







文章目录
一. 文件IO的介绍
IO
Input 输入
Output 输出
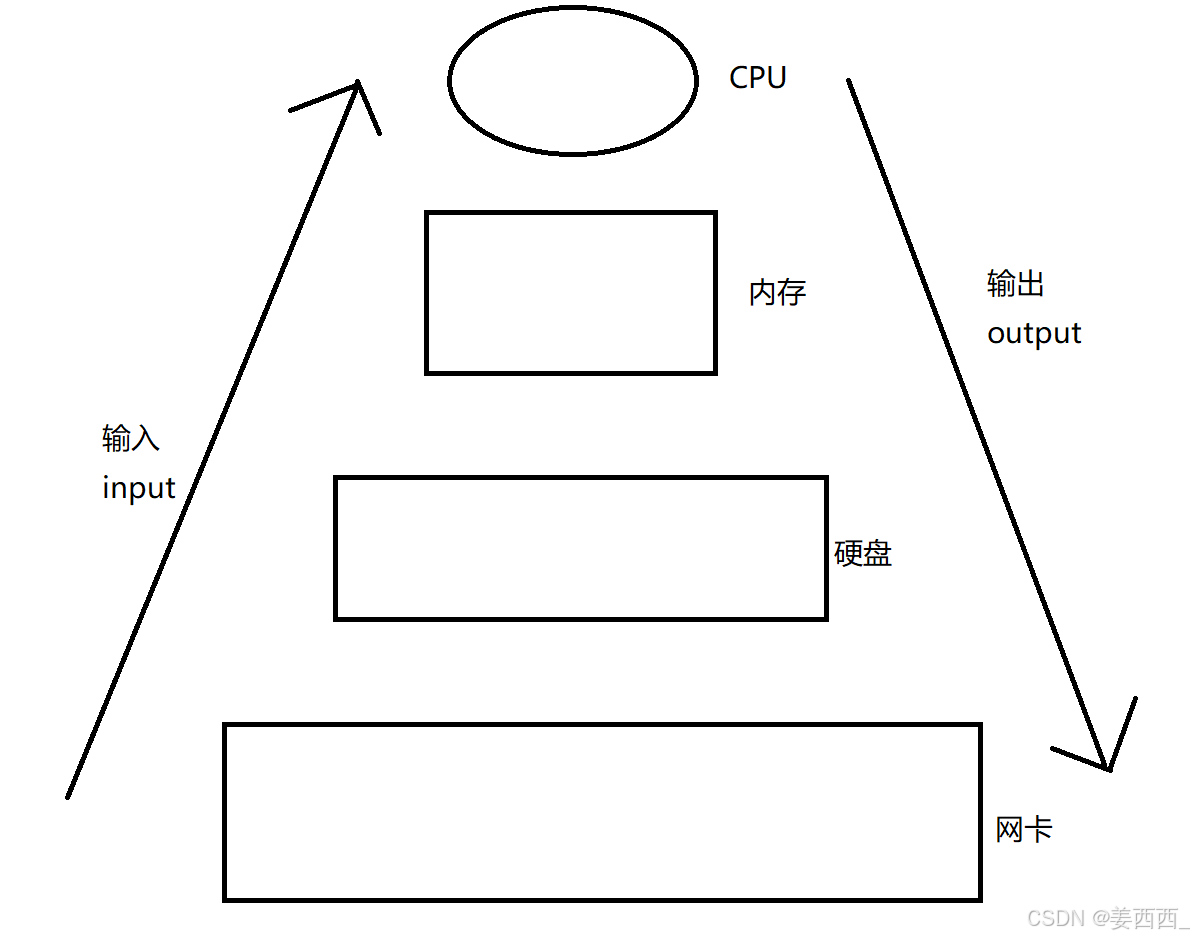
输入输出并不是相对的, 以CPU为基准
比如, 电脑可以通过网络下载文件, 也可以通过网络上传文件
那么, 通过网络下载文件, 相当于从网卡到硬盘, 是input
通过网络上传文件, 相当于从硬盘到网卡, 是output
通过控制台, 读取数据到内存, 也是输入
把数据打印显示到控制台上, 也是输出
文件
其实在操作系统中, 把很多资源(软件资源 / 硬件资源)都抽象成文件
但是我们这里说的文件, 就是平时保存在硬盘上的这些文件
文件夹也是一种文件, 称为"目录文件", 也是保存在硬盘上
在硬盘上, 存在很多文件和目录, 目录又存在一定的嵌套关系, 整体是一个N叉树的树形结构
路径
从本节点出发, 一层一层往下走, 最终到达目标文件后, 中间这些目录, 集合在一起就构成了"目录"
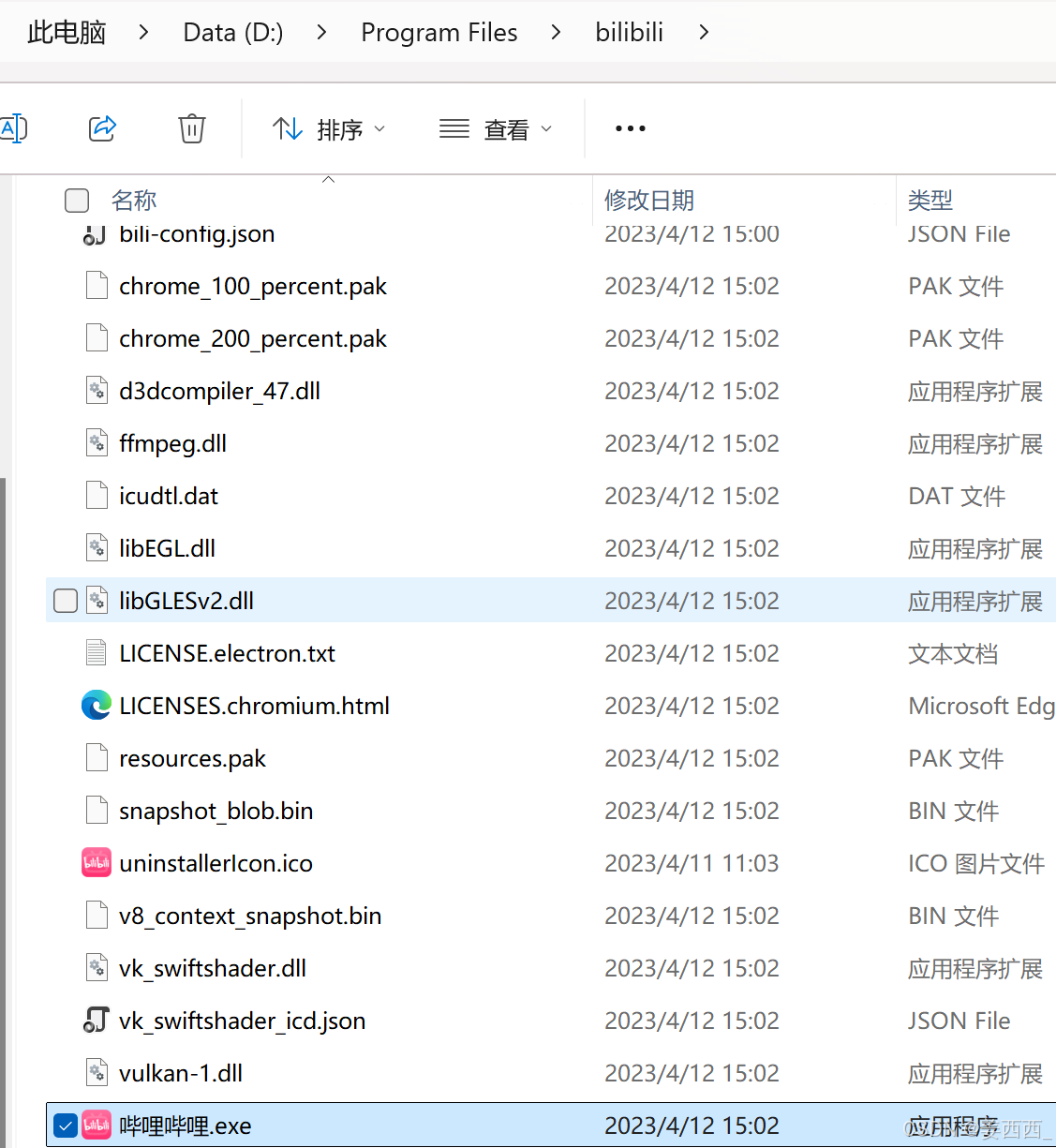
例如: 此时我的哔哩哔哩的路径就是:
“D:\Program Files\bilibili\哔哩哔哩.exe”
像这样, 以盘符开头的路径, 也称为"绝对路径"
