







只是记录下自己在做练习,使用SQL语言的时候的心路历程和一些遇到的问题,供大家一起参考学习。

1.创建模式
要在PostgreSQL中创建一个名为"scs"的模式(schema),可以使用以下SQL命令:
CREATE SCHEMA scs;
您可以在PostgreSQL命令行中执行此命令。如果您已经连接到了PostgreSQL,只需输入上面的命令并按回车即可。
如果您希望指定该模式的拥有者,可以使用:
CREATE SCHEMA scs AUTHORIZATION username;
其中username是您想要指定的用户名。
创建完成后,可以使用\dn命令来查看所有的模式:
\dn
这会列出数据库中的所有模式,包括刚刚创建的"scs"模式。
创建模式(Schema)在PostgreSQL中有几个重要的用途:
- 逻辑分组:模式允许您将数据库对象(如表、视图、函数等)组织成逻辑分组,便于管理大型数据库。
- 命名空间:不同模式中可以有同名的表,避免命名冲突。
- 权限管理:可以在模式级别设置权限,简化安全管理。
- 项目隔离:在同一数据库中为不同项目或应用程序创建单独的模式,提供隔离。
- 第三方应用:许多应用程序使用自己的模式来避免与其他对象冲突。
关于\dn命令:
\dn是PostgreSQL命令行工具(psql)中的一个元命令,其中:
\表示这是一个psql元命令,而不是SQL语句d代表"describe"(描述)n代表"namespace"(命名空间,即模式)
所以\dn的全称可以理解为"describe namespaces",用于列出所有可用的模式。
其他类似的元命令还有:
\dt- 列出表(tables)\dv- 列出视图(views)\df- 列出函数(functions)\du- 列出用户(users)
如果之前没有明确需要创建模式,可以直接使用默认的public模式,所有用户都可以访问。
2.创建表/关系
2.1 Student Table
现在您已经成功创建了名为"S-C-S"的模式,要在这个模式中创建表,您需要明确指定模式名。正确的语法应该是:
CREATE TABLE "S-C-S".Student (
Sno CHAR(9),
Sname VARCHAR(20),
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
注意以下几点:
- 模式名称"S-C-S"需要用双引号括起来,因为它包含连字符
- 用点(.)连接模式名和表名
- 每条SQL语句结束后需要加分号(😉
或者,您可以先设置搜索路径,使"S-C-S"成为默认模式:
SET search_path TO "S-C-S", public;
然后就可以不指定模式名直接创建表:
CREATE TABLE Student (
Sno CHAR(9),
Sname VARCHAR(20),
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
使用哪种方式取决于您的偏好和需求。如果这是一次性操作,直接指定模式可能更简单;如果您将在这个模式中创建多个对象,设置搜索路径会更方便。
