






为什么要学习pandas
numpy能够帮我们处理处理数值型数据,但是这还不够
很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据
比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等
所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
什么是pandas
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data
structures and data analysis tools for the Python programming language.
pandas的常用数据类型
1:Series 一维,带标签数组
2:DataFrame 二维,Series容器
pandas之Series创建
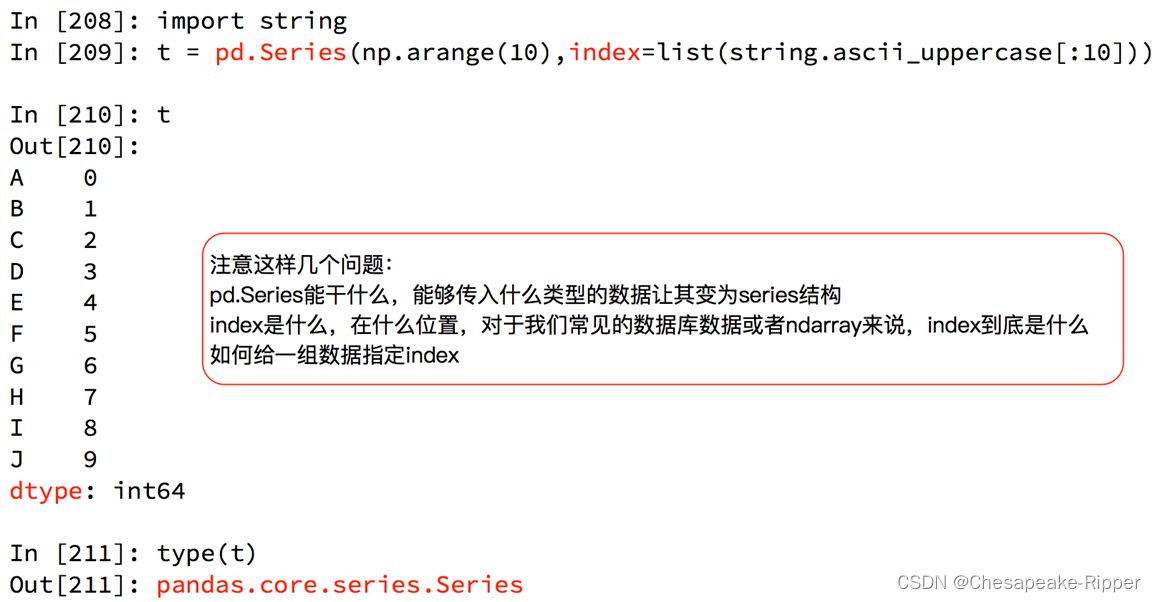
创建Series的几种方式
(ipython展示)
第一种方式指定数组的下标:
In [7]: t2= pd.Series([1,2,31,12,3,4],index = list("abcdef"))
In [8]: t2
Out[8]:
a 1
b 2
c 31
d 12
e 3
f 4
dtype: int64
第二种方式指定数组的下标:
用字典转化为Series数组
key对应为下标 , value对应值
In [9]: temp_dict ={
...: "name":"xiaohong"
...: ,"age":30,
...: "tel":10086}
In [10]: t3= pd.Series( temp_dict)
In [11]: t3
Out[11]:
name xiaohong
age 30
tel 10086
dtype: object
pandas之Series切片和索引
1:普通的直接用下标取元素
2:不连续的下标取元素
3:利用bool布尔索引取元素
4:series的遍历
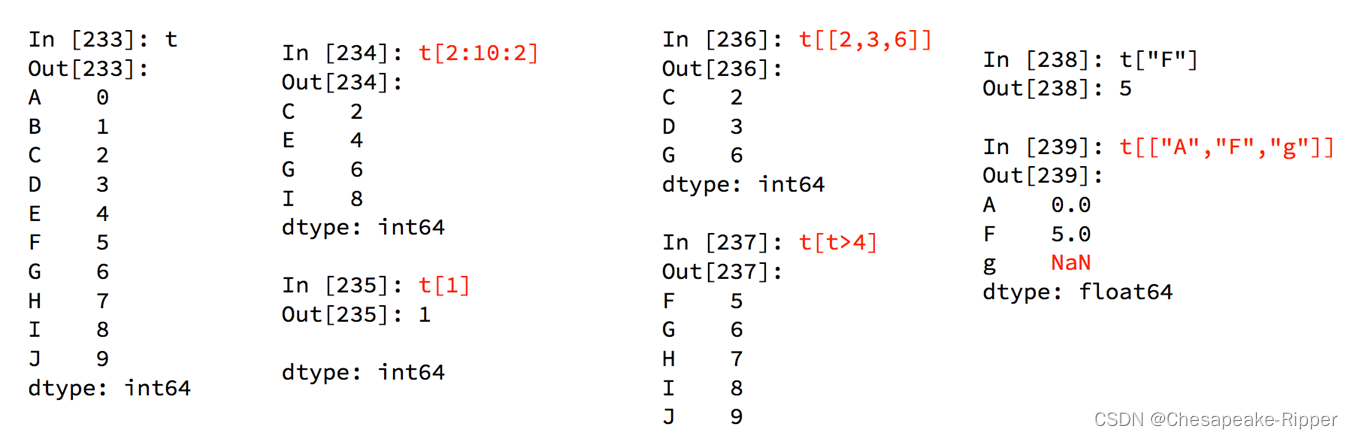

