







Python包和模块
当使用Python编程时,包(Packages)和模块(Modules)是两个关键的概念,它们有助于组织、管理和复用代码。
模块(Modules)
什么是模块
1.一个.py 文件就是一个模块
2.模块是含有一系列数据,函数,类等的程序
①作用
- 把相关功能的函数等放在一起有利于管理,有利于多人合作开发
②模块的分类
模块名如果要给别的程序导入,则模块名必须是 标识符
- 内置模块(在python3 程序内部,可以直接使用)
- 标准库模块(在python3 安装完后就可以使用的 )
- 第三方模块(需要下载安装后才能使用)
- 自定义模块(用户自己编写)
3.实例
## file: mymod.py
'''
小张写了一个模块,内部有两个函数,两个字符串
... 此处省略 200字
'''
name1 = 'audi'
name2 = 'tesla'
def mysum(n):
'''
此函数用来求和
by weimingze
'''
print("正在计算, 1 + 2 + 3 + .... + n的和 ")
def get_name():
return "tarena"调用模块
## file: test_mod.py
## 小李写的程序,小李想调用 小张写的 mymod.py 里的两个函数和两个字符串
## 用import 语句导入模块
import mymod
print(mymod.name1) # Audi
print(mymod.name2) # tesla
mymod.mysum(100) # 调用 mymod 模块里的 mysum 函数
print(mymod.get_name()) # 'tarena'导入模块
1.语法
-
import 模块名 [as 模块新名字1]
导入一个模块到当前程序
# 同包
# 在同一个package中导入模块,可以省略掉packa名字
# import demo01 as de
import demo01
if __name__ == '__main__':
c = demo01.add(1,2)
print(c) # 3
#异包
# 如果要引用的模块不在当前package下面,则导入时需要加上package名
import python_demo.demo01 as demo01
if __name__ == '__main__':
c = demo01.add(1,2)
print(c) # 3-
from 模块名 import 模块属性名 [as 属性新名]
导入一个模块内部的部分属性到当前程序
# 同包
# 在同一个package下通过from 模块名 import 模块导入
from demo01 import add
if __name__ == '__main__':
c = add(1,2)
print(c)
#异包
# 跨package导入模块,格式:from 包名 import 模块名
from python_demo import demo01
if __name__ == '__main__':
demo01.add(1,2)
# 格式: from 包名。模块名 import 模块属性
from python_demo.demo01 import add
if __name__ == '__main__':
add(1,2)-
from 模块名 import *
导入一个模块内部的全部属性到当前程序
# 同包
# 在同一个package下通过from 模块名 import *导入, *表示模块的全部属性
from demo01 import *
if __name__ == '__main__':
c = add(1,2)
print(c)
#异包
#格式:from 包名。模块名 import *, *表示所有的模块属性
from python_demo.demo01 import *
if __name__ == '__main__':
add(1,2)2.示例
import mymod
mymod.mysum(10) # 要加模块名
from mymod import get_name
print(get_name()) # 调用get_name 时不需要加 "模块名."
from mymod import *
print(get_name())
print(name2)3.模块的内部属性
(1)__file__ 绑定模块的路径 (2)__name__ 绑定模块的名称 如果是主模块(首先启动的模块)则绑定 '__main__' 如果不是主模块则 绑定 xxx.py 中的 xxx 这个模块名
4.模块的 __name__ 属性
(1)每个.py 模块文件都会有 __name__ 属性
- 当一个模块是最先运行的模块,则这个模块是主模块, 主模块的
__name__属性绑定'__main__'字符串 - 如果一个模块是用 三种 import 语句中的一个导入的模块,则此模块不是主模块。
- 不是主模块的模块的
__name__绑定的 模块名
5.主模块 (__name__ == '__main__'): 当一个模块是直接运行的,即不是通过 import 语句导入的,那么它的 __name__ 属性会被赋值为 '__main__'。
- 例如:
# main_module.py
if __name__ == "__main__":
print("This is the main module.")- 如果运行
python main_module.py,输出将是:
This is the main module.6.被导入的模块 (__name__ == 模块名): 当一个模块被导入到另一个模块中时,它的 __name__ 属性会被赋值为它的模块名。
- 例如:
# imported_module.py
print(f"This module's name is {__name__}") # 被其他模块导入时会自动运行
# main_module.py
import imported_module
if __name__ == "__main__":
print("This is the main module.")- 如果运行
python main_module.py,输出将是:
This module's name is imported_module