您已经成功在"S-C-S"模式中创建了Student表,但是当您使用\dt命令时没有显示任何表,这是因为\dt默认只显示当前搜索路径中的表。
要查看特定模式中的表,您需要使用带有模式参数的\dt命令:
\dt "S-C-S".*
或者查看所有模式中的表:
\dt *.*
请注意,PostgreSQL命令是区分大小写的,\dt是正确的命令(小写dt),而您之前尝试的\DT(大写DT)是无效的。
您也可以设置搜索路径,这样默认的\dt命令就会包含"S-C-S"模式的表:
SET search_path TO "S-C-S", public;
\dt
这样就能看到您刚刚创建的Student表了。
1.2 Course Table
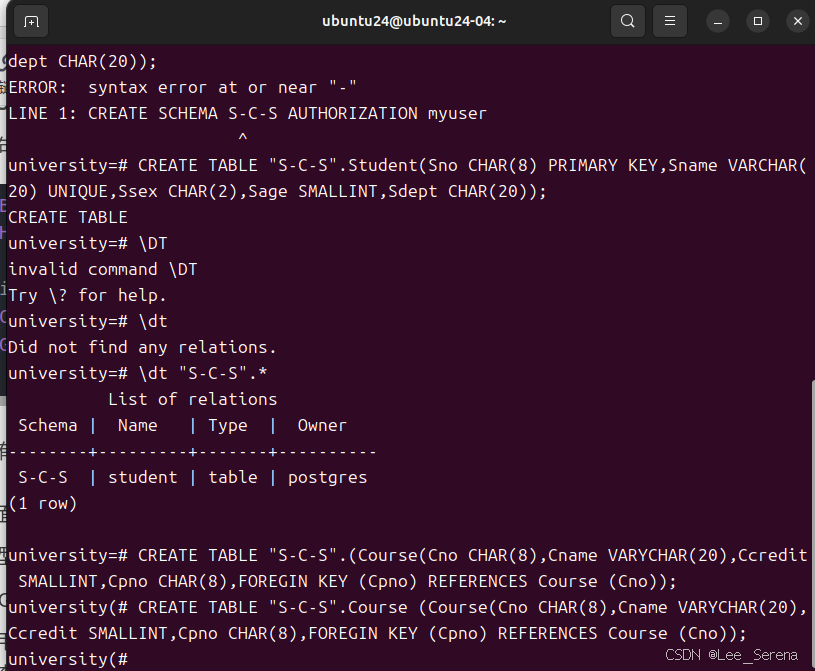
您的SQL语句中有几个语法错误。以下是修正后的语句:
CREATE TABLE "S-C-S".Course (
Cno CHAR(8) PRIMARY KEY,
Cname VARCHAR(20), -- 注意是VARCHAR不是VARYCHAR
Ccredit SMALLINT,
Cpno CHAR(8),
FOREIGN KEY (Cpno) REFERENCES "S-C-S".Course(Cno) -- 注意是FOREIGN不是FOREGIN
);
主要的错误有:
- 表名后面的括号中出现了"Course(",这是语法错误
- 数据类型"VARYCHAR"拼写错误,正确的是"VARCHAR"
- “FOREGIN KEY"拼写错误,正确的是"FOREIGN KEY”
- 外键引用需要包含模式名"S-C-S",否则PostgreSQL会在默认模式中查找Course表
另外,请注意这个表有一个自引用的外键约束,即Cpno引用同一个表的Cno字段,通常用于表示课程的先修课程关系。这是合法的设计,但请确保这是您的意图。
再改
CREATE TABLE "S-C-S".Course(Cno CHAR(8),Cname VARCHAR(20),
Ccredit SMALLINT,Cpno CHAR(8),FOREIGN KEY(Cpno)
REFERENCES Course(Cno));
错误:在创建Course表时,您的语句有一个问题:外键引用的表没有指定模式。因为Course表是在"S-C-S"模式中,所以外键引用也应该指向同一模式中的表。
正确的SQL语句应该是:
CREATE TABLE "S-C-S".Course(
Cno CHAR(8) PRIMARY KEY, -- 添加主键约束
Cname VARCHAR(20),
Ccredit SMALLINT,
Cpno CHAR(8),
FOREIGN KEY(Cpno) REFERENCES "S-C-S".Course(Cno)
);
注意两个修改:
- 添加了
PRIMARY KEY约束到Cno列(被引用的列必须是主键或唯一键)- 在
REFERENCES子句中添加了模式名"S-C-S"
如果不指定模式名,PostgreSQL会在搜索路径中查找Course表,如果找不到则会出错。