操作系统中, 也支持"相对路径", 起点(工作目录)可以是任意路径
目录和目录之间, 使用 \ 或 / 进行分割
注意: 只有在Windows系统中, 使用 / 或 \ 都可以, 其他系统只能使用 / (日常开发推荐使用 / )
举例:
如果我们要找哔哩哔哩.exe文件
- 如果当前的基准(工作目录)为D:\Program Files\bilibili
通过 ./哔哩哔哩.exe , 即可找到文件
相对路径中, **. **表示"当前所在的文件" - 如果当前的基准(工作目录)为D:\Program Files
通过 ./bilibili/哔哩哔哩.exe - 如果当前的基准(工作目录)为D:\Program Files\qq
通过 …/哔哩哔哩.exe , 即可找到文件
相对路径中, **… **表示"返回上一级目录文件"
文件的分类
与编写代码相关的分类方式
分成 文本文件 和 二进制文件
主要在于, 硬盘上存的数据, 是文本数据, 还是二进制数据
文本数据, 根据GBK, UTF8等码表, 可以将文本数据中的二进制数, 翻译成合法的字符, 实际存放的是字符串
二进制数据, 存什么都可以
区分方法:
一个简单粗暴的方式, 就是将一个文件使用记事本打开
如果不是乱码, 就是文本文件, 如果是乱码, 就是二进制文件
例如:

