







前言
其实和TTT没啥关系,但是还是看,反正我时间很多(链接:https://arxiv.org/pdf/2411.19477)
正文
个人初步总结
这篇论文实际上就是提出了一套流程,在没有提出新的模型架构的情况下用新的计算流程让整个系统准确率能更高,但是有一定的要求(解决问题的LLM一定要能给出正确的答案,如果给出正确答案的概率是0也白搭),然后作者从数学原理上证明了他这套系统在一定情况下能把错误率减到0。
这个就好比什么呢,LLM是一个纯黑盒的回答机器,他会根据问题输出答案,但是得出正确答案的概率会变,可能从5%到90%都有可能,所以一般人都不会真正去相信它,因为没有办法让这个玩意给出正确答案的概率升级到99%,这样大家就会相信它了。所以作者就给出了一套系统,它让我们在完全不改动这个LLM黑盒本身的回答正确概率的情况下,让这个新的系统用LLM黑盒得出正确率能到99%甚至100%的回答,这样就让大家能完全的相信这玩意。
我看完就说,感觉是在弓箭时代没去研究改变弓箭的结构让箭得更准,而是发明了弓箭手方阵这样总有射中的箭,但是凡事都有代价,这个系统的代价肯定是会在推理阶段花更多的力气。
作者的系统
有一说一,作者的系统其实非常好懂,就是大力出奇迹,生成一堆答案,然后通过一个系统来筛选出一个正确率最高的答案,不过我还是认真写一下流程吧,数学分析也会做的(但是会在下一个小节
本质上就是两步:
N个答案的生成
用多个LLM来生成,很简单吧,但是这篇文章的作者是用70B和72B的模型做的。。。阿里真是财大气粗啊
淘汰赛
这个是重点,怎么在这么多的回答中筛出正确的答案呢
for K times. The winner of each pair is the one that is favored for more than K/2 times; ties are broken arbitrarily. Only the winners will move on to the next round. The final-round winner at the end of this tournament will be the final output of the algorithm.

上面是原文和图片,下面用我的话讲一遍:
目标: 从多个候选答案中选出最佳答案作为最终输出。
过程:
- 随机配对: 将候选答案随机分成一对一对的。
- 多次比较: 对每一对候选答案进行比较 K 次。每次比较都会选择一个胜者。
- 选择胜者: 比较结束后,获得超过 K/2 次胜利的候选答案被视为该轮的胜者。如果出现平局,则随机选择一个胜者。
- 下一轮: 只有胜者才能进入下一轮比赛。
- 最终结果: 经过多轮比赛,最终剩下的胜者即为算法的最终输出。
举例说明:
假设有 8 个候选答案,K = 2。
- 第一轮: 将 8 个候选答案随机配对成 4 组,每组进行比较 2 次。例如,假设第一组两个候选答案的比较结果分别为 A 胜 B 和 B 胜 A,那么这一组的胜者为 B。
- 第二轮: 将 4 个胜者再次随机配对成 2 组,每组进行比较 2 次。例如,假设第一组的胜者为 B 和 D,比较结果分别为 B 胜 D 和 D 胜 B,那么这一组的胜者为 D。
- 第三轮: 最后 2 个胜者进行比较 2 次,例如,假设胜者为 D 和 E,比较结果分别为 D 胜 E 和 E 胜 D,那么最终的胜者为 D,即算法的最终输出。
这个淘汰赛的过程类似于体育比赛中的淘汰赛制,通过不断筛选,最终选出最佳的候选答案。
那么比较这个动作是谁来做呢?显然比较这个动作是由 LLM 来完成的。LLM 被用作一个黑盒模型,负责评估两个候选答案的优劣,并输出比较结果。
上面其实就是所有流程了,你可能注意到了,这个玩意需要一些限制才能保证最后的正确率能达到很高,这个也是作者后面的数学推理的基础:
- LLM给出答案的正确率不能是0,不然你再怎么比较也不可能保证这个系统的正确率能到100%,如果有一次给出的都是错误答案那你再选也没辙。
- LLM做比较的正确率大于你随机选择(这个动作的正确率是50%)
在这两个假设的限制下,这个系统的成功率才能到100%(理论上)
数学分析部分
数学分析部分其实也很好理解,没有涉及很多很难的东西.