This is the main module.这里 imported_module.py 被导入到 main_module.py 中,所以它的 __name__ 是 'imported_module',而 main_module.py 是直接运行的,所以它的 __name__ 是 '__main__'。
7.python 的第三方模块
-
使用导入的模块中的函数、变量等,可以通过模块名或从语句中导入的名称来访问。
Python 常用的内建模块
random 模块
1.先引入random库基础库
import random
| 函数 | 描述 |
|---|---|
| random.choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| random.randrange (start, stop,step) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random.random() | 随机生成下一个实数,它在[0,1)范围内。 |
| random.shuffle(list) | 将序列的所有元素随机排序,修改原list |
| uniform(x, y) | 随机生成实数,它在[x,y]范围内. |
import random
# randrange:根据start、stop和step去生成一个序列,然后从该序列中随机选择一个元素
c = random.randrange(1,11,2)
print(c)
# 从指定的序列中随机选择一个元素
s = random.choice('ABCD')
print(s)
# 随机生成一个0-10的数,结果是实数
d = random.random()*10+5
print(d)
# 将数组的顺序随机打乱
list = [1,2,3,4,5,6,7]
random.shuffle(list)
# [3, 1, 7, 6, 5, 4, 2]
print(list)
# 随机生成一个指定范围的实数
e =random.uniform(0,10)
print(e) # 1.3301289143924666
# 随机生成指定范围的整数
f = random.randint(1,6)
print(f) # 4time 模块
time --- 时间的访问和转换
1.时间戳:从 1970年1月1日 0:0:0 UTC 时间 开始计时到现在的秒数
2.UTC 时间 : 世界协调时间
3.struct_time 用 含有9个元素的元组来表示时间
import time
# 1617117219.0382686
time.time() # 返回当前时间的时间戳
# 'Tue Mar 30 23:14:48 2021'
time.ctime() #返回当前的UTC 时间的字符串
t1 = time.localtime() # 返回当前的本地时间元组
time.struct_time(tm_year=2021, tm_mon=3, tm_mday=30, tm_hour=23, tm_min=18, tm_sec=22, tm_wday=1, tm_yday=89, tm_isdst=0)
"""
t1.tm_year
2021
t1.tm_yday
89
"""
time.sleep(3) # time.sleep(n) # 让程序睡眠 n 秒
# '2021-03-30'
time.strftime("%Y-%m-%d", t1) # 格式化时间
# '21-03-30'
time.strftime("%y-%m-%d", t1)
# '2021-07-21 17:37:41'
time.strftime('%Y-%m-%d %H:%M:%S', t1)
# 用时间元组来创建一个自定义的时间
t2 = time.struct_time ( (2021,1, 1, 10, 11, 20, 0, 0, 0) )datetime 模块
datetime --- 基本日期和时间类型
import datetime
# d1.year
2021
d1 = datetime.datetime.now() # 返回当前的时间
"""
d1.year, d1.month, d1.day, d1.hour, d1.minute, d1.second, d1.microsecond # 用 datetime 的各个属性可以得到 具体的信息
(2021, 3, 30, 23, 32, 44, 757673)
"""
datetime.datetime(2021, 3, 30, 23, 32, 7, 342559)
# '2021-03-30'
d1.strftime("%Y-%m-%d")
## 计算时间差
delta_time = datetime.timedelta(days=2, hours=1) # 生成 2天1小时后的时间差
datetime.timedelta(2, 3600)
t1 = datetime.datetime.now() # 得到当前时间
datetime.datetime(2021, 3, 30, 23, 39, 26, 863109)
t1 + delta_time # 计算 未来时间
datetime.datetime(2021, 4, 2, 0, 39, 26, 863109)os 模块
os 模块
os模块是Python标准库中的一部分,提供了一种与操作系统进行交互的方法。主要功能包括文件和目录的操作、路径处理、进程管理等。在使用os模块之前,我们需要先导入它:
import os
2.举例
#1. os.getcwd(): 获取当前工作目录
import os
current_directory = os.getcwd()
print("当前工作目录:", current_directory)
#2. os.chdir(path): 改变当前工作目录
import os
new_directory = "/path/to/new/directory"
os.chdir(new_directory)
print("工作目录已更改为:", os.getcwd())
#3. os.listdir(path='.'): 返回指定目录下的所有文件和目录列表
import os
directory_path = "."
