







AdaGrad(Adaptive Gradient Algorithm) 是一种基于参数自适应调整学习率的优化算法,由 John Duchi 等人于 2011 年提出。其核心思想是为每个参数单独调整学习率,以应对不同参数对梯度的敏感性差异,尤其适合解决稀疏数据和深层网络中的优化问题。
1. 核心思想
- 自适应性:根据参数的历史梯度自动调整学习率。
- 稀疏数据友好:在参数更新频率低的场景(如词嵌入)中,能动态放大稀疏梯度的学习率。
- 缓解梯度消失:通过累积梯度平方根调整学习率,避免早期阶段学习率过小。
2. 工作原理
- 维护变量:维护一个累积梯度平方的矩阵 G,初始为全零。
- 更新规则:
- 计算当前梯度 gt。
- 更新累积梯度矩阵:
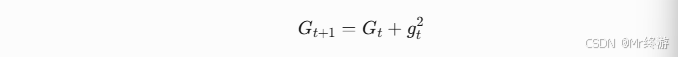
- 参数更新公式:
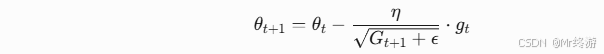
- η:初始学习率。
- ϵ:极小值(防止除以零,如 1e−8)。
- 学习率特点:频繁更新的参数(如深层网络的浅层参数)分母较大,学习率较小;稀疏参数的分母较小,学习率较大。
3. AdaGrad 的优缺点
优点
- 无需手动调参:自动为每个参数分配学习率。
- 适合稀疏数据:在自然语言处理(NLP)等领域效果显著。
- 缓解梯度消失:通过累积梯度调整学习率。
缺点
- 学习率过早衰减:随着训练进行,分母持续增大,学习率趋近于零,可能导致训练停滞。
- 计算复杂度高:维护累积矩阵 G 需要存储所有参数的历史梯度,内存占用较大。
4. 与其他优化算法对比
| 算法 | 特点 | 适用场景 |
|---|---|---|
| SGD | 使用固定学习率,简单但依赖手动调参。 | 简单模型、小数据集 |
| Momentum | 引入动量项加速收敛,减少震荡。 | 大数据集、非凸优化 |
| RMSProp | 改进 AdaGrad,使用指数衰减加权历史梯度,避免学习率过早衰减。 | 深度网络、长期依赖任务 |
| Adam | 结合 Momentum 和 RMSProp 的优点,自适应调整学习率和动量。 | 大多数现代深度学习任务 |
5. 实际应用场景
- 词嵌入(Word Embedding):如 Word2Vec 中处理稀疏词频矩阵。
- 图神经网络(GNN):稀疏邻接矩阵的场景。
- 小批量训练:动态调整学习率以适应不同批次的数据分布。


















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









