







索引概念的引入
简单的索引设计
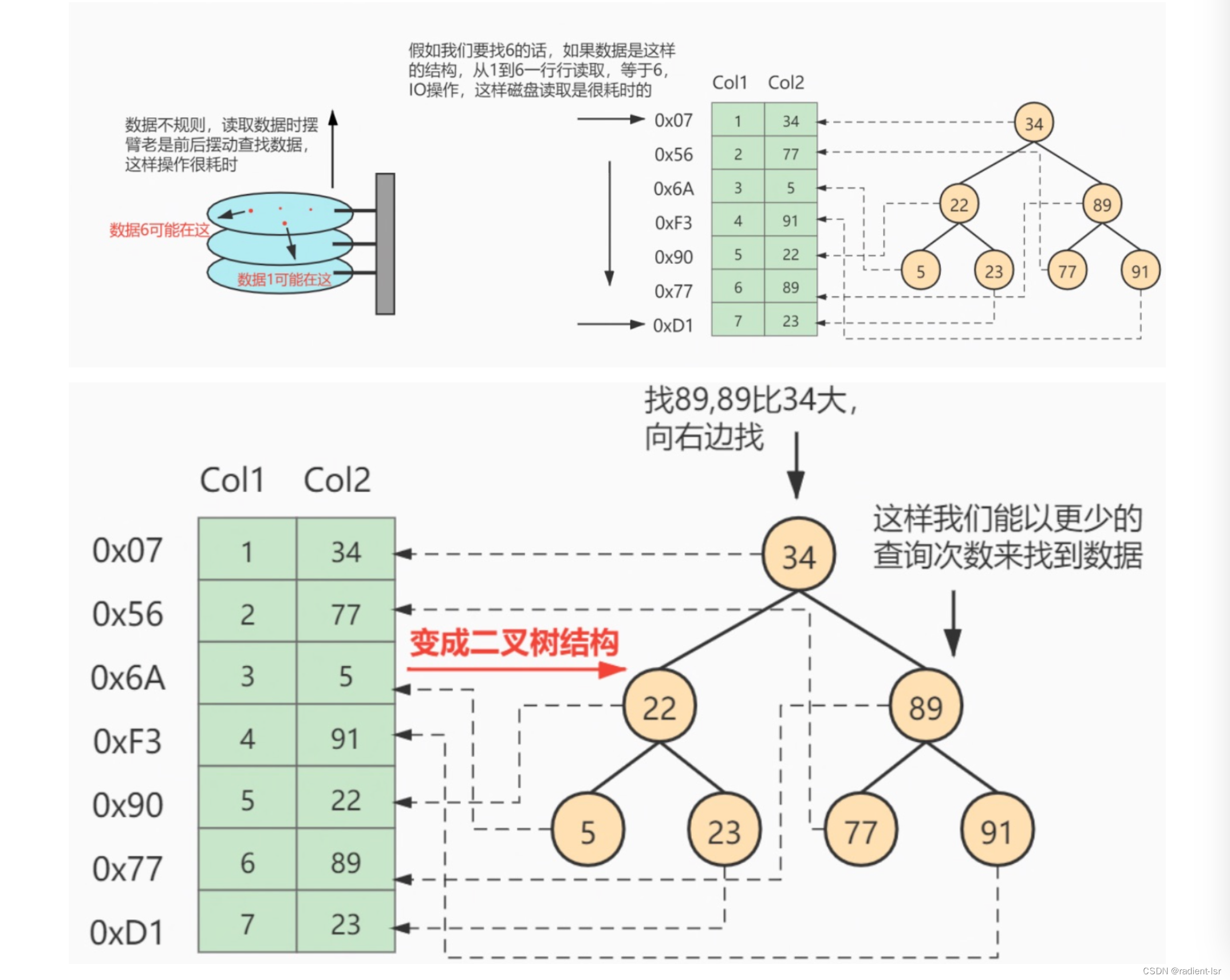
我们在根据某个搜索条件查找一些记录时,为什么要遍历所有的数据页?
因为各个页中的记录没有规律,我们并不知道我们的搜索条件匹配哪些页中的记录,所以不得不依次遍历所有的数据页。
所以如果我们想快速定位到需要查找到记录在哪些数据页中该怎么办?