成功创建了。
1.3 SC选课表的创建
CREATE TABLE “S-C-S”.SC(Sno CHAR(80
写到这忽然想起来自己的student表格貌似没指定主键,在这里就引用不了外码,被引用的外键一定是那一个表的主码。
因此现在就打算修改一下原来的Student表格的属性
Sno,就跳到后面去学习了一下修改语句。

例3.10就是我所需要的,我要修改约束条件,增加一个PRIMARY KEY。

但是提醒我已经指定过主键了,我寻思着我之前没指定啊,接着我想查询一下之前到底是否指定过主键,用到另一个命令\d “S-C-S”.Student。(此处还是要注意定位到相应的模式下)
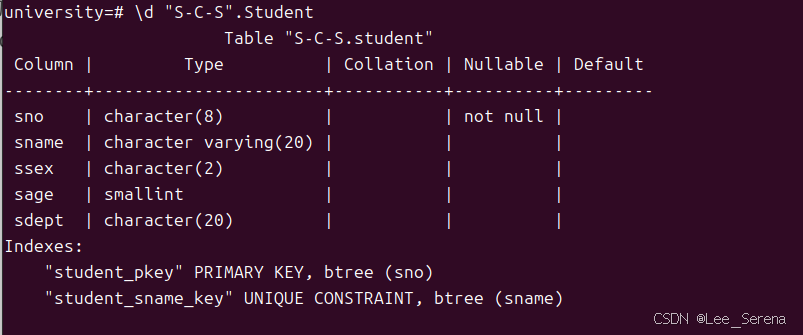
这里显示,我的确已经指定了主键。在这里我发现我对各种命令还不够熟悉,因此让Claude整理了一份,供大家参考。
以下是PostgreSQL命令行(psql)中常用的元命令及其含义:
-
\d [模式名.]表名 - describe (描述表结构)
\d "S-C-S".Student显示指定表的详细结构,包括列、数据类型和约束
-
\dt [模式名.]* - describe tables (描述所有表)
\dt "S-C-S".*列出指定模式中的所有表
-
\dn - describe namespaces (描述命名空间/模式)
\dn列出所有模式
-
\du - describe users (描述用户)
\du列出所有数据库用户和角色
-
\l - list (列出数据库)
\l列出所有数据库
-
\c 数据库名 - connect (连接到数据库)
\c university切换到指定的数据库
-
\s - show history (显示历史)
\s显示命令历史记录
-
\i 文件名 - include/input (包含/输入文件)
\i script.sql执行指定SQL脚本文件中的命令
-
? - help (帮助)
\?显示所有psql命令的帮助信息
-
\h [SQL命令] - help SQL (SQL帮助)
\h CREATE TABLE显示特定SQL命令的语法帮助
-
\q - quit (退出)
\q退出psql程序
-
\df - describe functions (描述函数)
\df列出所有函数
-
\dv - describe views (描述视图)
\dv列出所有视图
-
\x - expanded display (扩展显示)
\x切换扩展显示模式,使结果垂直显示而非表格形式
-
\timing - timing (计时)
\timing切换SQL执行时间显示
这些命令在PostgreSQL命令行中很有用,可以帮助您浏览和管理数据库。

好的,现在回到主线任务,继续创建我们的SC表格。
这个错误很奇怪,因为您的SQL语法看起来是正确的。问题可能出在PostgreSQL解析含有特殊字符的模式名时。让我们尝试一个替代方案:
- 使用转义字符或不同的引号风格:
CREATE TABLE "S-C-S".SC (
Sno CHAR(8),
Cno CHAR(8),
Grade SMALLINT,
PRIMARY KEY(Sno,Cno),
FOREIGN KEY(Sno) REFERENCES "S-C-S".Student(Sno),
FOREIGN KEY(Cno) REFERENCES "S-C-S".Course(Cno)
);
如果这个方案仍然无效,可以尝试以下其他解决方法:
- 先设置搜索路径,然后不使用模式名创建表:
SET search_path TO "S-C-S", public;
CREATE TABLE SC (
Sno CHAR(8),
Cno CHAR(8),
Grade SMALLINT,
PRIMARY KEY(Sno,Cno),
FOREIGN KEY(Sno) REFERENCES Student(Sno),
FOREIGN KEY(Cno) REFERENCES Course(Cno)
);
- 创建一个不带连字符的模式,然后使用该模式:
CREATE SCHEMA scs;
CREATE TABLE scs.SC (
Sno CHAR(8),
Cno CHAR(8),
Grade SMALLINT,
PRIMARY KEY(Sno,Cno),
FOREIGN KEY(Sno) REFERENCES "S-C-S".Student(Sno),
FOREIGN KEY(Cno) REFERENCES "S-C-S".Course(Cno)
);
错误消息中指出问题出在"-"字符附近,这表明PostgreSQL可能在处理带连字符的模式名时遇到了问题。
此时三个表就已经全定义好了。
2. 在Student表中增添一个字段address