首先先介绍一下后面要用的变量
N和K,分别代表着生成N个答案和进行K次比较,然后是
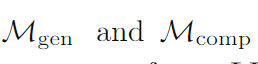
在这段描述中:
-
M g e n M_{gen} Mgen 代表的是在一次大型语言模型(LLM)调用以生成候选解决方案时,其输出结果的概率分布。也就是说,当利用LLM去尝试生成一个有可能解决给定问题的候选方案时,这个生成过程对应的输出所遵循的概率分布情况由 M g e n M_{gen} Mgen 来表示。
-
M c o m p M_{comp} Mcomp 代表的是在利用LLM对一对解决方案进行比较时,其输出结果的概率分布。例如针对两个已经存在的解决方案,使用LLM来判断它们谁更优或者它们之间的相对关系等情况时,LLM此次比较操作输出所遵循的概率分布就用 M c o m p M_{comp} Mcomp 来表示。
所以给定一个输入问题X,在算法的第一个阶段,答案是符合
M
g
e
n
M_{gen}
Mgen 的分布的:
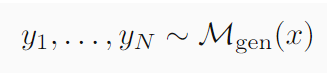
然后在第二阶段,淘汰赛阶段,对于每一个候选者
(
y
,
y
′
)
(y,y^{\prime})
(y,y′),算法对于
K
K
K个独立比较结果进行采样:
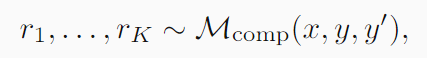
这是基本的流程,然后接下来是两条定理,限制了计算的情况:
1.
第一条定律,模型输出正确答案的概率不能为0,必然要大于0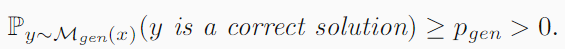
2.
第二条定律,比较一对正确和错误的解决方案时比随机猜测做得更好也就是说政正确概率大于50%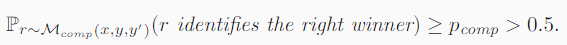
在这两条规律的限制下开始推导:
- 定理一:如果输入问题满足假设 1,则所提出的两阶段算法在超参数 N和 K下的失败概率有如下界限:
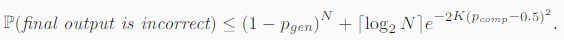
看起来很复杂的公式,不是么,接下来开始推导:
- 第一阶段,也就是生成部分,独立的进行了N次采样,所以我们的无正确解的概率是:
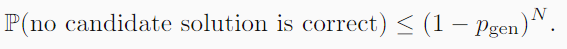 显然
显然 - 然后是淘汰赛阶段,这个会稍微复杂一点,先考虑一对正确和错误的候选方案,他们被比较了K次,而且每次比较的结果的正确率—下面的公式称之为µ----都大于随机选择(也就是说大于50%),Xi表示均值为µ的独立伯努利随机变量:所以我们得出,经历了K次比较之后失败的概率公式:
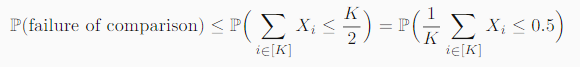
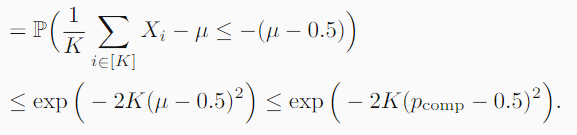 这里我就先不显然了,因为这里是做了一定的推理的:
这里我就先不显然了,因为这里是做了一定的推理的:
- 首先对于最早的不等式我做一个解释,Xi的本质含义就是第i个比较是否正确,所以对于Xi的求和的本质就是看K次比较里正确的总次数,显然比较失败意味着正确识别的次数少于一半,也就是:
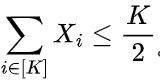 所以失败的概率实际上会等于上面这个式子,但是作者用了一个放缩先写成了小于等于,再进一步的写法就是:
所以失败的概率实际上会等于上面这个式子,但是作者用了一个放缩先写成了小于等于,再进一步的写法就是: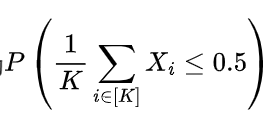 当平均次数小于等于0.5时,就认为比较失败了(符合第二个假设)。
当平均次数小于等于0.5时,就认为比较失败了(符合第二个假设)。 - 然后在此引入均值μ,这一步就是不等式两边减了一个μ,为了后面的不等式做准备