这个文件, 我们用记事本打开后,

很明显是文本文件

这个文件, 用记事本打开后:

乱码, 所以是二进制文件
日常见到的, docx, pptx, mp3, mp4, pdf…都属于二进制文件
md, html, java, cpp 都是文本文件
二. 使用java操作文件
操作分为两种:
1,针对 文件系统 进行操作
例如 创建文件, 删除文件, 创建目录, 重命名文件…
2.针对 文件内容进行操作
例如 读文件, 写文件
针对文件系统进行操作
Java标准库中, 提供了一个File类表示一个文件, 进一步通过File提供的方法, 就可以进行文件操作了
File类, 出自java.io包中
属性:

pathSeparator其实就是java为了能够跨平台, 专门提供的变量
如果是windows系统版本的jdk, 上述变量就是
如果是linux / mac 版本的, 就是 /
构造方法:

我们常用的就是中间的构造方法, 传入字符串类型的路径, 绝对路径和相对路径都可以
并且, 构造File对象时, 写的路径, 不一定非要是真实存在的
方法:

如果我们写成相对路径, 那么他的基准目录是啥, 取决于我运行程序的方式, 如果在IDEA里面用小三角运行, 那么基准目录就是我的项目所在的目录

这里的目录就是我们的基准目录
1.
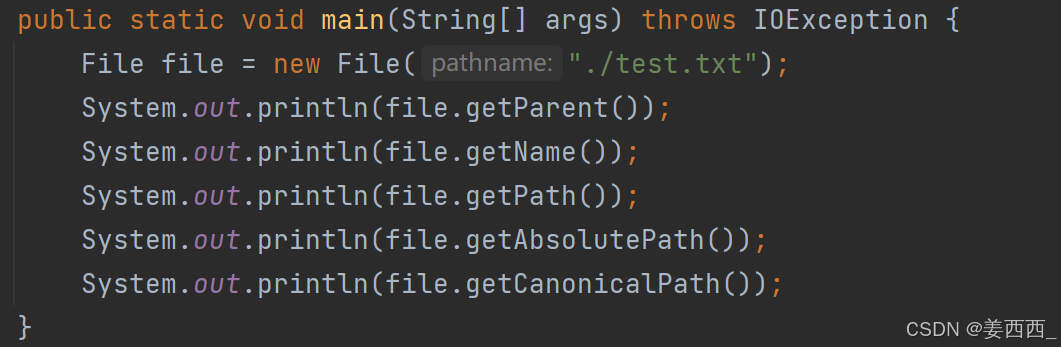
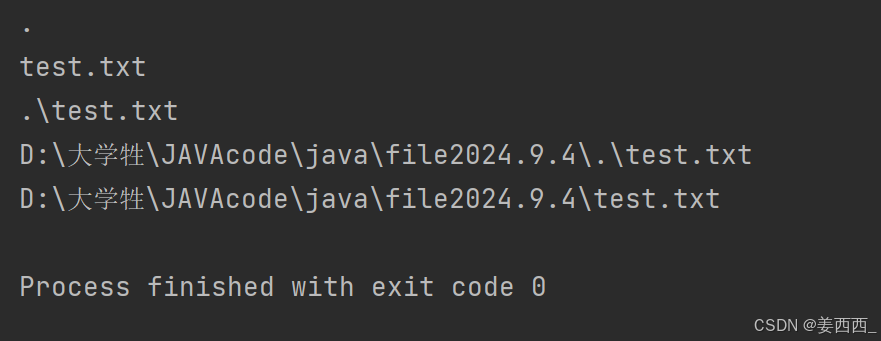
getAbsolutePath() 就是把基准目录和相对路径进行拼接
getCanonicalPath() 就是对上面的结果进行一些调整
2.
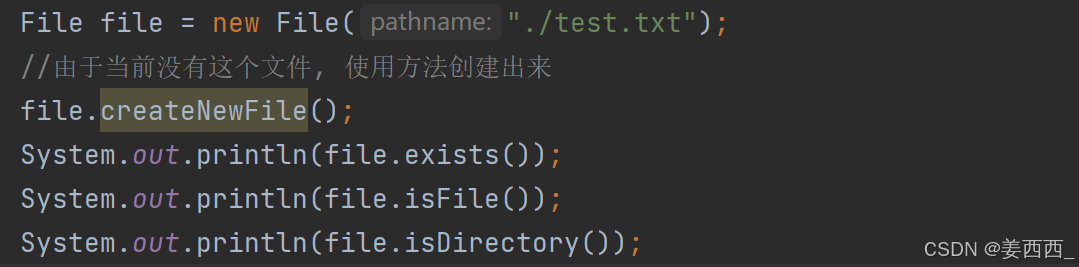
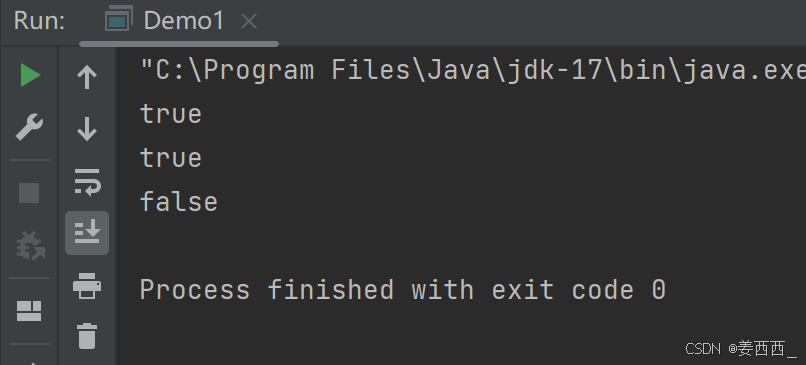
此时就会发现, 左侧出现了