普通取元素:
In [14]: t2[0]
Out[14]: 1
In [15]: t3["name"]
Out[15]: 'xiaohong'
不连续取元素
In [17]: t3[["name","age"]]
Out[17]:
name xiaohong
age 30
dtype: object
布尔索引
In [19]: t[t>4]
Out[19]:
2 31
3 12
dtype: int64
for循环遍历Series数组
In [20]: t3.index
Out[20]: Index(['name', 'age', 'tel'], dtype='object')
In [22]: for i in t3.index:
...: print(i)
...:
name
age
tel
如何了解一个陌生series的索引,和它的具体的值?
index查看下标,values查看对应的值
In [23]: type(t3.index)
Out[23]: pandas.core.indexes.base.Index
In [24]: len(t3.index)
Out[24]: 3
In [26]: list(t3.index)
Out[26]: ['name', 'age', 'tel']
In [28]: list(t3.index)[:2]
Out[28]: ['name', 'age']
从头开始遍历,一直到【2】 ,不包括下标2的数字
In [29]: t3.values
Out[29]: array(['xiaohong', 30, 10086], dtype=object)pandas之读取外部数据
现在假设我们有一个组关于狗的名字的统计数据,那么为了观察这组数据的情况,我们应该怎么做呢?
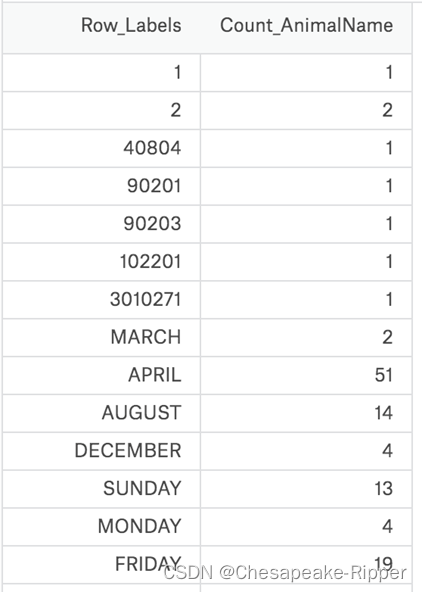
数据来源:https://www.kaggle.com/new-york-city/nyc-dog-names/data
我们的这组数据存在csv中,我们直接使用pd. read_csv即可
对于数据库比如mysql:
pd.read_sql(sql_sentence,connection)
和我们想象的有些差别,我们以为他会是一个Series类型,但是他是一个DataFrame,那么接下来我们就来了解这种数据类型
读出来的数据是:
<class 'pandas.core.frame.DataFrame'>的类型
import pandas as pd
df = pd.read_csv("E:\\Python黑马课件\\dogNames2.csv")
print(type(df))
<class 'pandas.core.frame.DataFrame'>pandas之DataFrame
DataFrame和Series有什么关系呢? DataFrame是Series的容器!
import pandas as pd
d2 = [{"name":"xiaohong","age":32,"tel":10086},{"name":"xiaohong","age":32,"tel":10086},{"name":"xiaohong","age":32,"tel":10086}]
t2=pd.DataFrame(d2)
print(t2.info())
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1

