







目录
1.RestClient查询
文档的查询依然使用之前学习的 RestHighLevelClient对象,查询的基本步骤如下:
- 1)创建request对象,这次是搜索,所以是SearchRequest
- 2)准备请求参数,也就是查询DSL对应的JSON参数
- 3)发起请求
- 4)解析响应,响应结果相对复杂,需要逐层解析
1.1.快速入门
之前说过,由于Elasticsearch对外暴露的接口都是Restful风格的接口,因此JavaAPI调用就是在发送Http请求。而我们核心要做的就是利用利用Java代码组织请求参数,解析响应结果。
这个参数的格式完全参考DSL查询语句的JSON结构,因此我们在学习的过程中,会不断的把JavaAPI与DSL语句对比。大家在学习记忆的过程中,也应该这样对比学习。
1.1.1.发送请求
首先以match_all查询为例,其DSL和JavaAPI的对比如图: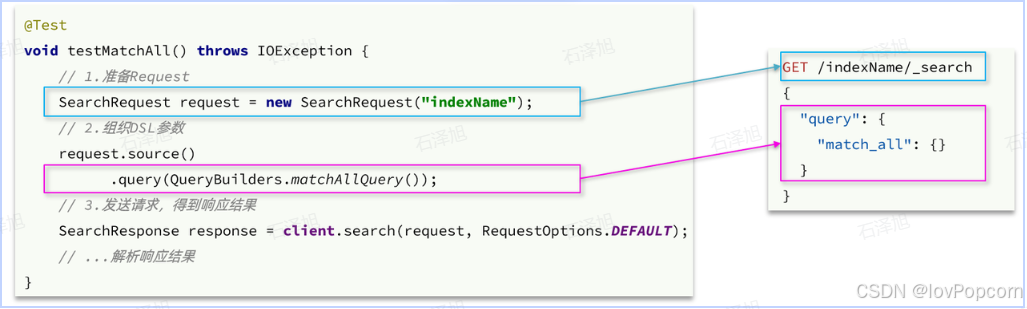
代码解读:
- 第一步,创建SearchRequest对象,指定索引库名
- 第二步,利用request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等
- query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
- 第三步,利用client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整JSON参数。其中包含了query、sort、from、size、highlight等所有功能: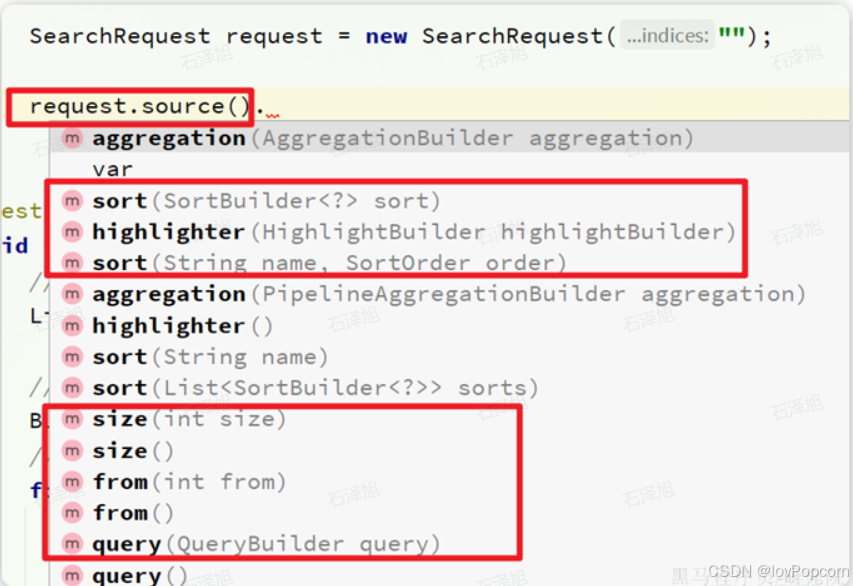
另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询、复合查询等: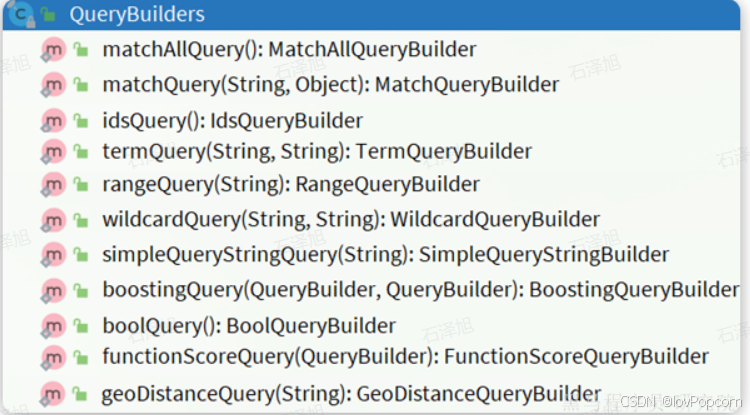
1.1.2.解析响应结果
在发送请求以后,得到了响应结果SearchResponse,这个类的结构与我们在kibana中看到的响应结果JSON结构完全一致:
{
"took" : 0,
"timed_out" : false,