我们可以为快速定位记录所在的数据页单独建立一个目录,建这个目录必须完成下边这些事 :
- 下一个数据页中,用户记录的主键值必须大于上一个页中用户记录的主键值
- 给所有的页建立一个目录项
索引的存储结构 — B+树
我们存入数据库的数据都是一行一行存的,那么这些数据被保存到数据库后,在数据库加载到缓冲池的时候是怎么加载的?
是按页加载的,一行行数据加载到一页页里面,也就是说我们的索引数据都是放在一页一页里面的,而一页的大小是16kb,
一个表中的数据就会有好多好多页,接着上面索引概念的引入,其实我们MySQL的InnoDB索引底层创建的索引结构是B+树
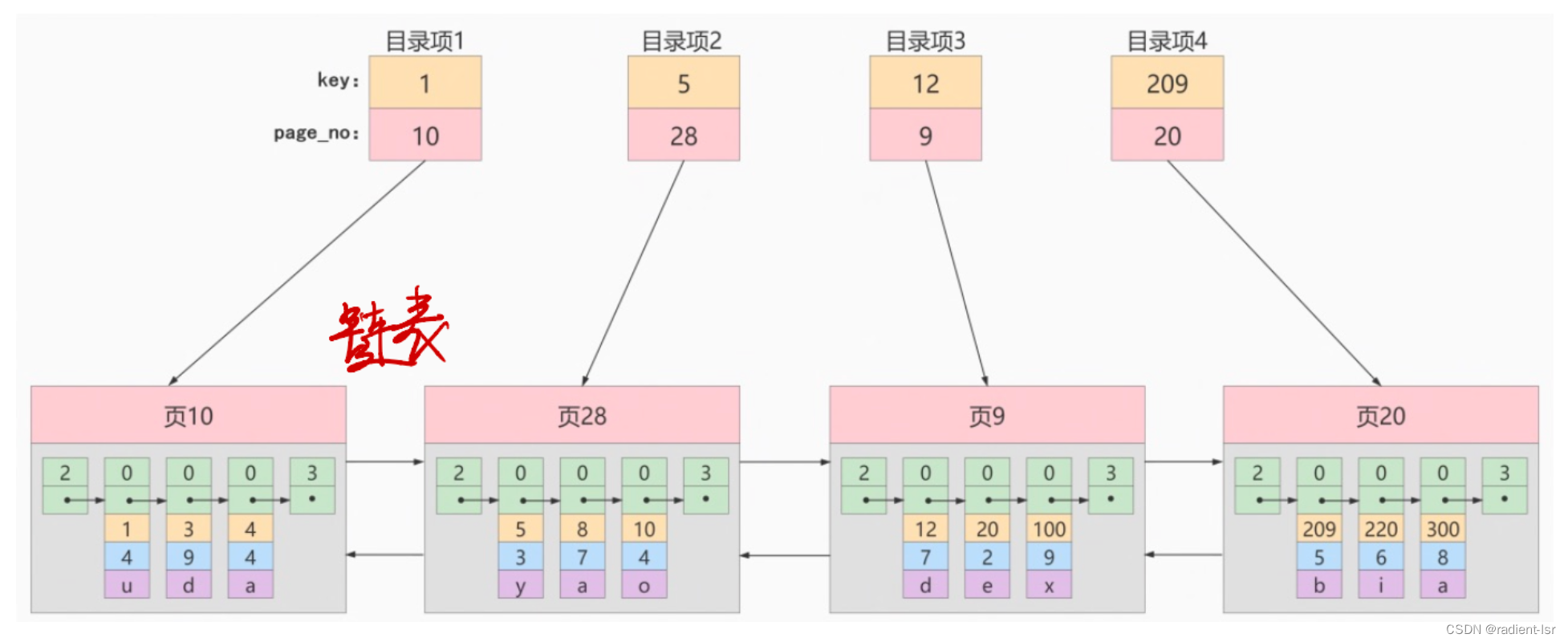
目录页保存的是所保存的数据页的 主键值的最小值 和 数据页的页数