files_and_dirs = os.listdir(directory_path)
print("指定目录下的文件和目录列表:", files_and_dirs)
#4. os.mkdir(path): 创建目录
import os
new_directory = "new_folder"
os.mkdir(new_directory)
print(f"目录 '{new_directory}' 已创建")
#5. os.rmdir(path): 删除目录
import os
directory_to_remove = "new_folder"
os.rmdir(directory_to_remove)
print(f"目录 '{directory_to_remove}' 已删除")
#6. os.remove(path): 删除文件
import os
file_to_remove = "example.txt"
os.remove(file_to_remove)
print(f"文件 '{file_to_remove}' 已删除")os.path 模块
os.path 模块是 Python 标准库的一部分,专门用于处理文件和目录路径的操作。它提供了一系列函数,用于操作和处理文件路径,使得路径操作更加方便和跨平台。
#1.os.path.basename(path): 返回路径中最后的文件名或目录名
import os
path = "/path/to/some/file.txt"
print(os.path.basename(path)) # 输出: file.txt
#2.os.path.dirname(path): 返回路径中的目录部分
import os
path = "/path/to/some/file.txt"
print(os.path.dirname(path)) # 输出: /path/to/some
#3.os.path.join(*paths): 将多个路径合并成一个路径
import os
path1 = "/path/to"
path2 = "some/file.txt"
full_path = os.path.join(path1, path2)
print(full_path) # 输出: /path/to/some/file.txt
#4.os.path.split(path): 将路径分割成目录和文件名
import os
path = "/path/to/some/file.txt"
print(os.path.split(path)) # 输出: ('/path/to/some', 'file.txt')
#5.os.path.splitext(path): 将路径分割成文件名和扩展名
import os
path = "/path/to/some/file.txt"
print(os.path.splitext(path)) # 输出: ('/path/to/some/file', '.txt')
#6.os.path.exists(path): 检查路径是否存在
import os
path = "/path/to/some/file.txt"
print(os.path.exists(path)) # 输出: True 或 False
#7.os.path.isfile(path): 检查路径是否是文件
import os
path = "/path/to/some/file.txt"
print(os.path.isfile(path)) # 输出: True 或 False
#8.os.path.isdir(path): 检查路径是否是目录
import os
path = "/path/to/some/directory"
print(os.path.isdir(path)) # 输出: True 或 False包(Packages)
包的定义和作用
1.定义
- 包是将模块以文件夹的组织形式进行分组管理的方法,以便更好地组织和管理相关模块。
- 包是一个包含一个特殊的
__init__.py文件的目录,这个文件可以为空,但必须存在,以标识目录为Python包。 - 包可以包含子包(子目录)和模块,可以使用点表示法来导入。
2.作用
- 将一系列模块进行分类管理,有利于防止命名冲突
- 可以在需要时加载一个或部分模块而不是全部模块
3.包示例
mypack/
__init__.py
menu.py # 菜单管理模块
games/
__init__.py
contra.py # 魂斗罗
supermario.py # 超级玛丽 mario
tanks.py # 坦克大作战
office/
__init__.py
excel.py
word.py
powerpoint.py导入包和子包
1.使用import关键字可以导入包和子包,以访问其中的模块和内容。
# 同模块的导入规则
import 包名 [as 包别名]
import 包名.模块名 [as 模块新名]
import 包名.子包名.模块名 [as 模块新名]
from 包名 import 模块名 [as 模块新名]
from 包名.子包名 import 模块名 [as 模块新名]
from 包名.子包名.模块名 import 属性名 [as 属性新名]
# 导入包内的所有子包和模块
from 包名 import *
from 包名.模块名 import *使用包和子包
1.使用导入的包和模块的内容,可以通过包名和点表示法来访问。
2.参考案例
# 使用包中的模块
import pandas as pd
data_frame = pd.DataFrame()
