








地址:aHR0cHM6Ly9zdHUudHVsaW5ncHl0b24uY24vcHJvYmxlbS1kZXRhaWwvNi8=
查看启动器
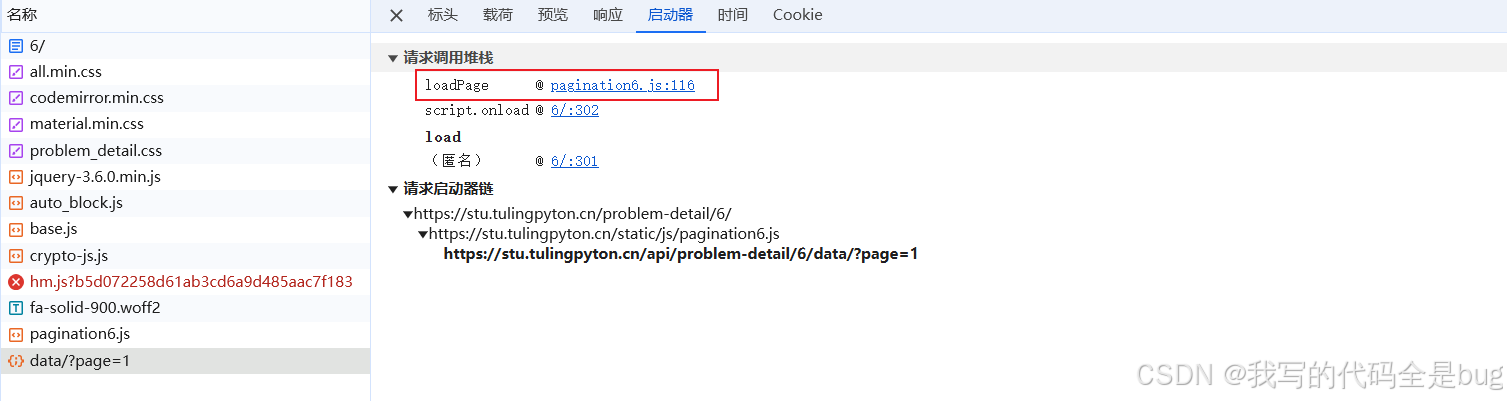
开始断点调试
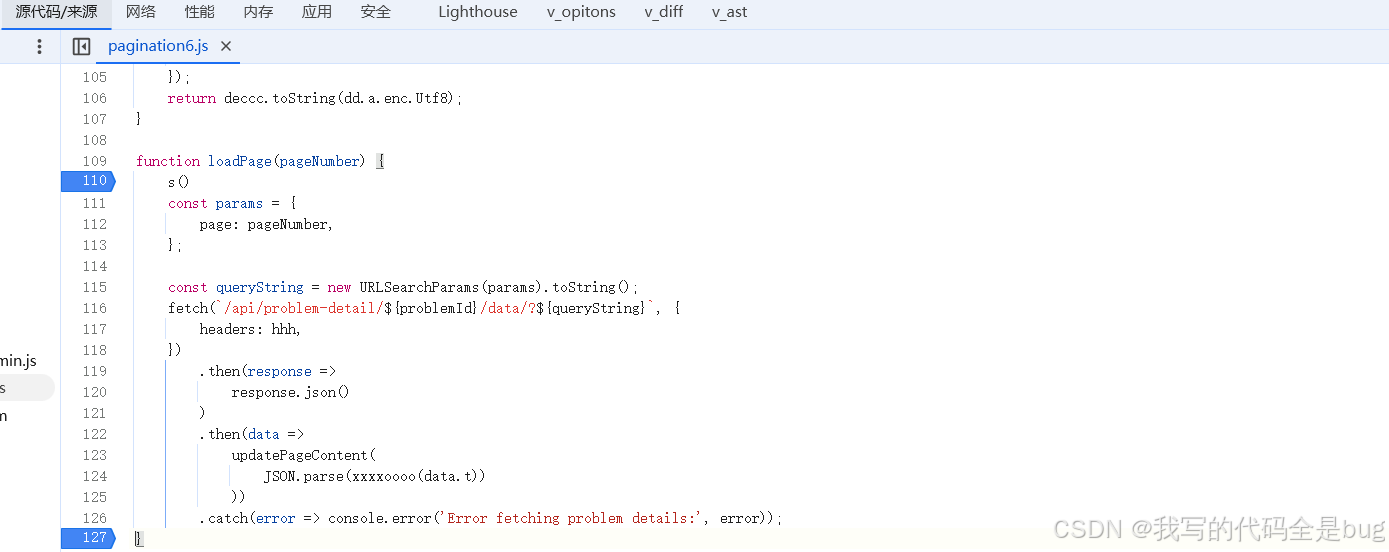

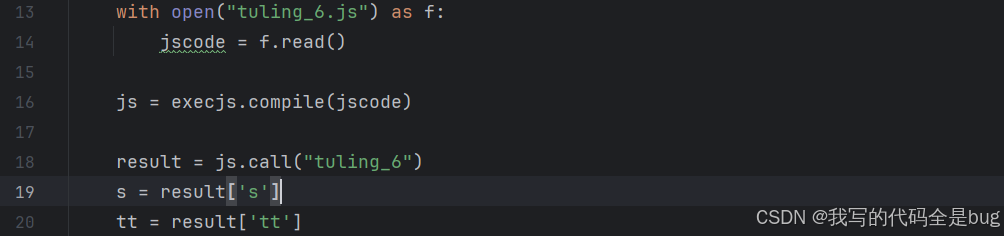
