







目录
问题四: redis作为缓存,mysql的数据如何redis进行同步?(双写一致性)
业务场景一:那怎么保证双写一致呐?(一致性要求高的业务需求)
业务场景二:延迟一致怎么做?(允许短暂的不一致,实际开发中最为主流的)
编辑 问题六:假设redis的key过期之后,会立即删除吗?(数据过期策略)
问题七: 假如缓存过多,内存是有限的,内存被占满了怎么办?(数据淘汰策略)
1、数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据?
以下问题包括知识点和面试题,看的时候直接看《模拟面试即可》,后续持续更新中。。。
一、项目中哪些地方使用了redis
面试官:我看你做的项目中,都用到了redis,你在最近的项目中哪些场景使用了redis?
一般这个问题要结合自己的实际项目经历回答,面试想这样问:一方面验证你的项目场景的真实性,二是为了作为深入发问的切入点
比如你回答了使用了:(可能会被问道的相关问题或知识点)
缓存:缓存三兄弟(穿透、击穿、雪崩)、双写一致、持久化、数据过期策略、数据淘汰策略
分布式锁:setnx、redisson
消息队列、延迟队列:何种数据类型
问题一:发生了缓存穿透该怎么解决?
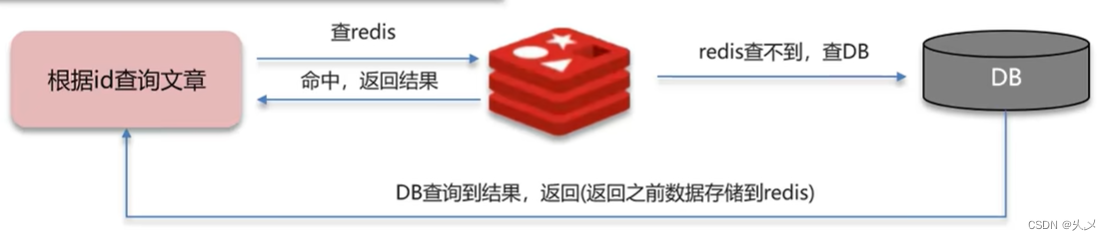
以下是正常使用缓存的流程:
那么什么是缓存穿透呐?
查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都去查询数据库
那为什么会出现这种情况呐?