目录页的目录页保存的是目录页的 主键值的最小值 和 目录页的页数
- 迭代一次
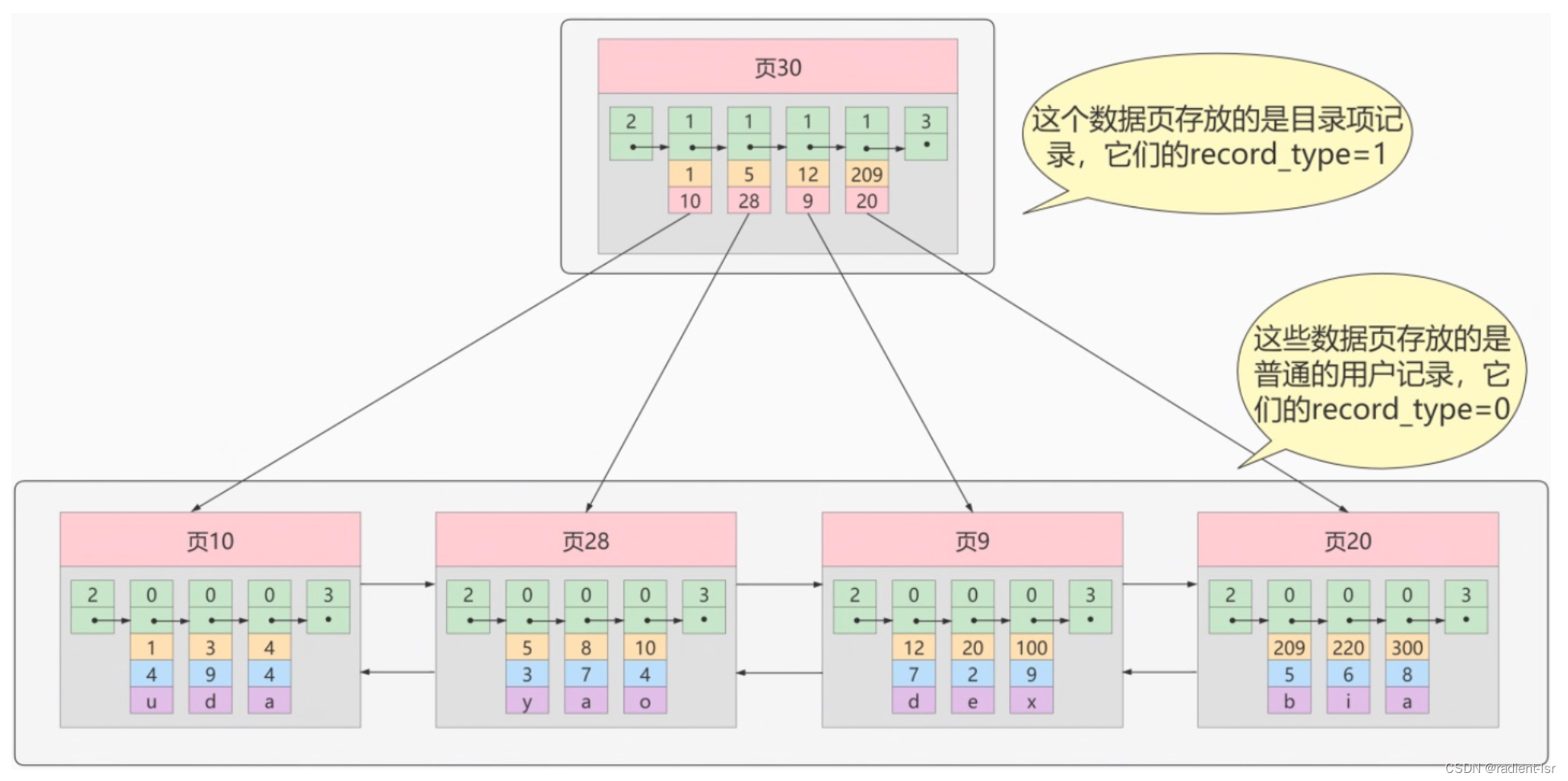
- 当数据页增多后,一个目录页已经不足以放得下那么多数据页的目录的时候,就会再开辟一个目录页保存数据页数据
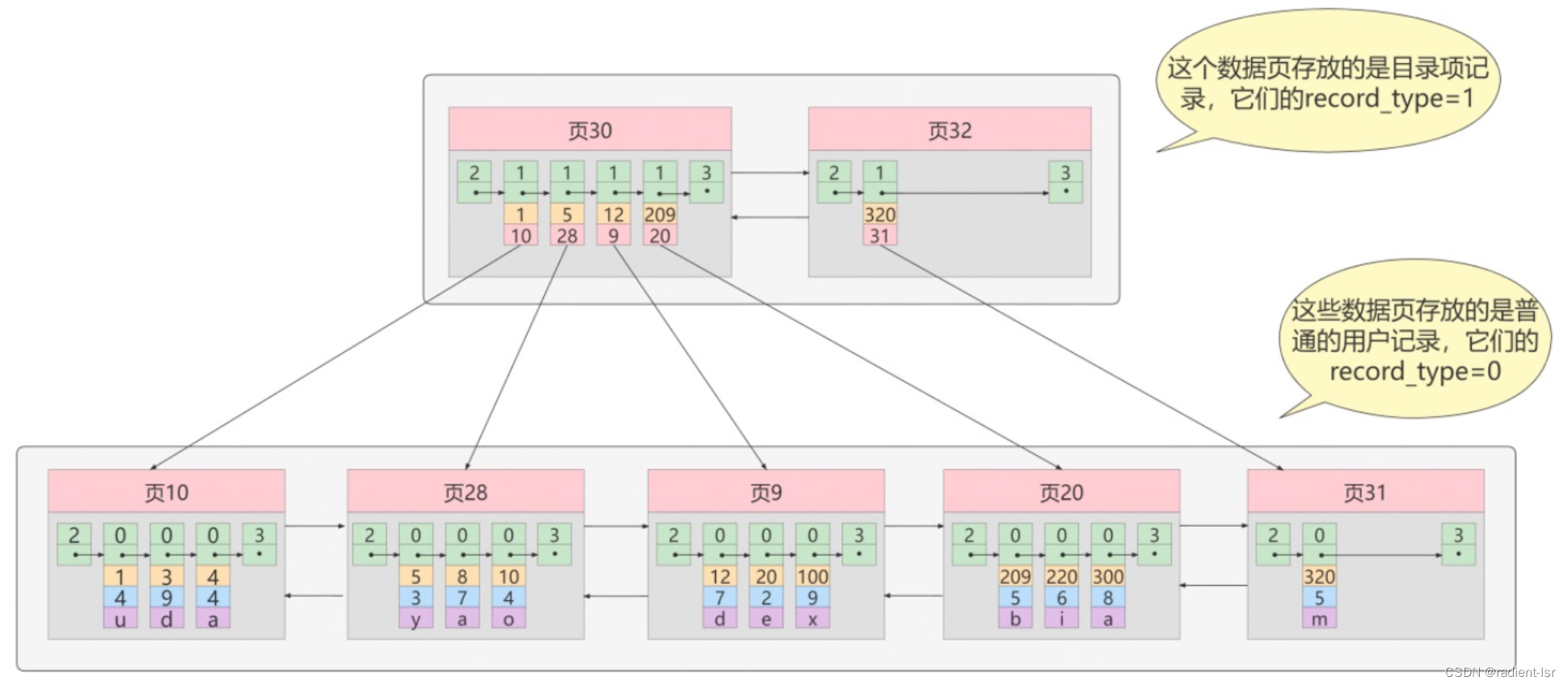
- 我们注意到目录页一多,也会出现查找可能需要O(n)的情况,这个时候就需要我们的目录页的目录页
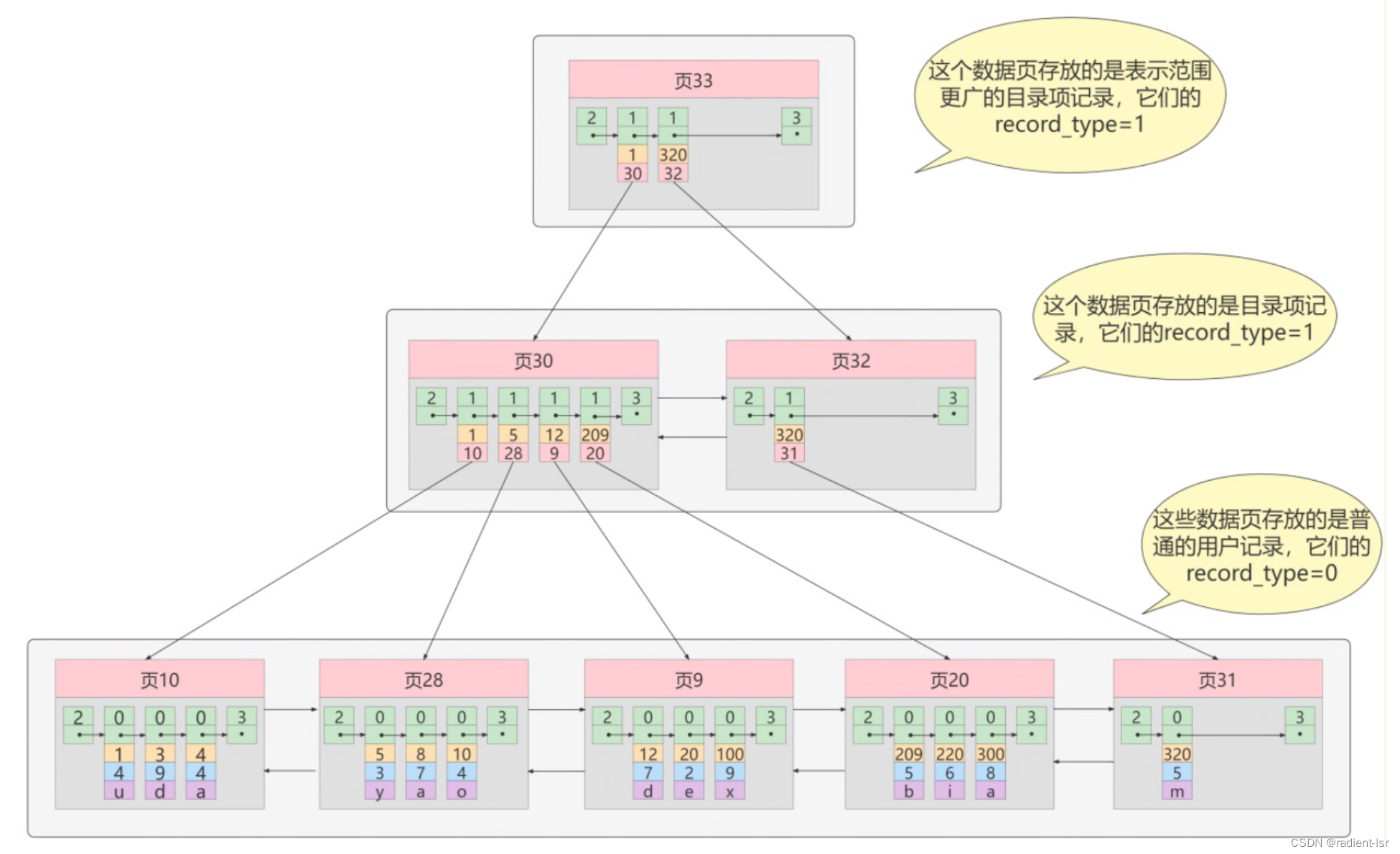
B+树底层是怎么生成的
InnoDB中的B+树是通过递归的方式生成的,从根节点开始,逐层生成叶子节点。
生成B+树的过程中,首先会生成目录页,然后再生成数据页。
生成B+树的步骤如下:
- 创建根节点:首先创建一个空的根节点,并给其分配一个页号。根节点是一个目录页。
- 生成目录页:从根节点开始生成目录页。目录页包含指针,指向下一层的页节点,这些指针可以跳过一定数量的数据页,以提高检索效率。
- 生成数据页:在叶子层生成数据页,每个数据页存储了具体的数据记录。数据页是叶子节点。
- 递归生成树:通过递归的方式,在每个目录页上生成下一层的目录页和数据页,直到达到B+树的要求。
需要注意的是,InnoDB中的B+树是自平衡的,当插入或删除数据时,会自动重新调整树结构,以保持树的平衡性和性能。同时,InnoDB也会利用缓冲池来提高B+树的访问速度,将经常被访问的页放入缓冲池中。
B+树能存多少数据
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
上文我们已经说明单个叶子节点(页)中的记录数=16K/1K=16。(这里假设一行记录的数据大小为1k,实际上现在很多互联网业务数据记录大小通常就是1K左右)。
那么现在我们需要计算出非叶子节点能存放多少指针?
其实这也很好算,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170*1170*16=21902400条这样的记录。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
总结 :单表存储的数据其实根本存不到千万级别,因为一旦数据超过500万条数据,就要开始考虑分库分表了,所以B+树完全够用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