DataFrame的函数属性

d2 = [{"name":"xiaohong","age":32,"tel":10086},{"name":"xiaohong","age":32,"tel":10086},{"name":"xiaohong","age":32,"tel":10086}]
t2 = pd.DataFrame(d2)
In [12]: t2.head(2)
Out[12]:
name age tel
0 xiaohong 32 10086
1 xiaohong 32 10086
In [14]: t2.tail(1)
Out[14]:
name age tel
2 xiaohong 32 10086
In [15]: t2.info
Out[15]:
<bound method DataFrame.info of name age tel
0 xiaohong 32 10086
1 xiaohong 32 10086
2 xiaohong 32 10086>
In [16]: t2.describe()
Out[16]:
age tel
count 3.0 3.0
mean 32.0 10086.0
std 0.0 0.0
min 32.0 10086.0
25% 32.0 10086.0
50% 32.0 10086.0
75% 32.0 10086.0
max 32.0 10086.0
In [17]: t2.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 3 non-null object
1 age 3 non-null int64
2 tel 3 non-null int64
dtypes: int64(2), object(1)
memory usage: 204.0+ bytespandas之取行或者列
df_sorted = df.sort_values(by="Count_AnimalName")
df_sorted[:100]
import pandas as pd
df = pd.read_csv("E:\\Python黑马课件\\dogNames2.csv")
print(df.head(5))#排名前五
print(df[:20])#取前20行
print(df[:20]["Count_AnimalName"])
print(df["Count_AnimalName"])#取特定的列 Count_AnimalNamepandas之iloc
还有更多的经过pandas优化过的选择方式:
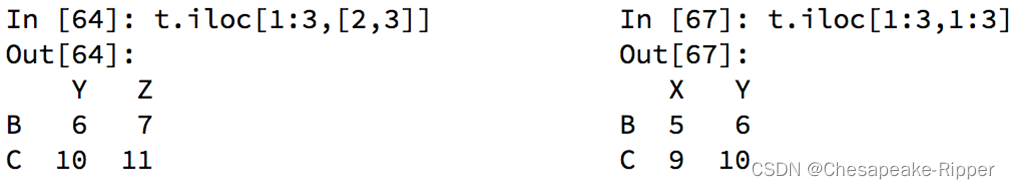
赋值更改数据的过程:
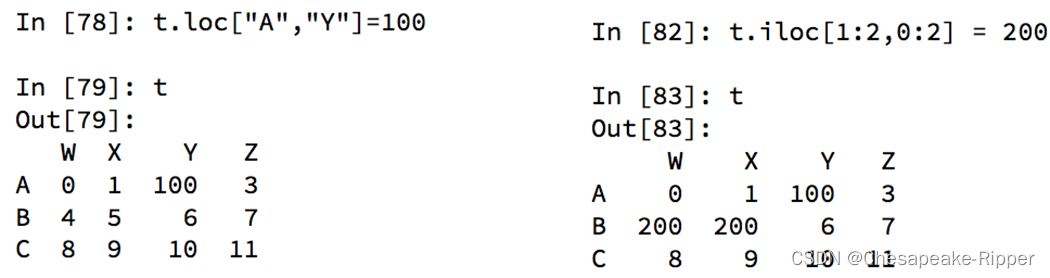
loc的用法代码展示:
In [4]: t3 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
In [5]: t3
Out[5]:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
In [6]: t3.loc["a","Z"]
Out[6]: 3
In [7]: type(t3.loc["a","Z"])
Out[7]: numpy.int32
In [8]: t3.loc["a"]
Out[8]:
W 0
X 1
Y 2
Z 3
Name: a, dtype: int32
In [9]: t3.loc["a",:]
Out[9]:
W 0
X 1
Y 2
Z 3
Name: a, dtype: int32
In [11]: t3.loc[:,"Y"]
Out[11]:
a 2
b 6
c 10
Name: Y, dtype: int32
不连续的多行
In [13]: t3.loc[["a","c"]]
Out[13]:
W X Y Z
a 0 1 2 3
c 8 9 10 11
不连续的多列
In [15]: t3.loc[:,["W","Z"]]
Out[15]:
W Z
a 0 3
b 4 7
c 8 11
In [16]: t3.loc[["a","c"],["W","Z"]]
Out[16]:
W Z
a 0 3
c 8 11
In [17]: t3.loc["a":"c",["W","Z"]]
Out[17]:
W Z
a 0 3
b 4 7
c 8 11
In [19]: t3.iloc[0]
Out[19]:
W 0
X 1
Y 2
Z 3
Name: a, dtype: int32
In [20]: t3.iloc[1]
Out[20]:
W 4
X 5
Y 6
Z 7
Name: b, dtype: int32
In [21]: t3.iloc[2]
Out[21]:
W 8
X 9
Y 10
Z 11
Name: c, dtype: int32
In [22]: t3.iloc[1,:]
Out[22]:
W 4
X 5
Y 6
Z 7
Name: b, dtype: int32
In [23]: t3.iloc[:,2]
Out[23]:
a 2
b 6
c 10
Name: Y, dtype: int32
In [24]: t3.iloc[:,[2,1]]
Out[24]:
Y X
a 2 1
b 6 5
c 10 9
In [25]: t3.iloc[[0,2],[2,1]]
Out[25]:
Y X
a 2 1
c 10 9
In [26]: t3.iloc[1:,:2] = 30
In [27]: t3
Out[27]:
W X Y Z
a 0 1 2 3
b 30 30 6 7
c 30 30 10 11
pandas之布尔索引
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过800的狗的名字,应该怎么选择?