通常呐,就是有人恶意攻击你的系统,有人知道你的请求路径,知道你的请求参数跟在请求路径后面的,就会制造一些假的id发起请求等等,就会冲击你的数据库,你的数据库的并发是不高的,请求到了一定的量就会击垮数据库。
解决方案:
方案一:缓存空数据
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空数据进行缓存
优点:操作简单
缺点:消耗内存,可能会发生不一致的问题
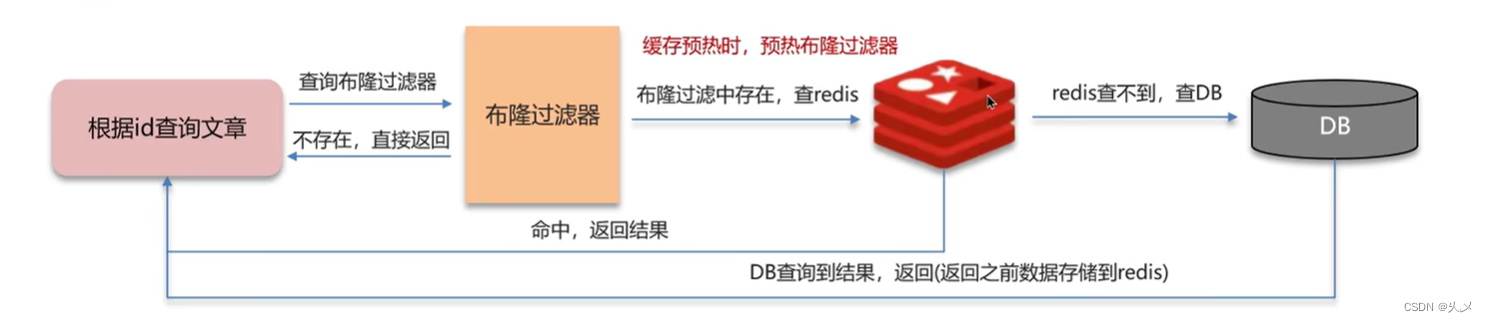
方案二:布隆过滤器
解决方案二:布隆过滤器
优点:内存占用较少,没有多余key缺点:实现复杂,存在误判
布隆过滤器:
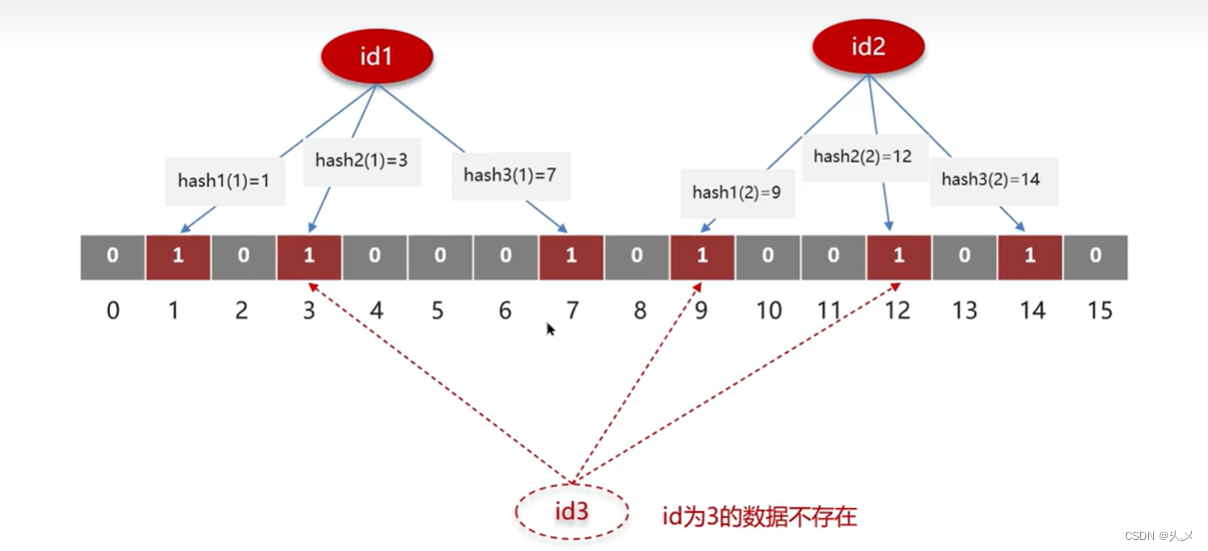
bitmap(位图):相当于一个以(bit)位为单位的数组,数组中每个单元只能存储二进制数0或1
布隆过滤器作用:布隆过滤器可以用于检索一个元素是否再一个集合中。可能产生误判:
误判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多的内存消耗
模拟面试

问题二: 发生了缓存击穿该怎么解决?
什么是缓存击穿?
给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把数据库压垮
 解决方案:
解决方案:
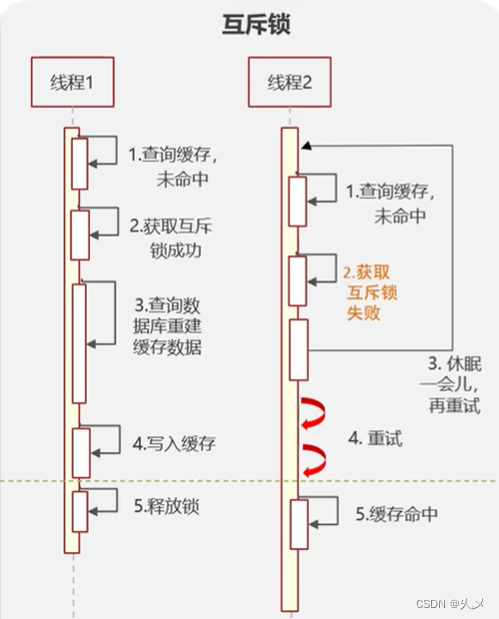
方案一:互斥锁
特点:强一致,性能差
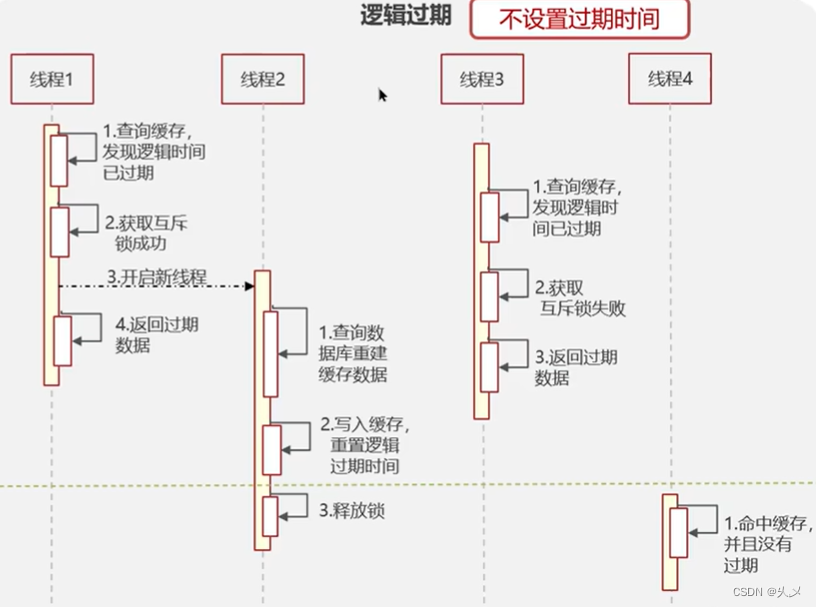
方案二:逻辑过期
特点:高可用、性能优、不能保证数据的绝对一致
模拟面试

问题三: 发生了缓存雪崩该怎么解决?