3.
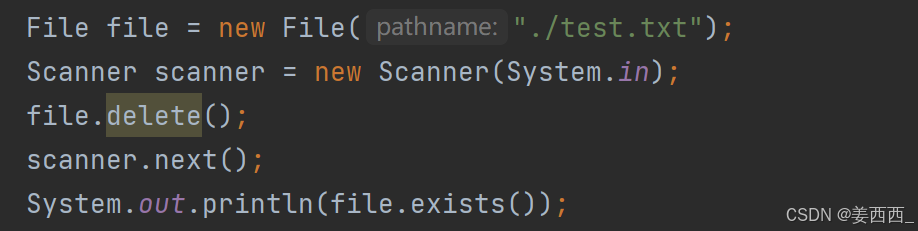
删除文件, 此时运行代码:
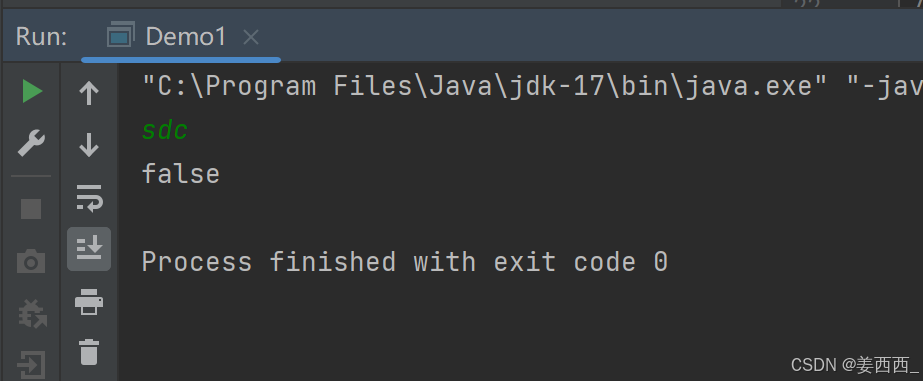
deleteOnExit()方法, 是删除有些程序, 自动产生的临时文件
例如:编辑word文档时, 就会自动创建出隐藏文件, 实时记录当前你编辑的内容, 以防出现未保存退出的情况, 可以通过这个隐藏文件找回

4.

