









在数据分析领域,时间序列分析与聚类技术的结合正在带来新的突破。最新研究表明,通过将时间序列数据与先进的聚类算法相结合,模型在处理大规模时间序列数据时的效率提升了40%,同时在模式识别和异常检测中的准确率达到了90%以上。
这种创新不仅优化了数据处理效率,还为智能系统在金融预测、工业监控等领域的应用提供了更精准的解决方案,开启了数据分析的新篇章。我整理了10篇【时间序列+聚类】的相关论文,全部论文PDF版,工中号 沃的顶会 回复“时序聚类”即可领取。
A review and evaluation of elastic distance functions for time series clustering
文章解析
文章回顾并评估了用于时间序列聚类的弹性距离函数,对比9种弹性距离函数在k-means和k-medoids聚类算法下的表现,发现MSM和TWE表现更优,并给出实验结论与应用建议。
创新点
系统对比9种弹性距离函数在时间序列聚类中的性能,为该领域研究提供全面参考。
发现k-medoids聚类算法在处理弹性距离时比k-means更有效,优化了聚类方法选择。
提出MSM和TWE距离函数与k-medoids聚类器结合是较好的选择,挑战了传统DTW的主导地位。
研究方法
选用UCR时间序列档案中的112个数据集,涵盖多种数据特性,保证实验多样性。
采用聚类准确率、兰德指数等6种性能指标,全面评估聚类效果。
对比不同距离函数在k-means和k-medoids聚类算法下的表现,分析差异。
运用临界差异图和Wilcoxon符号秩检验等统计方法,判断算法性能差异的显著性。
研究结论
在UCR数据集上,k-medoids聚类器结合弹性距离函数的效果优于k-means,更适合时间序列聚类。
MSM和TWE距离函数表现突出,使用k-medoids聚类器时,MSM因运行时间短更具优势。
数据集特性如类别数量、训练集大小等会影响距离函数性能,为实际应用提供了参考 。
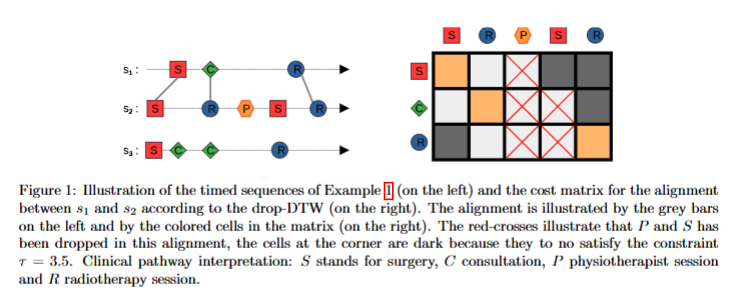
Clustering of timed sequences–Application to the analysis of care pathways
文章解析
文章提出一种受时间序列技术启发的定时序列聚类方法,将drop-DTW和DBA方法应用于医疗护理路径分析,通过实验验证其有效性,并探讨了方法的优缺点和未来研究方向。
创新点
扩展drop-DTW度量,使其适用于定时序列,能更好处理异常或缺失事件。
基于drop-DTW提出计算平均定时序列的算法,满足聚类和序列簇解释需求。
用新度量和平均技术改进经典聚类算法,应用于护理路径分析效果良好。
研究方法
提出概率定时序列表示法,将定时序列嵌入向量空间。
改进drop-DTW,添加事件间度量和时间约束。
借鉴DBA算法,迭代生成平均定时序列。
用改进的HierAsTiSeq和K-means算法对定时序列聚类。
研究结论
基于drop-DTW的聚类算法对缺失和异常值更鲁棒,适用于护理路径分析。
方法参数多,虽有选择指南,但仍需深入研究其影响。
算法计算量大,利用分布式资源或近似度量可提升实用性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