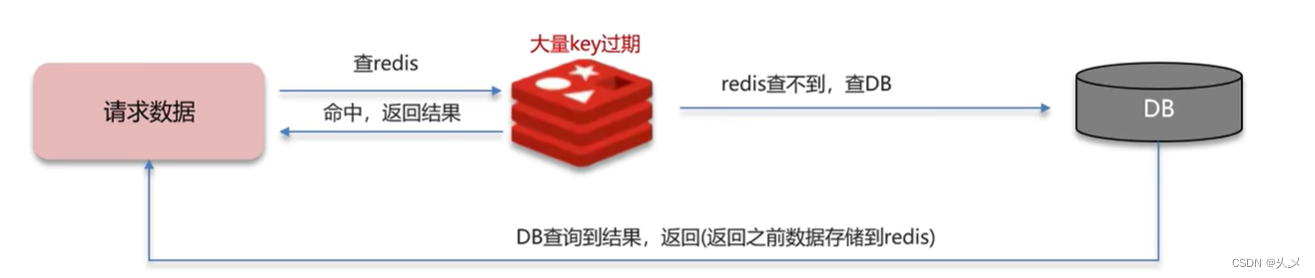
什么是缓存雪崩?
在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
 解决方案:
解决方案:
- 给不同的key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略 (降级可作为系统的保底策略,适用于穿透、击穿、雪崩)
- 给业务添加多级缓存
模拟面试:

问题四: redis作为缓存,mysql的数据如何redis进行同步?(双写一致性)
一定要设置前提,,,结合自己的项目业务背景去讲!!!!
看看到底属于哪一种:是一致性要求高的业务需求,还是说是允许延迟一致?
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致

读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间