mkdir() 创建一级目录
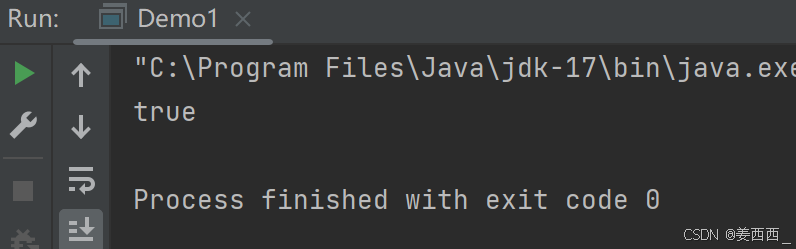


mkdirs() 创建多级目录
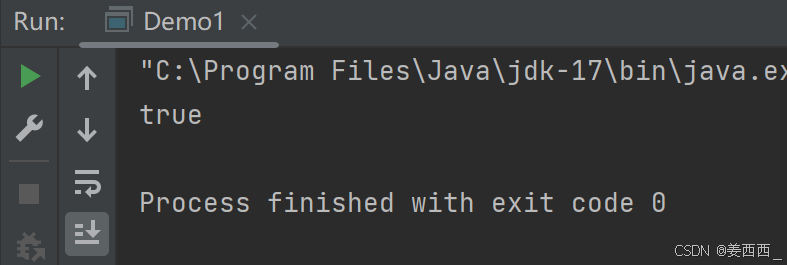

5.

renameTo() 将file1剪切粘贴到file2中(目录必须存在)
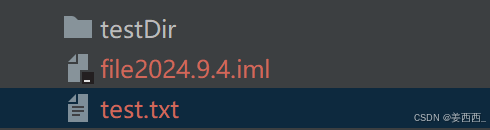
运行后:

针对文件内容进行操作
java通过"流"这样的一组类, 进行文件内容操作
这组类中, 分成两组:
-
字节流
以字节为单位, 读写数据的, 一般是针对二进制数据
InputStream, FileInputStream ---- 用来读数据
OutputStream, FileOutputStream ---- 用来写数据 -
字符流
以字符为单位, 读写数据的, 一般针对文本文件
Reader, FileReader ---- 用来读数据
Writer, FileWriter ---- 用来写数据
字节, 是一个固定的存储数据的单元, 代表8个二进制位
字符, 一个汉字, 一个字母, 一个标点, 都是字符, 它的大小是不固定的, 取决于不同的编码方式
java中, char类型, 使用的是unicode编码方式, 一个char就是一个字符, 代表两个字节
而String类型, 默认是utf8编码方式, 一个汉字默认3个字节
不论是字节流还是字符流, 核心操作都是一样的:
1)通过构造方法, 打开文件
2)通过read方法读文件内容/通过write方法写文件内容
3)通过close方法关闭文件
字节流
1. InputStream, FileInputStream
使用InputStream, 但是InputStream是个抽象类, 所以要搭配FileInputStream(继承了InputStrean)使用

构造方法:
1.填写file对象
2.填写字符串, 表示文件路径(相对 / 绝对 都可以)

read方法:

- 无参版本
一次读1个字节, 读到的内容通过int来接收
当到达末尾, 就返回-1
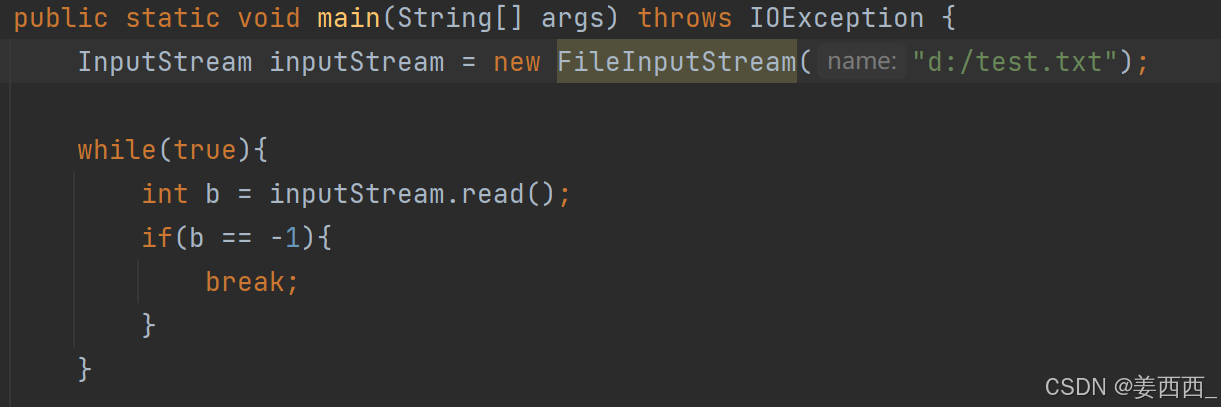
返回的是文档里面的内容对应的ascii值 - 带1个参数的版本