# 使用子包中的模块
from tensorflow.keras.layers import Denseinit.py文件
1.init.py 文件的主要作用是用于初始化Python包(package)或模块(module),它可以实现以下功能:
- 标识包目录: 告诉Python解释器所在的目录应被视为一个包或包含模块的包。没有这个文件,目录可能不会被正确识别为包,导致无法导入包内的模块。
- 执行初始化代码: 可以包含任何Python代码,通常用于执行包的初始化操作,如变量初始化、导入模块、设定包的属性等。这些代码在包被导入时会被执行。
- 控制包的导入行为: 通过定义 all 变量,可以明确指定哪些模块可以被从包中导入,从而限制包的公开接口,防止不需要的模块被导入。
- 提供包级别的命名空间: init.py 中定义的变量和函数可以在包的其他模块中共享,提供了一个包级别的命名空间,允许模块之间共享数据和功能。
- 批量导入模块: 可以在 init.py 文件中批量导入系统模块或其他模块,以便在包被导入时,这些模块可以更方便地使用。
2.以下是一个简单的 init.py 文件的代码示例,演示了上述功能的使用:
# __init__.py 文件示例
# 1. 批量导入系统模块
import os
import sys
import datetime
# 2. 定义包级别的变量
package_variable = "This is a package variable"
# 3. 控制包的导入行为
__all__ = ['module1', 'module2']
# 4. 执行初始化代码
print("Initializing mypackage")
# 注意:这个代码会在包被导入时执行
# 5. 导入包内的模块
from . import module1
from . import module2在这个示例中,init.py 文件用于批量导入系统模块、定义包级别的变量、控制包的导入行为、执行初始化代码,以及导入包内的模块。这有助于包的组织、初始化和导入管理。
第三方包
Python第三方包是由Python社区开发的,可用于扩展Python功能和解决各种问题的软件包。这些包提供了各种各样的功能,包括数据分析、机器学习、网络编程、Web开发、图形处理、自然语言处理等。
安装和使用
1.使用pip:pip是Python的包管理工具,用于安装、升级和管理第三方包。确保你的Python安装中包含了pip。
2.安装第三方包:
- 使用pip安装包:在命令行中运行以下命令来安装包,将"package-name"替换为要安装的包的名称。
pip install package-name
- 安装特定版本的包:如果你需要安装特定版本的包,可以使用以下命令:
pip install package-name==version
- 通过镜像安装,可以使用以下命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package1 package2 package3 ...
- 从requirements文件安装:你可以将要安装的包及其版本记录在一个文本文件中,通常命名为requirements.txt,然后运行以下命令安装其中列出的所有包:
pip install -r requirements.txt
3.导入包:在Python脚本或交互式环境中,使用import语句导入已安装的包,以便在代码中使用它们。
import package_name
4.使用包:每个第三方包都有不同的用法和功能,通常伴随着官方文档和示例代码。你可以查阅官方文档,或者使用help()函数来了解包的功能和方法。示例:
import package_name help(package_name)
5.更新和卸载包:
- 更新包:使用以下命令来更新已安装的包:
pip install --upgrade package-name
- 卸载包:如果你想卸载包,可以使用以下命令:
pip uninstall package-name
依赖清单
可以使用pipreqs来维护requirements.txt文件,以便轻松地重建环境。
pipreqs是一个用于管理Python项目依赖清单的工具,它会自动分析项目代码,并生成requirements.txt文件,列出项目所需的所有依赖包及其版本。以下是使用pipreqs管理依赖清单的步骤:
1.安装pipreqs
- 镜像安装
pip install pipreqs -i https://pypi.tuna.tsinghua.edu.cn/simple
- 如果你还没有安装
pipreqs,可以使用pip安装它(比较慢,可能会丢包):
pip install pipreqs
2.在项目目录中运行pipreqs
- 进入你的项目目录,然后运行以下命令:
pipreqs .
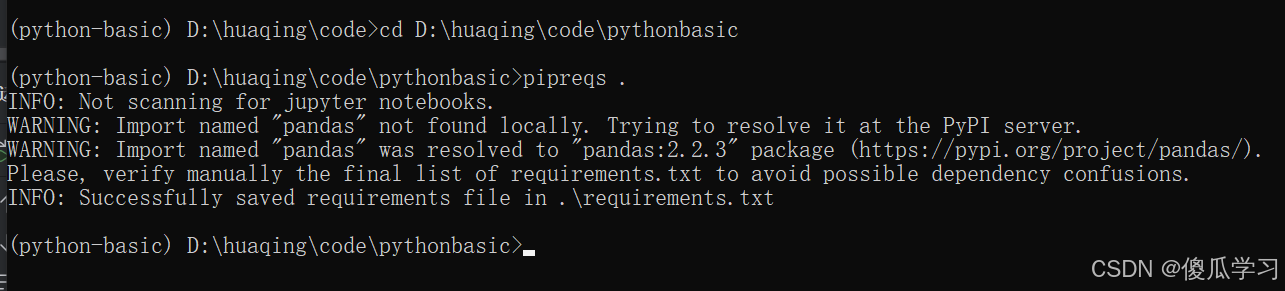
这会分析项目代码,并在当前目录下生成一个名为requirements.txt的文件,其中包含了项目所需的所有依赖包及其版本。
如果遇到编码错误UnicodeDecodeError,则将指定编码为utf8:
pipreqs ./ --encoding=utf8 pipreqs ./ --encoding=gbk pipreqs ./ --encoding='iso-8859-1'
3.查看生成的requirements.txt文件
- 打开
requirements.txt文件,你将看到列出的依赖包及其版本,类似于以下内容:
package1==1.0.0 package2==2.1.3 ...
