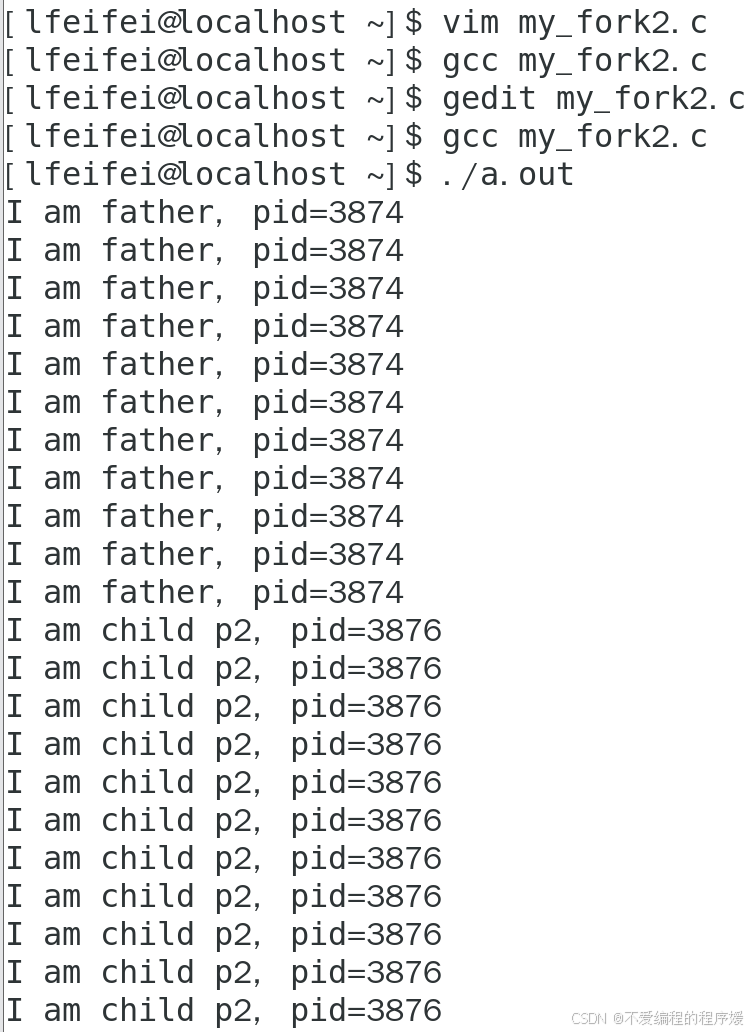
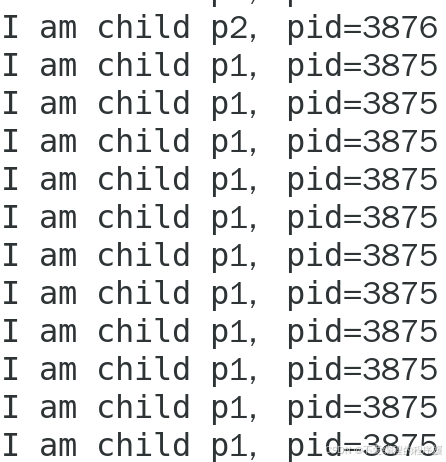
结果如图所示,先是父进程连续打印11次,接着是子进程p2,p1。表明每个进程都成功获得了锁,在没有其他进程的干扰下,实现连续消息的连续打印,表明各个进程之间互斥成功。
5.实验总结
通过本次实验,我学到了如何在Linux操作系统中实际的利用fork()创建子进程,以及进程不同返回值的含义。还有进程的同步,利用sleep()函数使得进程的执行顺序更加明显,wait()系统调用确保了父进程能够等待子进程结束,实现进程的互斥则是使用lockf()函数给进程上锁,控制对共享资源的访问,可以确保每个进程在执行结束之前,不会被其他进程干扰。


















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