- 使用 Hoeffding 不等式:
 ,所以直接套公式就好,然后又因为已知μ>Pcomp>0.5,所以又能进行一次替换,换成最后的形式,最终完成了对比较这对候选解决方案失败概率的推导和界定。
,所以直接套公式就好,然后又因为已知μ>Pcomp>0.5,所以又能进行一次替换,换成最后的形式,最终完成了对比较这对候选解决方案失败概率的推导和界定。
- 最后就是把两个阶段的概率合在一起来看:在控制淘汰赛阶段失败概率时,先基于生成阶段至少有一个正确初始候选方案这一前提。任选一个正确候选方案,关注其在二叉树结构里通向算法最终输出的路径。通过归纳法可证明,路径上每对候选方案用(K)次LLM调用比较时,若有一个输入候选方案正确,其比较失败概率不超
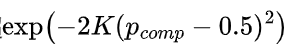 沿此含log2N对比较的路径,用并集界可知整体比较得出正确结果(即算法最终输出正确)的失败概率不超
沿此含log2N对比较的路径,用并集界可知整体比较得出正确结果(即算法最终输出正确)的失败概率不超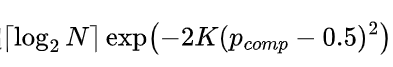 ,以此对算法在该阶段输出正确结果的概率情况进行了分析界定。 最后,对算法两个阶段的失败事件取并集,完成了对定理 1 的证明。
,以此对算法在该阶段输出正确结果的概率情况进行了分析界定。 最后,对算法两个阶段的失败事件取并集,完成了对定理 1 的证明。
所以说失败概率随着确定测试时间计算量的超参数 N和 K指数衰减至零。
后记
看完的感觉就是:
大力出奇迹啊,作者用的还是72B的和70B的模型做的实验(用了阿里自己的通义千问,他这套系统还得好几个LLM(最多的实验有32LLM个并行)并行执行,阿里是真有钱啊
但是这种系统,虽然说没看过完全一样的,但是类似思想看过很多,比如说让LLM对一个问题生成多个答案然后通过投票系统啥的筛出最有可能的答案,这个和作者的并行生成多个回答的区别就在于没他快吧(,后面的筛选系统感觉有很多方法(作者这个用LLM来负责比较的系统还得加个LLM选择的正确概率大于随机选择的正确概率(50%)的假设
所以作者的创新点在于数学理论论证和并行生成并行筛选系统?而且他这个实验结果想要复现的话估计只有超级大企业能做吧(
感觉大模型还是得跟企业一起搞啊,不然这么猛的算力高校哪里提供的了啊(
不过在我和老师交流过后,老师的回应也我也记录一下:
这篇文章的定位其实是和大模型训练的 scaling law 一样。大模型的 scaling law 给大模型的训练提供了一个理论(其实是经验公式)指导,就是如何有效调配算法、数据、模型,比如要想提升模型性能,光增大模型 size 还不行,还需要提升数据集大小。
这篇文章是类似的,但关注点不在大模型训练上,而是test-time computation,简单来说就是模型参数不变,而是在模型输出/解码过程中做文章。这里就有很多方法,但是大部分都是基于多次输出选最好的,可以是 best-of-N,可以是 voting,可以是更复杂的搜索,甚至可以训练一个小模型来指导大模型的输出/解码过程(比如 OpenAI-o1,DeepSeek-o1,QwQ 等)。那么这里就有一个问题,是否在test-time computation 中投入更大的算力(比如并行数更大,搜索深度更深,小模型训练得更好)就可以带来大模型效果的提升呢?我们也需要一个 scaling law 来指导。这就是这篇文章想做的事情,通过大规模实验,来看看是否存在 test-time computation的 scaling law。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









