







两大支线:Collection和Map:
1、Collection,主要由List、Set、Queue组成:
- List 代表有序、可重复的集合,典型代表有封装动态数组的 ArrayList 和 封装链表的 LinkedList;
- Set 代表无序、不可重复的集合,典型代表有 TreeSet 和 HashSet;
- Queue 代表先进先出(FIFO)的队列,典型代表就是双端队列 ArrayDeque 和优先级队列 PriorityQueue。
2、Map,代表键值对(key-value)的集合,典型代表就是 HashMap、LinkedHashMap。
| 接口 | 特点 | 实现类 |
|---|---|---|
| List (列表) | 有序、可重复 | ArrayList、LinkedList |
| Set(集合) | 无序、不可重复 | HashSet、TreeSet |
| Queue(队列) | 保持元素队列 | PriorityQueue、ArrayDeque |
| Map(映射) | 键值对:一个键映射到一个值 | HashMap、LinkedHashMap |
List
List 有 ArrayList 和 LinkedList 两个代表,关于这两个的叙述在前文有提及:ArrayList 和 LInkedList 的区别
Set
在 Java 中,TreeSet 和 HashSet 都是 Set 接口的实现类,主要用于存储 不重复 的元素。但它们的底层实现、排序方式以及性能差异较大。
TreeSet:
特点:
- 基于红黑树(Red-Black Tree)实现,底层使用
TreeMap维护元素的顺序。 - 元素是有序的,默认按照 自然顺序(Comparable) 排序,或者根据自定义的 Comparator 进行排序。
- 查找、插入、删除的时间复杂度为 O(log N),比
HashSet慢,但能保证顺序。
顺便在此补充一下红黑树是什么:
红黑树(Red-Black Tree)
红黑树是一种 自平衡二叉搜索树(Balanced Binary Search Tree),用于保持数据的有序性,并在插入、删除操作后维持 近似平衡,避免二叉搜索树退化成链表。
红黑树的特性
红黑树满足以下 五大特性:
- 每个节点要么是红色,要么是黑色。
- 根节点始终是黑色。
- 红色节点的子节点必须是黑色(即 不能有连续的红色节点)。
- 从任意一个节点到其所有叶子节点的路径中,黑色节点的数量必须相同(即 黑色平衡)。
- 新插入的节点默认为红色。

TreeSet 使用示例
import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(10);
treeSet.add(5);
treeSet.add(20);
treeSet.add(15);
System.out.println(treeSet); // [5, 10, 15, 20] 按照升序排列
}
}
适用场景
- 需要 排序 的场景,例如:存储排名、时间戳、字典排序等。
- 需要 范围查找 的场景,例如
headSet()、tailSet()、subSet()方法,能快速查找区间数据。
HashSet
特点
- 基于
HashMap实现,底层使用HashMap存储元素。 - 元素是无序的,存储顺序可能会随哈希值的变化而改变。
- 查找、插入、删除的时间复杂度为 O(1)(在哈希冲突少的情况下),比
TreeSet更快。
使用示例
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
HashSet<Integer> hashSet = new HashSet<>();
hashSet.add(10);
hashSet.add(5);
hashSet.add(20);
hashSet.add(15);
System.out.println(hashSet); // [20, 5, 10, 15] 取决于 hash 值的计算:hash % 16
}
}
适用场景
- 去重但不关心顺序 的场景,例如存储用户 ID、缓存数据等。
- 插入和查找速度要求快,比如 集合操作、统计唯一值等。
TreeSet vs HashSet 区别对比
| 对比项 | TreeSet | HashSet |
|---|---|---|
| 底层数据结构 | 红黑树(TreeMap) | 哈希表(HashMap) |
| 排序 | 有序(按照自然顺序或 Comparator) | 无序 |
| 增删改查时间复杂度 | O(log N) | O(1)(哈希冲突少时) |
| 适合场景 | 需要排序、范围查询 | 插入/查找快,不关心顺序 |
| 内存消耗 | 较大(存储树结构) | 较小 |
什么时候用 TreeSet?什么时候用 HashSet?