写操作:延迟双删

这个时候我们就要考虑是先删除缓存,还是先修改数据库?
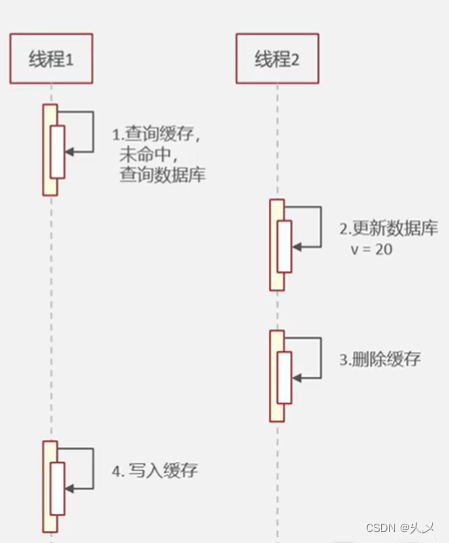
情况一:先删除缓存,再操作数据库
正常情况:
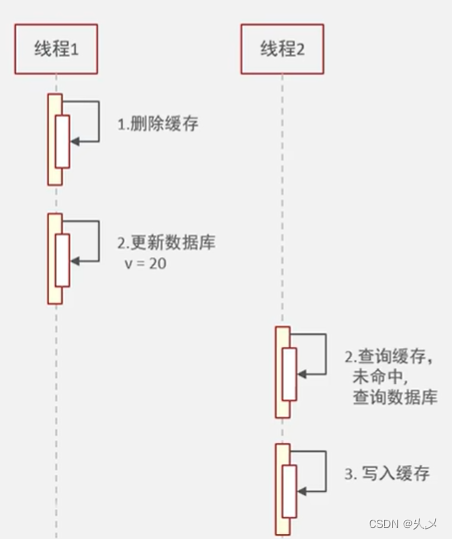
不正常情况:因为线程是交替执行的,这种方式可能会出现脏数据的现象
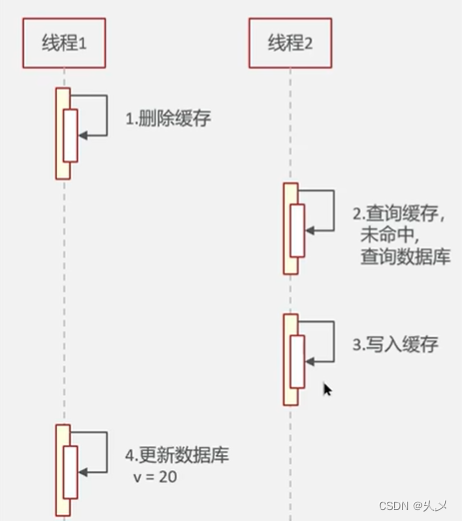
情况二:先操作数据库,再删除缓存
正常情况:
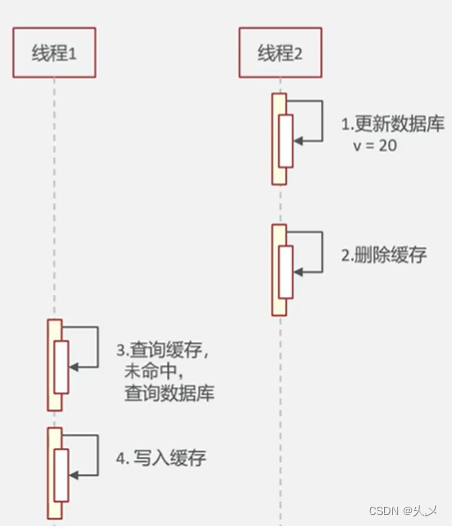
不正常情况:这种方式可能会出现脏数据的现象
那么为什么要删除两次缓存?
降低脏数据的出现
为什么要延时删除?
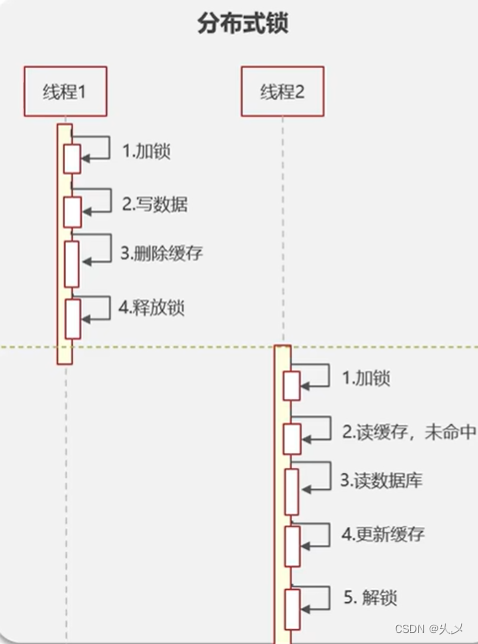