这里, 先准备好空的数组, 方法执行完毕后, 就会把读到的数据填写到byte数组中
用参数, 来作为函数的返回类型, 这种写法, 在java中不太常见, 属于一种非常典型的C++式写法
java中, 更常见的是, 用参数表述输入, 用返回值表示"输出"
这里的返回值n, 表示实际读到了多少个字节, 和上述的返回值类型不同
一次能读多少字节, 取决于这里数组的长度, 如果不够填满数组, 能填多少算多少
如果文件非常长, 超过1024, 需要搭配循环, 读若干次
问题:
上述两个方法, read(), read(bytes), 哪个效率更高?
答案是, 第二个
因为每次调用read, 都是要通过系统调用的api, 访问硬盘的, 带参数的一次能读的数据多, 访问硬盘的次数少, 效率更高
- 带3个参数的版本
只能填充数组的一部分, 从offset下标开始, 最多填充len这么长
close方法:
为什么要关闭文件:
我们打开文件, 会在操作系统内核PCB结构体中, 给"文件描述符表" 添加一个元素, 这个元素就是表示当前打开文件的相关信息
而文件描述符表, 就相当于是一个顺序表, 而里面的长度, 存在上限, 不能自动扩容!!!
一旦我们反复打开文件, 而不关闭, 就会使这个文件描述符表北站慢, 一旦占满, 再次尝试打开, 就会打开文件失败(其他的操作, 网络通信相关的操作, 也可能受到影响)
关闭文件, 就会释放掉这个文件描述符表上对应的元素
我们写程序的时候, 即使没写close方法, 也没什么影响, 因为进程结束, pcb就销毁了, 不存在文件描述符表的事了
那么, 我们写的close方法, 也有可能会发生, 前面出现异常或return的情况, 这样close就执行不到了
想到可以使用try-finally, 但是这种做法不太优雅

我们可以把创建对象(打开文件)操作放在try后面的括号里
此时代码执行出了try{}时, 就会自动调用inputStream的close方法了
这种方法称为" try with resources"
但是, 前提是这个类必须要实现Closeable接口!才能这么使用
输入流还可以搭配Scanner

2. OutputStream, FileOutputStream

构造方法:
1.填写file对象
2.填写字符串, 表示文件路径(相对 / 绝对 都可以)
3.字符串, append
append如果设置成true, 意思是使用追加写的方式进行写操作
如果像上面的构造方法, 什么都不写, 那么默认为false, 此时我们只要打开文件, 就会清空之前的数据
写方法:

版本一: 一次write写一个字节, 参数是int类型, 表示写入的是对应字符的ascii值
版本二: 一次write若干个字节, 会把参数数组中的所有字节都写入到文件中
版本三: 一次write写若干个字节, 把数组从offset下标开始, len长度写入文件
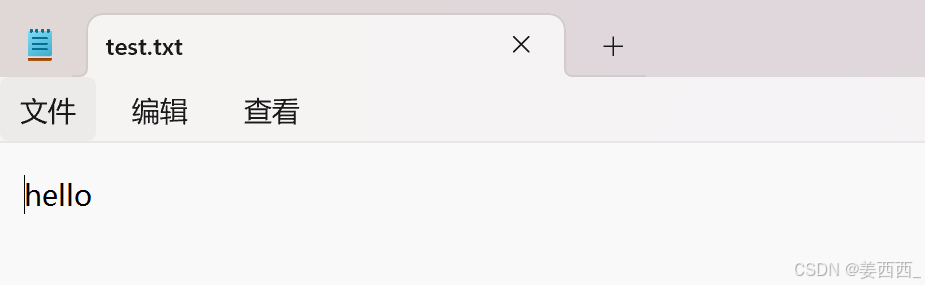
原本文件中有 hello, 运行下述代码
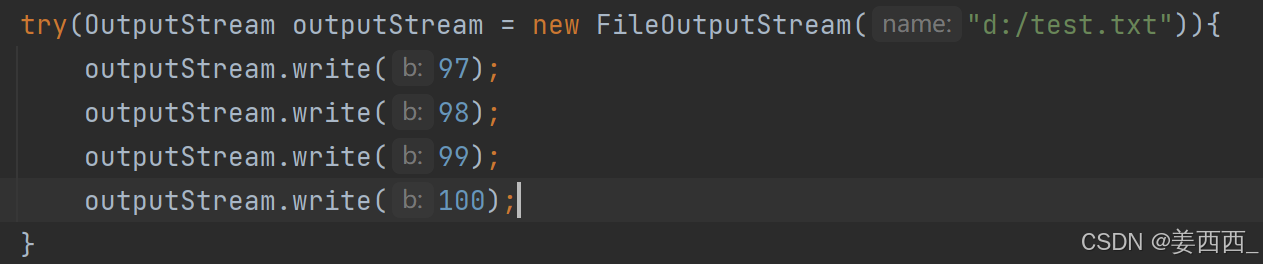
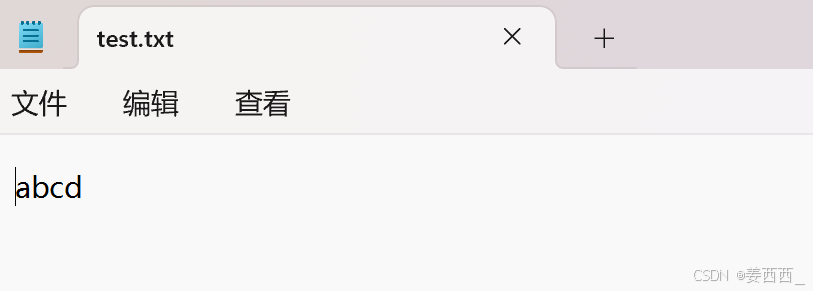
看到文件中, 变成了abcd, 把原来的覆盖掉了
此时如果我们把write操作注释掉, 只运行打开文件操作:
文件被清空了
如果我们加上第二个参数, 设置为true:

就变成了追加
字符流
1. Reader, FileReader

读方法:

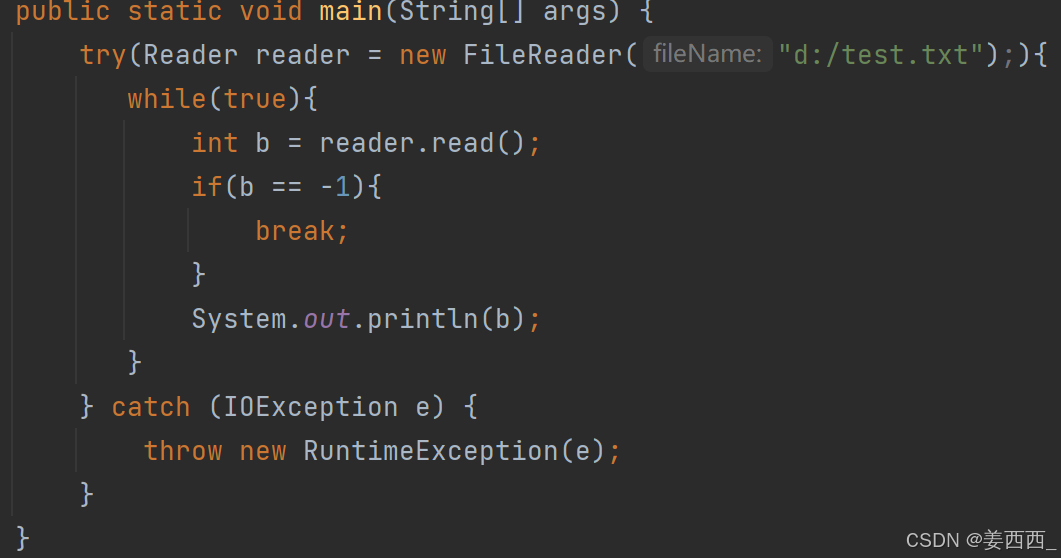
返回的是文档中对应的ascii值
如果文档中的是两个中文: 你好
我们用这种方式就可以读到
但是文档中使用的是utf8编码方式, 一个汉字表示3个字节
而java中的char是unicode编码方式, 一个汉字表示两个字节, 那是怎么读到完整字符的呢?
其实, read操作在读取的过程中, 能识别文件时utf8格式, 读的时候是三个字节, 返回char的时候, 把
utf8编码方式, 转成了unicode, 这样就读到了汉字
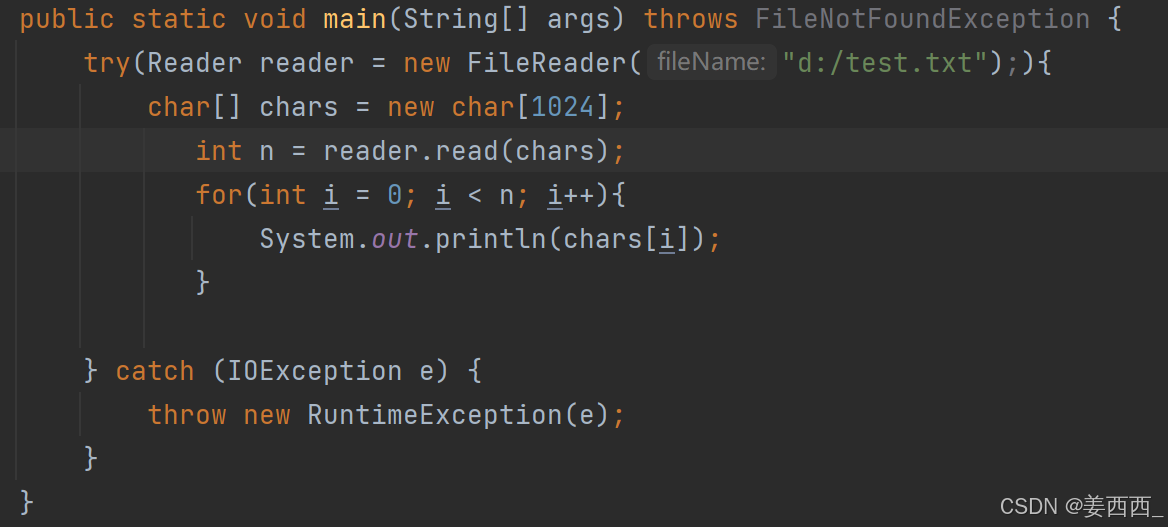
2. Writer, FileWriter

