







一、Python爬虫
Python爬虫是一种使用 Python 编程语言实现网络数据爬取的工具。Python 爬虫可以通过访问网页、解析 HTML、提取数据和保存数据等步骤来自动化地收集网络上的信息。它由调度器、URL管理器、网页下载器、网页解析器以及应用程序组成。
二、爬取us news大学排名
import pandas as pd
import requests
from bs4 import BeautifulSoup
# 搭建数据爬取环境
url='https://www.compassedu.hk/usnews'
r=requests.get(url)
print(r)
r.encoding=('UTF-8')
#防止产生乱码
htmls=r.content
#提取网页内容
soup=BeautifulSoup(htmls,'lxml')
#lxml进行网页解析
soup
# 然后使用BeautifulSoup4进行解析
n=soup.find_all("div",attrs={'class':'cname line-one'})
n
name=[]
for i in soup.find_all('div',attrs={'class':'cname line-one'}):
name.append(i.getText())
name
#读取学校名称
rank=[]
for i in soup.find_all("div",attrs={'class':'rank-tr1'}):
if i.getText().isdigit():
rank.append(i.getText())
#读取学校排名
us_news_ranking={'排名':rank,'学校名称':name}
us_news_ranking=pd.DataFrame(us_news_ranking)
us_news_ranking问题:报错ValueError: All arrays must be of the same length
问题解释:网络搜索发现为使用DataFrame(dict) 来用dict构建DataFrame时,key会变成列column,(list-like)values会变为行row,每个values中的list长度不一致,就会产生这个错误。
方法:对代码一段一段运行,发现在读取排名时将排名一起读入,导致输出时rank格式不统一,对比HTML中两个描述的不同点,将其修改为唯一特征
理解:这种Python读取对单组,在网页编程中有唯一特征代码有用,对无唯一特征代码的数据抓取没有作用,大量抓取多组目标代码量较大。
三、京东李子柒螺蛳粉评论
import requests
#请求和页面抓取
import time
#设置抓取Sleep时间
import random
#生成乱序随机数
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import jieba as jb
#关键词提取
import jieba.analyse
import csv
from pprint import pprint
for page in range(0,20):
print(f'正在采集第{page}页的内容')
url='https://api.m.jd.com/'
#网站地址