业务场景一:那怎么保证双写一致呐?(一致性要求高的业务需求)
但是这样的话,性能就有点差了
当然我们都是知道的,放入redis的数据一般都是读多写少
所以使用读写锁就可以了
特点:强一致,性能差(强一致性情况下才会使用)
共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
排他锁:独占锁writeLock,加锁之后,阻塞其他线程读写操作
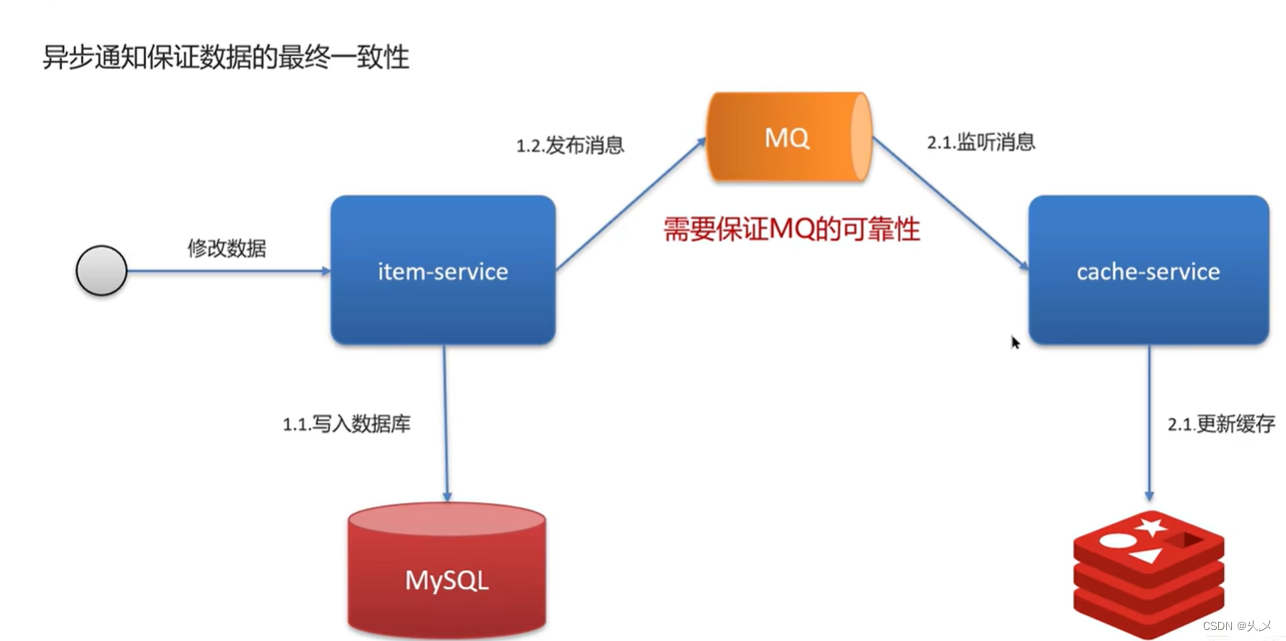
业务场景二:延迟一致怎么做?(允许短暂的不一致,实际开发中最为主流的)
方案一:基于MQ的异步通知
方案二:基于Canal的异步通知
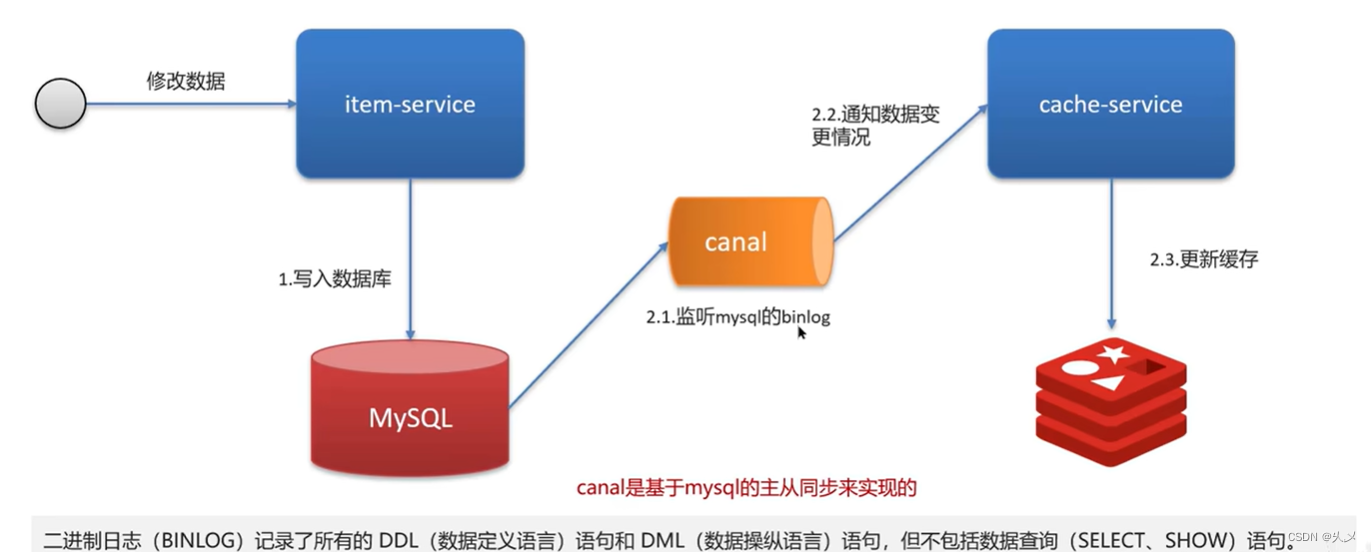
模拟面试
强一致性回答:

最终一致性回答:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