测试一下
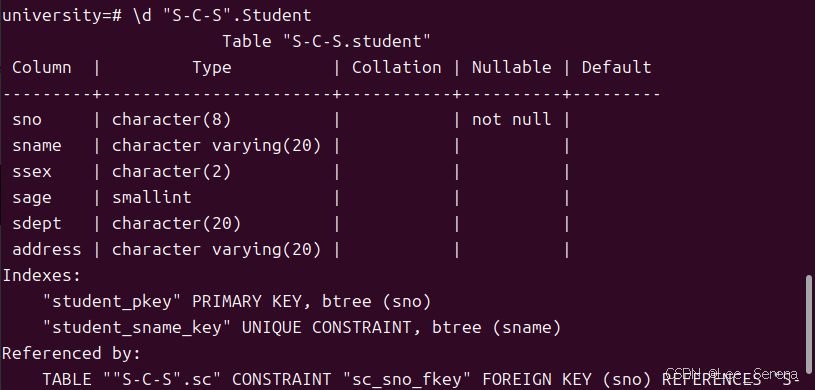
已经修改成功了。
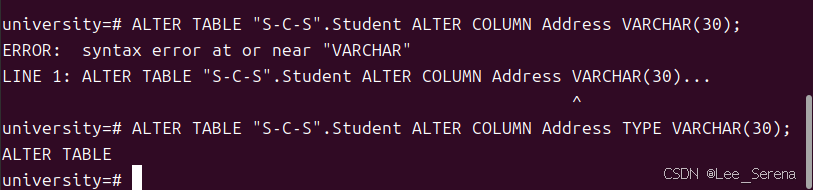
3.修改字段长度


我的理所当然:ALTER TABLE "S-C-S".Student ALTER COLUMN Address VARCHAR(20) TO VARCHAR(30);

但是貌似这个也不对,需要加TYPE
4. 删除字段
ALTER TABLE "S-C-S".Student DROP COLUMN Address;
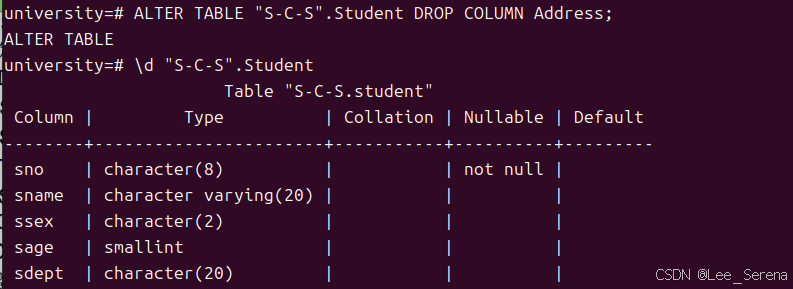
可以看到已经成功删去
4. 创建索引
先简单介绍一下索引
假设我们有一个"员工"表(Employees),包含以下字段:
- id(员工编号)
- name(姓名)
- department(部门)
- salary(薪资)
这个表中有10万名员工的记录。
没有索引的查询
假设我们想查找名为"张伟"的员工:
SELECT * FROM Employees WHERE name = '张伟';
没有索引的情况下,数据库会执行"全表扫描",即:
- 检查第1行的name是否为"张伟"
- 检查第2行的name是否为"张伟"
- …以此类推,直到检查完所有10万行
这可能需要相当长的时间,特别是表很大的情况下。
有索引的查询
现在,我们在name列上创建一个索引:
CREATE INDEX idx_employee_name ON Employees(name);
创建索引后,数据库会建立一个类似于电话簿的结构(通常是B树或B+树),其中按字母顺序排列了所有员工的姓名,并记录了每个姓名对应的行位置。
再次执行同样的查询:
SELECT * FROM Employees WHERE name = '张伟';
这次数据库会:
- 通过索引直接找到所有name为"张伟"的记录位置
- 只读取这些特定的行
如果表中有5个叫"张伟"的员工,数据库只需要读取5行数据,而不是全部10万行,查询速度可能提高几百甚至几千倍。
索引的实际效果
在实际数据库系统中,可以通过"执行计划"查看索引的效果:
没有索引时的执行计划可能显示:
Table: Employees
Type: ALL (全表扫描)
Rows examined: 100,000
有索引时的执行计划可能显示:
Table: Employees
Type: ref (索引查找)
Possible keys: idx_employee_name
Key: idx_employee_name
Rows examined: 5
通过这个例子,你可以看到索引如何显著减少数据库需要检查的行数,从而提高查询性能。
4.1 创建唯一索引
CREATE UNIQUE INDEX UISNAME ON “S-C-S”.Student(Sno);
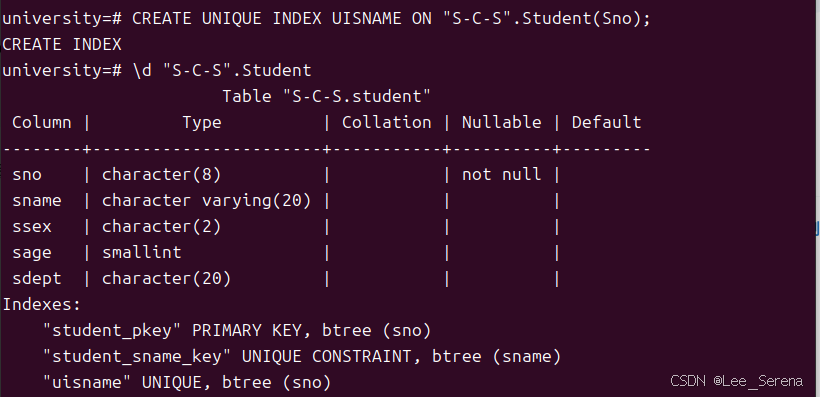
可以看到创建了一个B树的索引
4.2 删除唯一索引,创建cluster索引

