






Transformer的结构
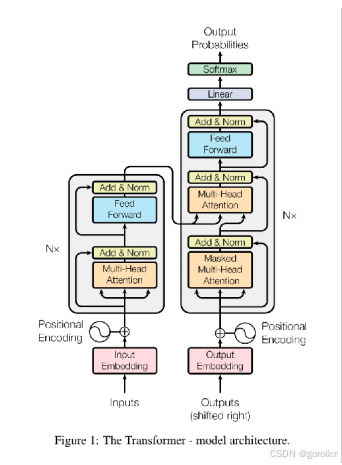
老生常谈的图片哈。
左侧Encoder部分,右侧decoder部分。一个容易误解的点就是:下意识地认为数据从encoder进decoder出——实际上在模型学习过程中,总要有x(问题)和y(指标)的输入,这样才能让网络在知道问题和答案的情况下推理中间的逻辑过程(参数学习),而实际的输出应该是encoder和decoder交叉注意完最后从softmax输出的logits,它是这个模型最终推理的结果,不过在训练过程中既然知道答案那就输出答案就行了
encoder内部有多层,包括对于encode input的自注意力操作(提取左侧输入特征)和逐点卷积升维提取高维特征层
decoder也一样,先mask自注意力防作弊地提取右侧输入特征,下一层交叉注意力提取左右对应特征(其实我个人倾向于把交叉提取特征这块单独拿出来放在即将输出部分而不是在decoder里面)。最后进行一个常规的卷积就可以开始输出了
至于每层都会出现的add&norm,是残差、正则化,它保证了每一层的输出值维持在一个稳定而仍具有明显特征的范围内,防止梯度爆炸
重点技术细节(按顺序来)
1.词索引化
根据词表将一个句子化作向量:比如i love you化成[0, 1, 2]。具体索引当然根据你怎么向量化怎么设计词库来了,这个就自己去研究吧
2.词嵌入
在nlp领域干啥你都得先把得来的新向量融入你的高维语义空间里,这样才能统一维度进行运算。至于向量是怎么在空间里表示词意的,自己去研究理解吧。总之就是大家先统一度量衡,一会方便行动
3.postionencode
这是transformer的一大重点。如果说前面词嵌入是让你的词在高维空间有了语义表示,那么这里的位置编码则是让你的input内的词各自有了联系,就像告诉了网络:i 是 love的主语,you 是love的目标...。
在这里除了常见的三角函数编码外,也会有自学习的编码情况,不过固定的三角函数编码已经有良好的表现了
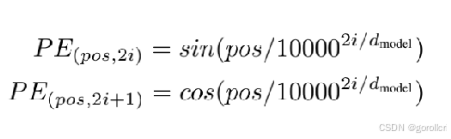
4.attention mask
前面没有提到,在transformer中处理token需要让token等长,也就是说,短的补长的截,这里就要引入一个pad mask概念——没必要让网络注意那个没意义的填充部分,所以用个mask让他别看就好了
5.注意力机制
有一个重点的attention量化公式
经典的QKV。首先Q是query矩阵,产生自decoder(意在产生问题:哪个词我比较关注?)K、V分别是键key矩阵和value值矩阵,他们都来自encoder,是encoder完成特征提取后得出的结果。那么有了这三个东西,就可以量化attention得分,用矩阵来表示词词之间谁在乎谁。
在代码实现中,理解QKV空间的投影以及一些计算其实是一个有点困难的事情
class MultiHeadAttention(nn.Module): def __init__(self): super(self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads) self.W_K = nn.Linear(d_model, d_k * n_heads) self.W_V = nn.Linear(d_model, d_v * n_heads) self.linear = nn.Linear(n_heads * d_v, d_model) self.layer_norm = nn.LayerNorm(d_model) def forward(self, Q, K, V, attn_mask): residual, batch_size = Q, Q.size(0) q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k] k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k] v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask) context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) output = self.linear(context) return self.layer_norm(output + residual), attn
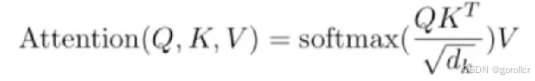
5.单、多头注意力机制
transformer的重点。多头注意力机制是针对token内多特征进行矩阵展开,比如我说我今天生病了,去药店买药听到一个八卦,A会在意我听到了什么八卦而B会在意我生病了,所以多头注意力就能够更加全面的捕捉到句子中各个方面的特征,将他们的注意力产生结果进行一个和计算那么就会获得一个尤其全面的句子理解。这里的多个头计算也是一个难以理解的知识点
6.decoder层为什么要mask?
因为decoder要产生Q矩阵,相当于他在进行测试考验,他当然不能提前预知下个位置的词,所以运用了一个上三角机制,将decoder的自注意力限制在每个词对它之前的词的了解,而非之后的
本文是偏大白话的transformer结构和一些细节的介绍,并不能当做transformer的完整学习内容,该去啃代码还得去啃,尤其是QKV计算和注意力机制的理解,是非常重要的部分


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