直接复制里面的js内容,测试函数
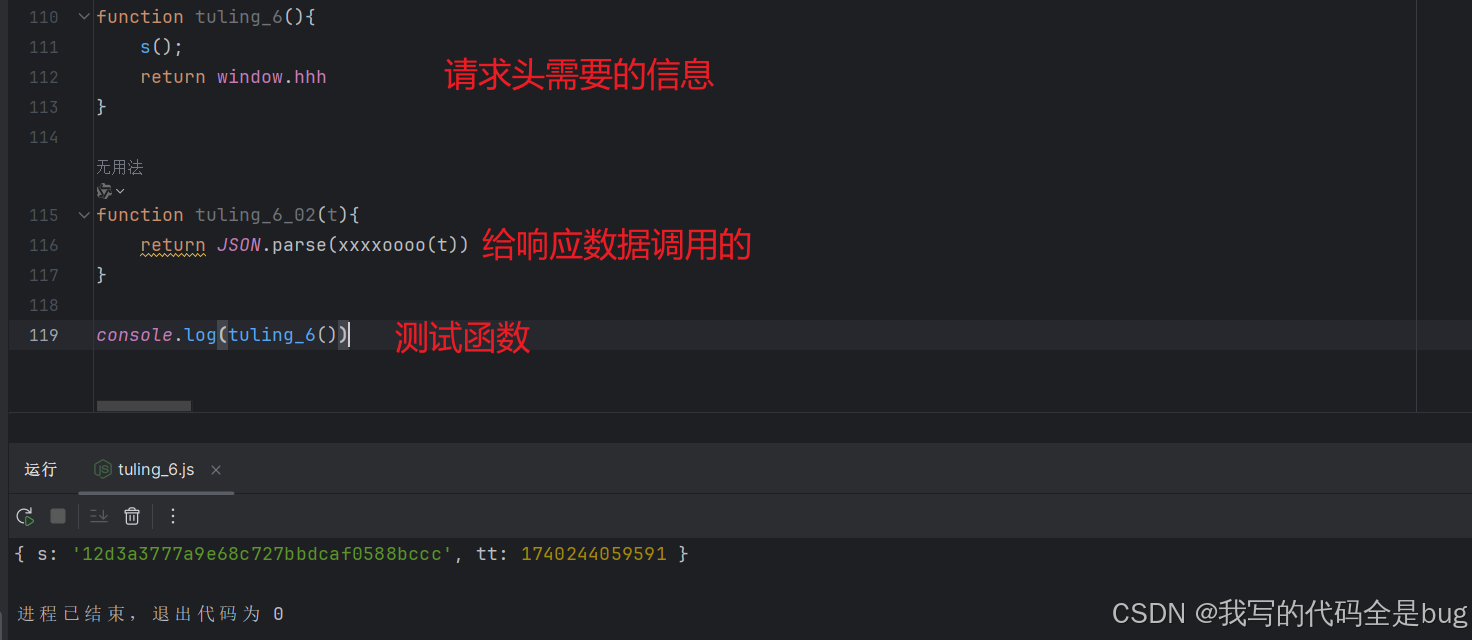
构造请求头,求出关键参数
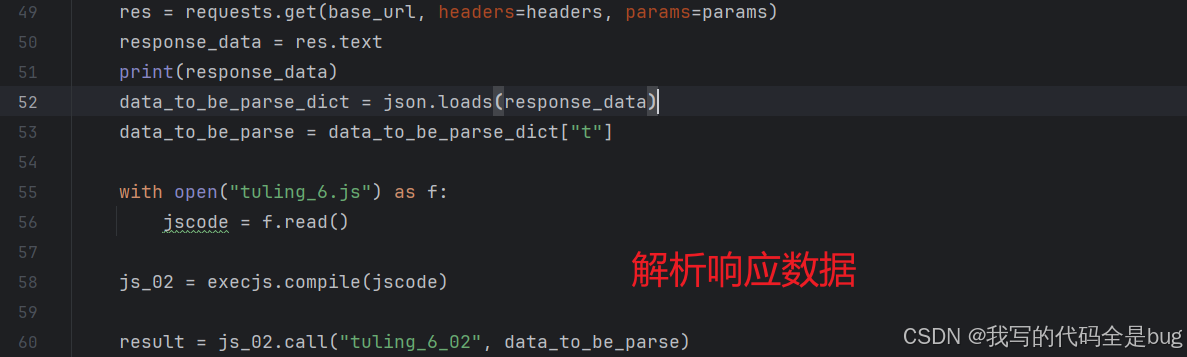
解析响应数据
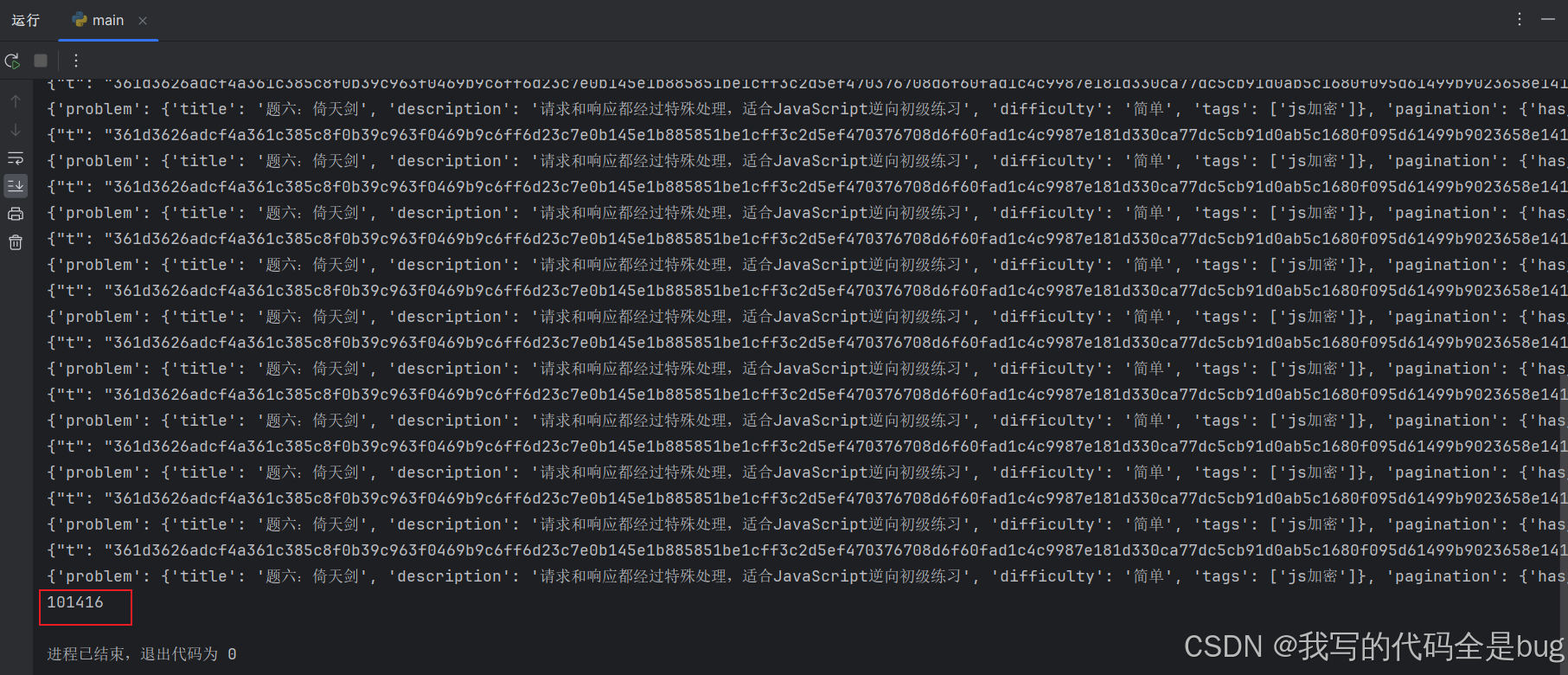
运行得到结果

地址:aHR0cHM6Ly9zdHUudHVsaW5ncHl0b24uY24vcHJvYmxlbS1kZXRhaWwvNi8=
查看启动器
开始断点调试
直接复制里面的js内容,测试函数
构造请求头,求出关键参数
解析响应数据
运行得到结果
 1852
1867
1136
1852
1867
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