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "heima",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Java讲师",
"name" : "赵云"
}
}
]
}
}因此,我们解析SearchResponse的代码就是在解析这个JSON结果,对比如下: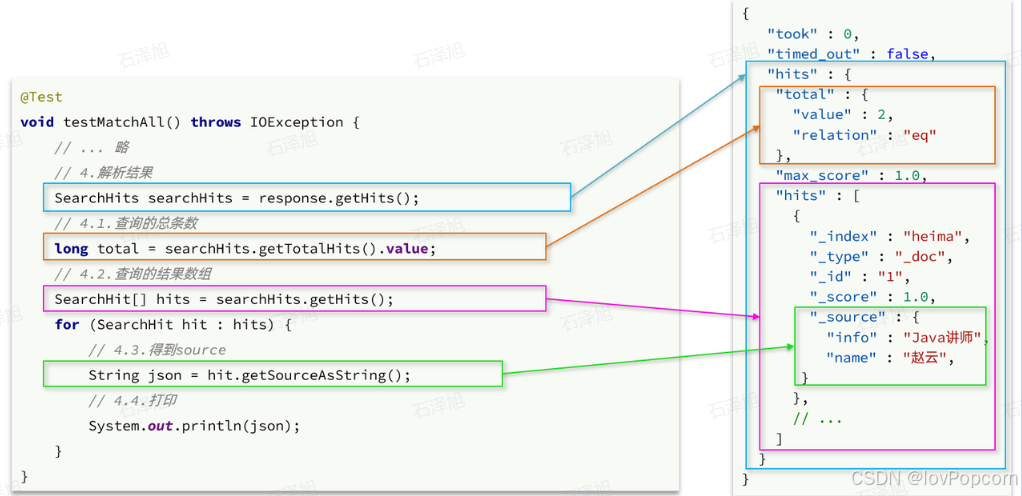
代码解读:
elasticsearch返回的结果是一个JSON字符串,结构包含:
- hits:命中的结果
- total:总条数,其中的value是具体的总条数值
- max_score:所有结果中得分最高的文档的相关性算分
- hits:搜索结果的文档数组,其中的每个文档都是一个json对象
- _source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
- SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果
- SearchHits#getTotalHits().value:获取总条数信息
- SearchHits#getHits():获取SearchHit数组,也就是文档数组
- SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
1.1.3.总结
文档搜索的基本步骤是:
-
创建
SearchRequest对象 -
准备
request.source(),也就是DSL。-
QueryBuilders来构建查询条件 -
传入
request.source()的query()方法
-
-
发送请求,得到结果
-
解析结果(参考JSON结果,从外到内,逐层解析)
完整代码如下:
@Test
void testMatchAll() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
request.source().query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(S 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