- 如果需要排序(如按字母、时间、数值等),用 TreeSet。
- 如果不关心顺序,只是要存储不重复的元素,并且查找速度要求快,用 HashSet。
Queue
1. Queue 概述
Queue(队列)是 Java 集合框架 (java.util.Queue 接口) 中的一种 FIFO(First In First Out,先进先出) 数据结构,主要用于 存储等待处理的元素,常用于任务调度、消息队列等场景。其代表包括 PriorityQueue(优先级队列) 和 ArrayDeque(双端队列)。
1. PriorityQueue(优先级队列)
概述
PriorityQueue是 基于堆(Heap) 实现的 优先级队列,元素按照 自然顺序 或 自定义比较规则 进行排序。- 默认是最小堆(最小元素优先出队),也可以自定义比较器改为最大堆。
- 不允许存
null值,不保证插入顺序,但 保证元素出队时是有序的。
底层实现
- 使用 二叉堆(最小堆),默认 数组存储(默认初始容量 11)。
- 通过 上浮(siftUp)和下沉(siftDown) 操作维持堆结构。
- 时间复杂度:
- 入队(
offer):O(log N) - 出队(
poll):O(log N) - 查看队头(
peek):O(1)
- 入队(
代码示例
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.offer(30);
pq.offer(10);
pq.offer(20);
System.out.println("队列内容:" + pq); // 输出无序,但出队有序
while (!pq.isEmpty()) {
System.out.println("出队:" + pq.poll());
}
}
}
输出
队列内容:[10, 30, 20]
出队:10
出队:20
出队:30
应用场景
- 任务调度(如 CPU 任务管理)
- 最短路径算法(如 Dijkstra)
- 高频元素统计(如 Top K 问题)
2. ArrayDeque(数组双端队列)
概述
ArrayDeque是 双端队列(Deque) 的 数组实现,支持 队列(FIFO)和栈(LIFO) 两种用法。- 比
LinkedList更快,因为LinkedList需要维护额外的指针,而ArrayDeque直接操作数组。 - 无界(但实际受
Integer.MAX_VALUE限制)。 - 不允许存
null值。
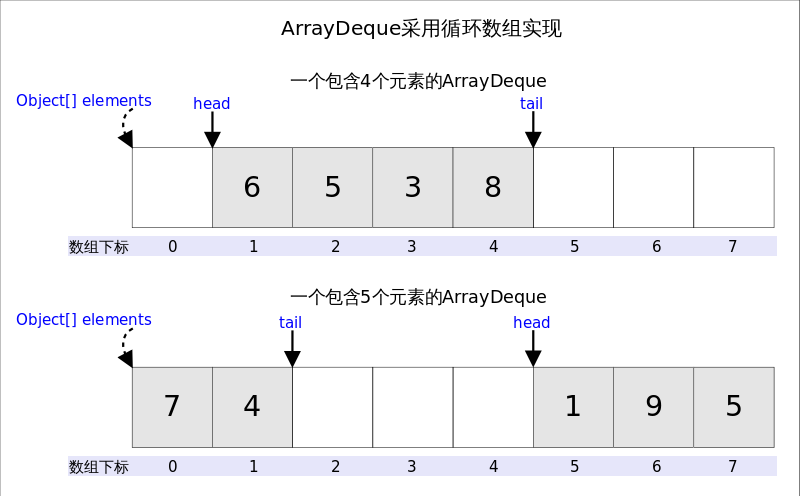
底层实现
- **使用
Object[]数组 存储元素,采用循环数组(避免扩容时数据搬移)。 - 默认初始容量 16,满时 扩容为 2 倍。
- 时间复杂度:
- 入队/出队(
offerFirst、pollFirst、offerLast、pollLast):O(1) - 扩容时:O(N)
- 入队/出队(
代码示例
import java.util.ArrayDeque;
public class ArrayDequeExample {
public static void main(String[] args) {
ArrayDeque<Integer> deque = new ArrayDeque<>();
// 从队尾添加
deque.offerLast(1);
deque.offerLast(2);
deque.offerLast(3);
System.out.println("队列:" + deque); // [1, 2, 3]
// 从队头取出
System.out.println("出队:" + deque.pollFirst()); // 1
// 栈用法(先进后出)