4.选择是否要修改requirements.txt文件
pipreqs生成的requirements.txt文件可能包含一些不必要的依赖,或者可能需要手动指定特定版本。
你可以编辑requirements.txt文件,根据项目的需要添加、删除或修改依赖项。
-
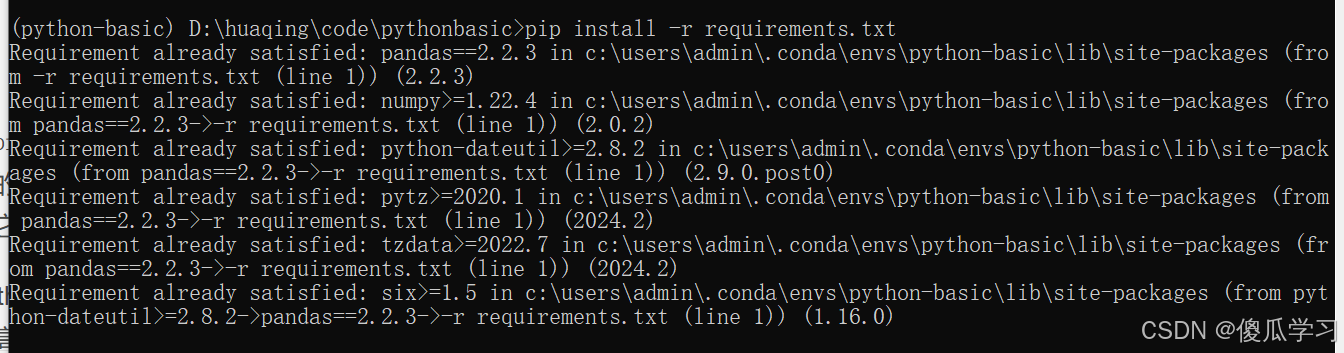
安装依赖:
一旦你准备好了
requirements.txt文件,你可以使用pip来安装项目的依赖:pip install -r requirements.txt
-
定期更新依赖:
定期使用
pipreqs重新生成requirements.txt文件,以确保依赖清单保持最新。你可以使用以下命令:pipreqs .
pipreqs是一个方便的工具,它可以帮助你自动创建和维护项目的依赖清单。不过,需要记住,生成的依赖清单可能包含一些不必要的依赖,因此你应该仔细检查和编辑requirements.txt文件以确保它反映了项目的真实需求。
Python的包和模块是组织、管理和重用代码的重要工具。它们有助于将代码划分为可管理的单元,提高了代码的可读性和可维护性。通过模块和包,你可以更有效地组织项目,减少命名冲突,以及在不同项目之间重用代码,从而更轻松地进行Python编程。通过上述参考案例,你可以更好地理解如何在实际项目中应用这些概念。
Python异常
-
作用
用作信号通知,通知上层调用者有错误产生需要处理
try 语句
1.语法
try:
可能发生异常的语句块
except 错误类型1 [as 变量名1]:
异常处理语句块1
except 错误类型2 [as 变量名2]:
异常处理语句块2
...