DROP INDEX "S-C-S".UISNAME;
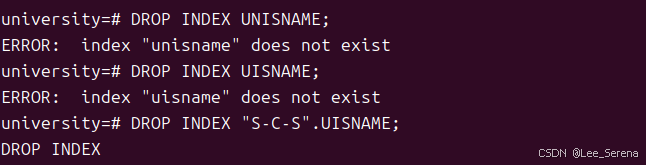
同样要加模式。
接下来创建聚类索引:

遇到的错误是因为PostgreSQL中创建聚集索引的语法与你使用的不同。在PostgreSQL中,创建聚集索引的正确语法是先创建一个普通索引,然后使用CLUSTER命令来指定该索引作为聚集索引。
正确的做法应该是这样:
- 先创建一个普通索引(如果还没有合适的索引):
CREATE INDEX CISNAME ON "S-C-S".Student(Sno); -- 假设你想按Sno列聚集
- 然后使用CLUSTER命令指定该索引作为表的聚集索引:
CLUSTER "S-C-S".Student USING CISNAME;
或者,如果你已经有了想要用作聚集索引的现有索引(比如"uisname"),可以直接:
CLUSTER "S-C-S".Student USING uisname;
与其他一些数据库系统(如SQL Server)不同,PostgreSQL没有直接的"CREATE CLUSTER INDEX"语法,而是采用上述两步方法来实现聚集索引的功能。
执行CLUSTER命令后,表数据会被物理重排以匹配索引顺序,但请注意,这是一次性操作,PostgreSQL不会自动维护这种物理排序。如果需要保持聚集状态,你需要定期重新执行CLUSTER命令。
5.SC TABLE 创建一个唯一索引
CREATE UNIQUE INDEX SCNO ON "S-C-S".Sc(Sno,Cno);
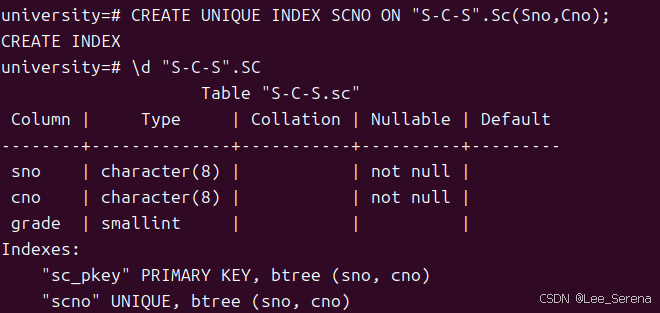
可以看到已经成功创建
6. 删除表

我们可以分别试试
6.1 RESTRICT
DROP TABLE "S-C-S".Student RESTRICT;

存在依赖关系,也就是别的表引用的这个表的主码,因此不能删除。
6.2 CASCADE
DROP TABLE "S-C-S".Student CASCADE;
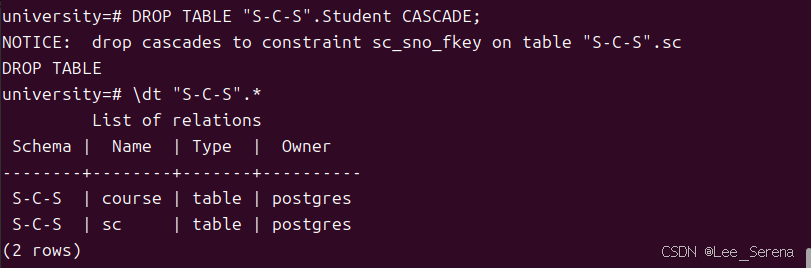
用命令dt,输出结果可以看到学生表成功被删除。

















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