data={'appid': 'item-v3',
'functionId': 'pc_club_productPageComments',
'client':' pc',
'clientVersion': '1.0.0',
't': '1712929370430',
'loginType':'3',
'uuid': '181111935.667197733.1712929254.1712929254.1712929255.1',
'productId': '10077305381360',
'score':'0',
'sortType': '5',
'page': page,
'pageSize': '10',
'isShadowSku': '0',
'rid': '0',
'fold': '1',
'bbtf': '',
'shield': ''}
#页面特征
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'}
#设置请求中头文件的信息
response=requests.get(url=url,params=data,headers=headers)
print(response.json())
f=open('李子柒.csv',mode='a',encoding='utf-8-sig',newline='')
#建立李子柒.csv文件
csv_writer=csv.DictWriter(f,fieldnames=['昵称','商品','评分','内容','plus会员'])
csv_writer.writeheader()
#设置表头
for index in response.json()['comments']:
if index['plusAvailable']==201:
vip='是'
else:
vip='否'
dit={'昵称':index['nickname'],'商品':index['productColor'],'评分':index['score'],
'内容':index['content'].replace('\n',''),'plus会员':vip
}
csv_writer.writerow(dit)
#写入内容data部分内容获取
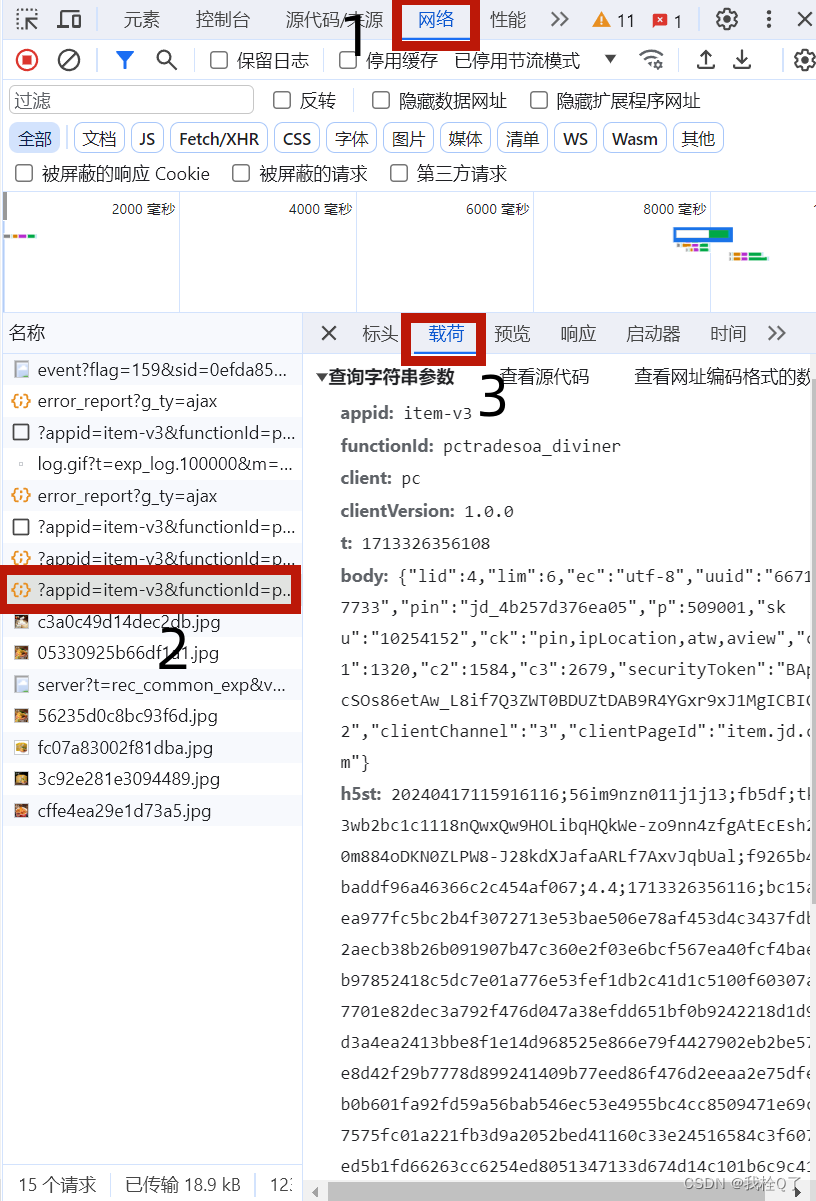
问题:ModuleNotFoundError: No module named 'jieba'
问题解释:没有找到jieba的库
方法一:将编译器Python版本与电脑环境Python版本一致
结果:失败,错误不变
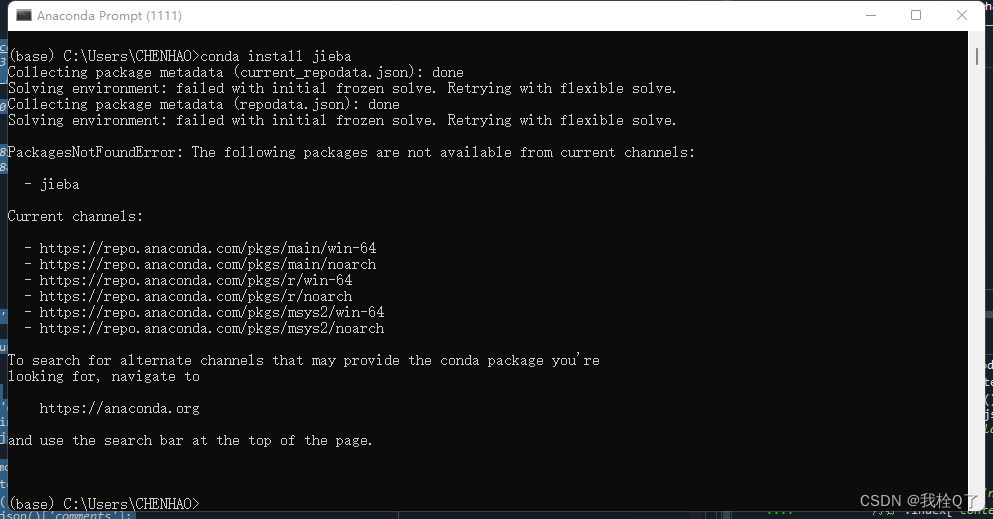
方法二:在Anacond Prompt中输入代码conda install jieba
conda install jieba结果:无法正常运行
方法三:在cmd中输入代码 pip install jieba下载jiaba库
pip install jieba结果:开始下载,成功后代码成功运行

四、其他学习
本周还进行了英特尔OpenVINO工具套件的安装和官方初级课程的学习,已对该套件有了基础的认识和部分功能的了解


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









