






结论:改多线程为多进程避开io锁
起初,我由于受不了我写的一个转码工具
Python-转mht为html-用email库转Android端QQ浏览器保存下的mht文件-优快云博客
转码一个文件调用几十次读写操作,导致的速度低下问题,具体体现在任务管理器中磁盘活动时间一直处在地位,一个文件可能要几十秒
由于py的GIL锁限制,我便想到了将写入文件的函数专门折腾出来扔到线程里面,让它慢慢去排队
def write_down_file_content_threaded(file_path, file_content):
thread = threading.Thread(target=Tool.write_down_file_content, args=(file_path, file_content))
thread.start()
return thread换成线程写入之后代码刚刚运行的那一下活动时间上去了,但是没两下又掉了下去,不温不火,过一段时间后甚至还会出现掉到0的情况。
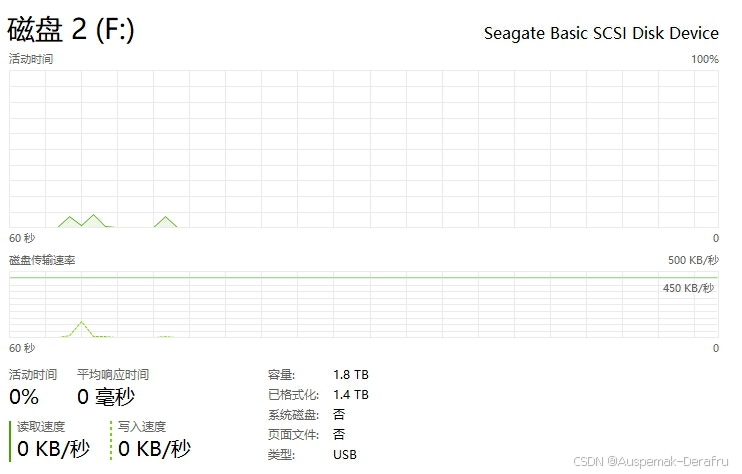
我一想会不会是我运行转码的代码也要加线程,便又套上了一个:
def main(directory):
print("current:"+directory)
enable_double_transformat=False
#最大线程数
max_workers = 20
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交任务到线程池
futures = []
# 遍历目录下的所有HTML文件
for filename in os.listdir(directory):
file_path = os.path.join(directory, filename)
# 提交每个文件的处理任务到线程池
futures.append(executor.submit(process_file, file_path, directory))
# 等待所有任务完成
for future in futures:
future.result() # 这里会阻塞,直到对应的任务完成这样一搞,发现问题更大了,本来运行好好的代码时不时还出现已挂起,这说明我的代码完全阻塞了啊
回顾完代码之后发现了问题:
由于转码代码在转码之前要读取原文件,转码后要写入新文件,所以io操作不仅仅在内部的写入代码会进行,在main函数上也涉及到了io操作,而当main函数的io和等待内部的io杂到一块时,代码自然出现了阻塞:main函数的操作被大量的内部其他的文件写入给堵死了
找到问题之后,就好解决了,只要将外部的操作扔到进程池而不是线程池。让内部的io操作在一个进程中折腾,而通过进程池搞出若干个进程,速度问题就解决了
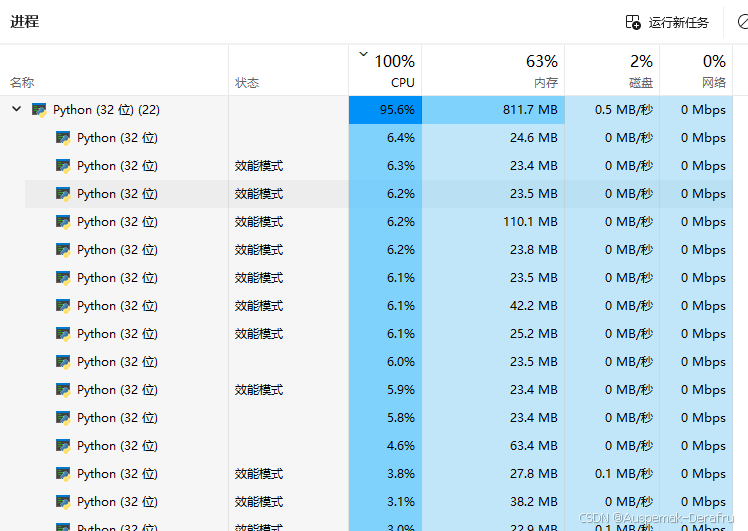
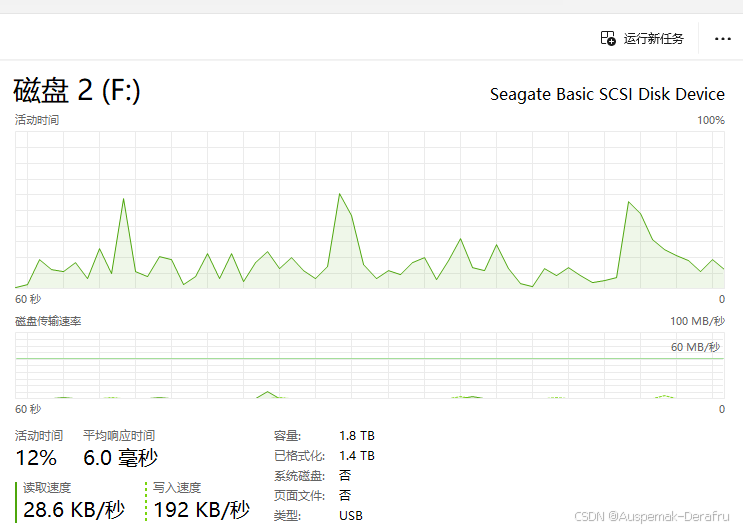
改完之后很明显地看到cpu几乎被py干爆了,而磁盘活动时间虽然由于大量读取的关系出现了严重的速度波动,但是写入速度以及运行处于一个较为稳定的工作状态。
问题解决
ps:进程要放在
if __name__ == '__main__':代码下


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