回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过700并且名字的字符串的长度大于4的狗的名字,应该怎么选择?
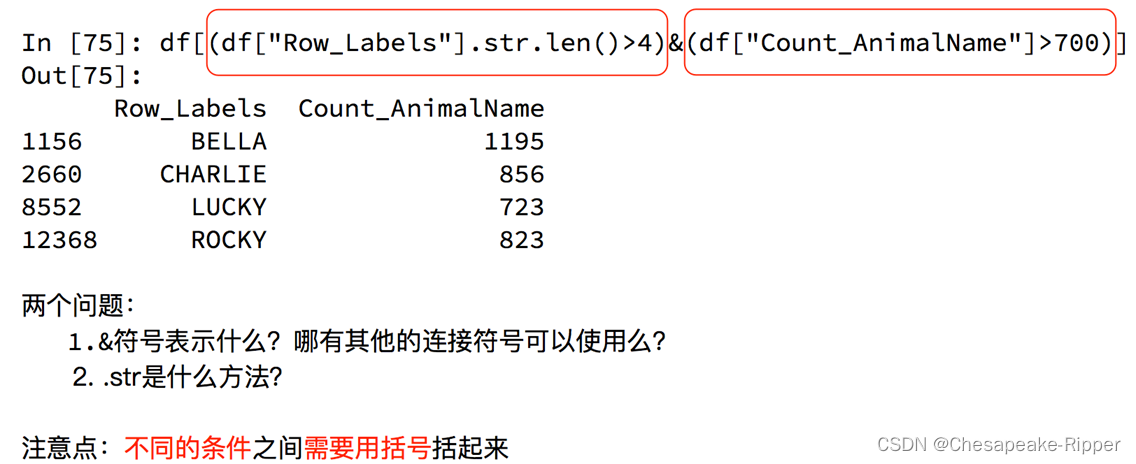

import pandas as pd
df = pd.read_csv("E:\\Python黑马课件\\dogNames2.csv")
print(df[(df["Count_AnimalName"]>830)&(df["Count_AnimalName"]<1000)])
print(df[(df["Row_Labels"].str.len()>4)&(df["Count_AnimalName"]>800)])
Row_Labels Count_AnimalName
2660 CHARLIE 856
3251 COCO 852
Row_Labels Count_AnimalName
1156 BELLA 1195
2660 CHARLIE 856
12368 ROCKY 823
















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









