






在Linux中通过系统调用接口---fork()可以创建新进程。
简单介绍fork()函数---头文件为<unistd.h>
1.返回值:如果fork创建进程成功,则返回子进程的PID给父进程,返回0给子进程;
如果创建失败,则返回-1给父进程,无子进程创建。
返回类型为pid_t---正整数。
2.理解fork()函数,及父子进程的关系:
a.缓冲区
通过样例来逐步理解
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("before:\n");//创建新进程前
fork();//通过fork函数创建新进程
printf("after:\n");//创建进程后
return 0;
}执行此程序后发现输出为:

有两个after被打印出来,对此做出解释:
在fork后创建出一个新进程,我们称为子进程,将原来的进程成为父进程。
在fork之后的代码和数据又父子进程共享,因此after即被父进程执行,又被子进程执行,所以打印了两次。
继续:
#include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int main()
6 {
7 printf("begin->PPID:%d,PID:%d\n",getppid(),getpid());
8 sleep(2);
9 int id=fork();//fork创建成功返回子进程的PID给父进程,返回0给子进程
10 if(id>0)//若走此if,则为父进程
11 {
12 sleep(1);
13 printf("father:PPID:%d,PID:%d\n",getppid(),getpid());
14 }
15 else if(id==0)//若走此if,则为子进程
16 {
17 sleep(1);
18 printf("child:PPID:%d,PID:%d\n",getppid(),getpid());
19 }
20 else
21 {
22 printf("进程创建失败\n");
23 }
24 sleep(1);
25 printf("父子共享\n");//当fork创建成功后,其后代码父子进程都能运行,可以通过返回值的不同来使父子进程执行不同的代码
26 return 0;
27 } 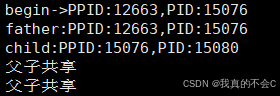
可以观察到子进程的PPID为父进程的PID,父进程的PPID和PID与fork之前的一致。
下面深入挖掘fork函数:
为什么fork函数要给子进程返回0,给父进程返回子进程的PID?
返回不同的返回值是为了区分父子进程,让父子进程执行不同的代码,一般而言,fork之后的代码是父子共享,因此可以根据返回值的不同,来让父子进程执行不同的代码。
如:
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t id=fork();
if(id==0)//子进程
{
printf("子进程功能:\n");
}
else if(id>0)
{
printf("父进程功能:\n");
}
return 0;
}一个函数是如何创建进程的?如何理解?
在没有fork之前,程序只有一个进程---由task_struct(PCB对象)和代码/数据构成。
在fork时,先以父进程的task_struct为模板,创建子进程的task_struct,然后父子进程共享父进程的代码/数据。
为什么fork会有两个不同的返回值?
在fork函数内部:
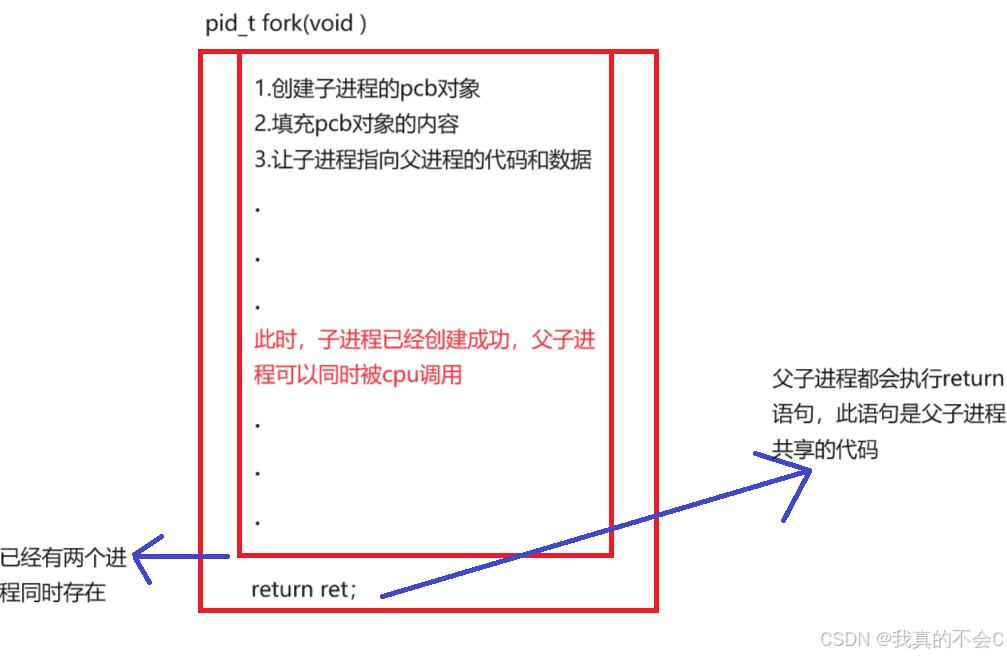
在fork函数内部通过两个进程来实现不同的返回值。
父子进程共享的代码/数据的细节。
fork之后,父子进程代码共享,代码是不可以修改的。但若一个进程修改数据,另一个进程也会受影响,破坏了父子进程间的独立性。
若让子进程单独拷贝一份完整的数据,又会造成空间浪费,因为子进程不一定会访问全部的数据。
因此,只有当子进程修改数据时,操作系统才重新开辟一块空间,让子进程区新空间写入。使子进程只对修改的数据申请空间,其余数据与父进程共享。

















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