except 错误类型n [as 变量名n]:
异常处理语句块n
except:
异常处理语句块other
else:
未发生异常的语句
finally:
最终的处理语句2.作用:尝试捕获异常,得到异常通知,将程序由异常状态变为正常状态
3.说明
- except 子句可以有 1个或多个
- except: 不给错误类型,可以匹配全部的错误类型
- else 子句里的语句会在 没有错误发生时执行,当处于异常时不执行
- finally 子句里的语句,无论何时都执行
4.示例
# try except:
# try模块中可能会出现异常的代码
# except:如果try模块中的代码执行出现异常,则由except模块捕获,并处理异常
# fianlly:不管try模块中的代码是否发生异常,都会执行
def exception_test():
try:
b = 1/0
except ZeroDivisionError as e:
print(f"除数不能为0:{e}")
finally:
print('run finally')
if __name__ == '__main__':
exception_test()
raise 语句
1.语法
raise 异常类型
或
raise 异常对象2.作用
- 抛出一个错误,让程序进入异常状态
- 发送错误通知给调用者
3.示例:
# raise:在代码出现异常的时候,向外抛异常信息
# 先判断代码中是否会出现异常,如果会出现,则向外抛异常,三思而后行
# try不判断代码是否出现异常,当代码出现异常的时候,去通过except捕获,先执行在捕获
def raise_test(a,b):
if b == 0:
raise Exception('除数不能为0')
return a / b
if __name__ == '__main__':
raise_test(2,0)4.异常类型的可选种类
Python全部的错误类型
| 错误类型 | 说明 |
|---|---|
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| ValueError | 传入无效的参数 |
| AssertionError | 断言语句失败 |
| StopIteration | 迭代器没有更多的值 |
| IndexError | 序列中没有此索引(index) |
| IndentationError | 缩进错误 |
| OSError | 输入/输出操作失败 |
| ImportError | 导入模块/对象失败 |
| NameError | 未声明/初始化对象 (没有属性) |
| AttributeError | 对象没有这个属性 |
| <!-- 以下不常用 --> | |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| TypeError | 对类型无效的操作 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| OverflowError | 数值运算超出最大限制 |
| FloatingPointError | 浮点计算错误 |
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| Exception | 常规错误的基类 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| WindowsError | 系统调用失败 |
| LookupError | 无效数据查询的基类 |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError Python | 语法错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| 以下为警告类型 | |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
详见:help(builtins)
Python文件操作
文件操作是Python中常见的任务之一,用于创建、读取、写入和管理文件。以下是一些常见的文件操作任务的思路、总结和示例代码:
打开文件
要执行文件操作,首先需要打开文件。使用open()函数可以打开文件,指定文件名以及打开模式(读取、写入、追加等)。
# 打开一个文本文件以读取内容
file = open("example.txt", "r")读取文件
一旦文件被打开,可以使用不同的方法来读取文件内容。
# 读取整个文件内容
content = file.read()
# 逐行读取文件内容
for line in file: #直接遍历文件对象,每次读取一行。这种方式更内存友好,因为不需要将所有行读入内存。
print(line)
with open('example.txt', 'r') as file:
lines = file.readlines() # 读取文件的所有行,并将其作为一个列表返回。
for line in lines:
print(line, end='') 代码和file = open("example.txt", "r")for line in file:
print(line) 代码的区别写入文件
要写入文件,需要打开文件以写入模式('w'),然后使用write()方法。
# 打开文件以写入内容
file = open("example.txt", "w")
# 写入内容
file.write("这是一个示例文本。")关闭文件
完成文件操作后,应该关闭文件,以释放资源和确保文件的完整性。
file.close()使用with
更安全的方法是使用with语句,它会自动关闭文件。
with open("example.txt", "r") as file:
content = file.read()
# 文件自动关闭检查是否存在
可以使用os.path.exists()来检查文件是否存在。
import os
if os.path.exists("example.txt"):
print("文件存在")处理异常
在文件操作中,可能会出现各种异常情况,例如文件不存在或没有权限。在文件操作中捕获这些异常是个好习惯。
try:
with open("example.txt", "r") as file:
content = file.read()
except FileNotFoundError:
print("文件不存在")
except Exception as e:
print(f"发生错误:{e}")这些是文件操作的一些常见思路和示例代码。请根据你的具体需求和场景来调整代码。在进行文件操作时,要确保小心处理文件,以避免意外数据损坏或文件损坏。
除了打开、读取和写入文件之外,还有一些其他常见的文件操作,如复制、删除和改变文件名。以下是这些操作的思路和示例代码:
复制文件
要复制文件,你可以使用shutil模块的copy方法。
import shutil
source_file = "source.txt"