deque.push(10);
System.out.println("栈顶元素:" + deque.peek()); // 10
}
}
应用场景
- 高效队列实现(比
LinkedList性能更优) - 双端操作(如滑动窗口问题)
- 实现栈(替代
Stack类)
3. PriorityQueue vs ArrayDeque
| 对比项 | PriorityQueue(优先级队列) | ArrayDeque(双端队列) |
|---|---|---|
| 数据结构 | 二叉堆(最小堆或最大堆) | 循环数组 |
| 插入顺序 | 无序(内部排序) | 有序(FIFO 或 LIFO) |
| 取出顺序 | 按优先级取出 | 按插入顺序取出 |
| 时间复杂度 | O(log N)(插入、删除) | O(1)(插入、删除) |
是否允许 null | ❌ 否 | ❌ 否 |
| 使用场景 | 任务调度、最短路径算法 | 队列、栈、滑动窗口 |
Map
Map 介绍
Map 是 Java 中用于存储键值对 (key-value) 的数据结构,每个键唯一映射到一个值。常见的 Map 实现包括 HashMap 和 LinkedHashMap,它们在存储方式、访问效率、是否保持插入顺序等方面有所不同。
1. HashMap
特点
- 基于哈希表实现,存储的是 键值对。
- 无序,不能保证插入顺序。
- 允许
null作为键和值。 - 线程不安全,多个线程同时修改 HashMap 可能导致数据不一致(可以使用
Collections.synchronizedMap()或ConcurrentHashMap)。 - 采用 拉链法 解决哈希冲突,JDK 1.8 之后引入红黑树优化。
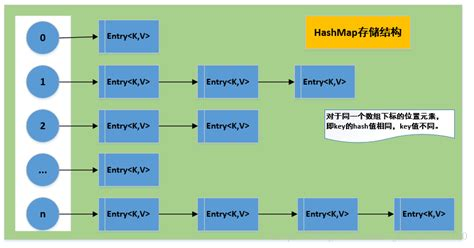
底层实现
- 采用 数组 + 链表/红黑树 结构存储数据。
- 哈希计算:
key.hashCode()计算哈希值后,通过 (n - 1) & hash 确定数组索引。 - 扩容机制:默认 容量 16,负载因子 0.75,当超过容量的 75% 时扩容为 2 倍。
- 红黑树优化:当链表长度超过 8,转换为红黑树,提高查找效率。
2. LinkedHashMap(添加链表使得 HashMap 有序)
特点
- 有序,按照 插入顺序 或 LRU(最近最少使用)顺序 进行存储。
- 继承自
HashMap,在 HashMap 的基础上增加了双向链表,以维护元素顺序。 - 允许
null作为键和值。 - 性能略低于 HashMap,因为需要维护链表结构。
- 适用于缓存场景(如 LRU 缓存)。
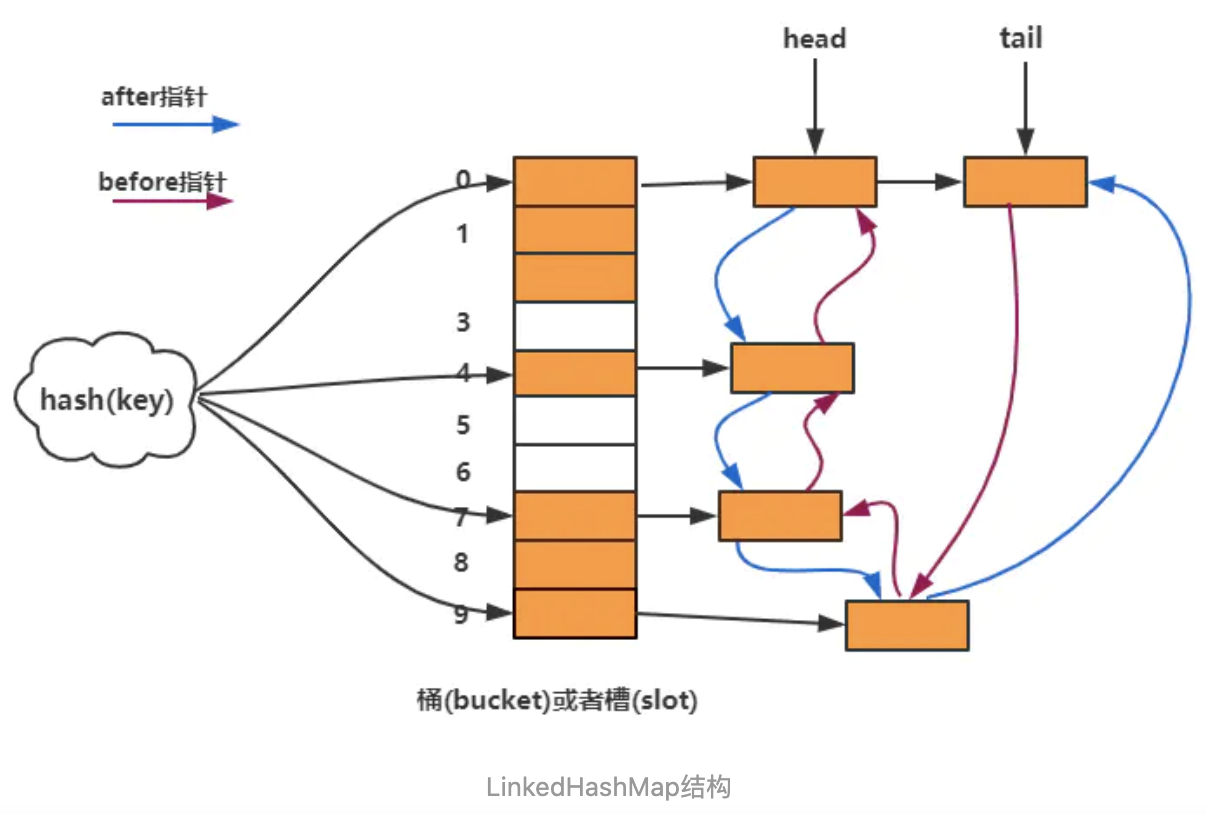
底层实现
- 继承
HashMap,但在每个节点中额外维护了一个双向链表,用于记录元素的插入顺序或访问顺序(LRU)。 - 扩展了
Entry结构,新增了before和after指针:static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; } - 通过
accessOrder决定顺序:false(默认):保持 插入顺序。true(LRU):每次访问都会将节点移动到队尾,形成 最近最少使用淘汰策略。
总结
- HashMap:基于哈希表,无序存储,查找快(O(1))。
- LinkedHashMap:继承自
HashMap,有序存储,适用于缓存(LRU)场景。
你可以在高性能存储或缓存设计中选择合适的 Map,如果需要维持顺序或 LRU 淘汰机制,推荐使用 LinkedHashMap。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