写方法:
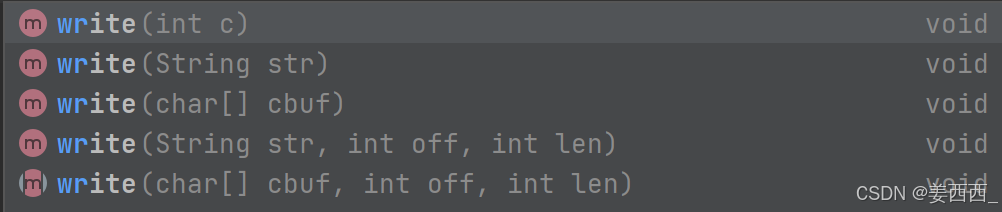
和上述字节流类似, 每次打开文件会覆盖掉原来的内容
把append设为true, 就变成了追加写的方式
三. 练习
示例一:
扫描指定⽬录,并找到名称中包含指定字符的所有普通⽂件(不包含⽬录),并且后续询问⽤⼾是否
要删除该⽂件
public class Demo6 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要查询的目录:");
String rootPath = scanner.next();
System.out.println("请输入要查询的文件");
String searchWord = scanner.next();
File file = new File(rootPath);
if(!file.isDirectory()){
System.out.println("输入的目录非法");
return;
}
searchFile(file, searchWord);
}
private static void searchFile(File file, String searchWord) {
File[] files = file.listFiles();//列出列表中包含了哪些内容
if(file == null){
return;
}
for (File x:
files) {
if(x.isFile()){
String name = x.getName();
if(name.contains(searchWord)){
System.out.println("找到匹配的文件" + x.getAbsolutePath());
return;
}
}else if(x.isDirectory()){
searchFile(x, searchWord);//使用递归遍历
}
}
}
}
实例二:
进⾏普通⽂件的复制
public class Demo7 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要复制的文件路径");
String srcPath = scanner.next();
System.out.println("请输入要复制到的目标路径");
String destPath = scanner.next();
File srcFile = new File(srcPath);
File destFile = new File(destPath);
if(!srcFile.isFile()){
System.out.println("要复制的文件非法");
return;
}
if(!destFile.getParentFile().isDirectory()){//只需要看上级目录是否合法, 如果没有目标文件会自动创建
System.out.println("目标路径非法");
}
try(InputStream inputStream = new FileInputStream(srcFile);
OutputStream outputStream = new FileOutputStream(destFile)){
while(true){
byte[] bytes = new byte[1024];
int n = inputStream.read(bytes);
if(n == -1){
break;
}
outputStream.write(bytes, 0, n);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
示例三:
扫描指定⽬录,并找到名称或者内容中包含指定字符的所有普通⽂件(不包含⽬录)
注意:我们现在的⽅案性能较差,所以尽量不要在太复杂的⽬录下或者⼤⽂件下实验
public class Demo6 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要查询的目录:");
String rootPath = scanner.next();
System.out.println("请输入要查询的内容");
String searchWord = scanner.next();
File file = new File(rootPath);
if(!file.isDirectory()){
System.out.println("输入的目录非法");
return;
}
searchFile(file, searchWord);
}
private static void searchFile(File file, String searchWord) {
File[] files = file.listFiles();
if(file == null){
return;
}
for (File x:
files) {
if(x.isFile()){
matchWord(x, searchWord);
}else if(x.isDirectory()){
searchFile(x, searchWord);
}
}
}
private static void matchWord(File x, String searchWord) {
try(Reader reader = new FileReader(x)){
StringBuffer stringBuffer = new StringBuffer();//将读到的所有内容放在里面
while(true){
int c = reader.read();
if(c == -1){
break;
}
stringBuffer.append((char)c);
}
if(stringBuffer.indexOf(searchWord) >= 0){
System.out.println("找到了匹配结果" + x.getAbsolutePath());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