destination_file = "destination.txt"
shutil.copy(source_file, destination_file)删除文件
要删除文件,可以使用os模块的remove方法。
import os
file_to_delete = "file_to_delete.txt"
if os.path.exists(file_to_delete):
os.remove(file_to_delete)
print(f"{file_to_delete} 已删除")
else:
print(f"{file_to_delete} 不存在")修改名称
要改变文件名,可以使用os模块的rename方法。
import os
old_name = "old_name.txt"
new_name = "new_name.txt"
if os.path.exists(old_name):
os.rename(old_name, new_name)
print(f"文件名已更改为 {new_name}")
else:
print(f"{old_name} 不存在")例子
import os
import shutil
def file_test():
f = open('test.txt', 'r+')
print(f)
# print(f.read())
# 123
# print(f.readline())
#
# # 1 一行数据的第一个数据,第二次运行,读到了第二行
# print(f.readline(1))
"""
123
qwe
asd
"""
line = f.readline()
while line:
print(line)
line = f.readline()
# 文件写入
s = 'axc'
# axc 上面的遍历结果暂时就没有了,不能读出来,因为文件在进行改变
f.write(s) #报错,不支持写,该权限,w+不能产看,r+才可以看到写入的结果,但还是没有全部的结果
with open('test.txt', 'r') as f:
print(f.read())
shutil.copy('test.txt', 'test1.txt')
os.remove('test1.txt')
if __name__ == '__main__':
file_test()Python JSON 数据解析
JSON(JavaScript Object Notation)是一种轻量级数据交换格式,它易于阅读和编写,同时也易于机器解析和生成。Python提供了内置的JSON模块,用于处理JSON数据。
导入模块
import json
序列化
# json结构:以一对花括号作为开始和结尾,花括号中的内容(其中的数据格式)为key:value,多个键值对之间用英文逗号分隔
# json是以键值对(key:value)来组成的,key必须是字符串类型,value可以是任意类型
# json一旦生成json字符串后不能修改,如果要修改,需要反序列化(loads)为字典对象进行修改
import json
data = {
"name": "John",
"age": 30,
"city": "New York"
}
json_str = json.dumps(data) # json.dumps() 是 Python 的 json 模块中的一个函数,它的作用是将 Python 对象转换为 JSON 格式的字符串。
print(json_str)反序列化
json_str = '{"name": "John", "age": 30, "city": "New York"}'
data = json.loads(json_str) # json.loads() 是 Python json 模块中的一个函数,它的作用是将 JSON 格式的字符串转换为 Python 对象。
print(data)对象存文件
# 读取文件
# load:从文件中读取json,文件需要先打开
# dump和load是做json文件读写,dumps和loads是做json的序列化和反序列化
data = {
"name": "John",
"age": 30,
"city": "New York"
}
with open('data.json', 'w') as json_file:
json.dump(data, json_file)
#或者
json.dump(data, open('data.json', 'w'))从文件加载
with open('data.json', 'r') as json_file:
data = json.load(json_file)
print(data)嵌套JSON数据
如果JSON数据包含嵌套结构,您可以使用递归来访问和修改其中的值。
json_data = {
"name": "Alice",
"info": {
"age": 25,
"location": "Paris"
}
}
# 获取嵌套的值
age = json_data["info"]["age"]
# 修改嵌套的值
json_data["info"]["location"] = "New York"
# 将更改后的数据转换为JSON字符串
new_json_str = json.dumps(json_data)JSON中列表
JSON可以包含列表,可以使用索引来访问列表元素。
json_data = {
"fruits": ["apple", "banana", "cherry"]
}
# 获取列表中的第一个水果
first_fruit = json_data["fruits"][0]
# 添加一个新水果到列表
json_data["fruits"].append("orange")JSON中空值
JSON允许表示空值(null),在Python中,它通常转换为None。
# 在定义json空值时需要指定为None
json_data = {
"value": None
}
# 转换为json对象后,空值自动转换为null
print(json.dumps(json_data))
# 输出:
# {"value": null}字典和JSON格式不同之处
(1)数据类型限制:
- JSON:支持的数据类型包括对象(类似于字典)、数组(类似于列表)、字符串、数字、布尔值和 null。JSON 不支持 Python 特有的数据类型如 tuple、set、bytes 等。
- Python 字典:可以包含多种 Python 特有的数据类型,比如 tuple、set、bytes 等。
(2)格式要求:
- JSON:数据必须以字符串的形式表示,键必须是双引号括起来的字符串,值可以是字符串、数字、布尔值、数组、对象或 null。
- Python 字典:键可以是任意不可变的类型(如字符串、数字、元组),值可以是任意类型。键通常用单引号或双引号括起来,但 Python 允许在字典中使用不加引号的键。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









