









在人工智能的创意浪潮中,文本图像生成与扩散模型的结合正引领着视觉内容创作的新变革。最新研究显示,通过将文本生成技术与先进的扩散模型深度融合,不仅能够根据用户输入的简单文本快速生成高质量、高分辨率的图像,还能在生成过程中实现对细节和风格的精准控制。
这种创新技术在图像生成的速度和质量上都取得了显著突破,生成时间缩短了60%,同时图像的逼真度和多样性提升了80%。从艺术创作到商业设计,从虚拟现实到游戏开发,文本图像生成与扩散模型的结合正为视觉内容的智能化创作开辟无限可能,开启创意表达的新纪元。我整理了10篇【文本图像生成+扩散模型】的相关论文,全部论文PDF版,工中号 沃的顶会 回复“图文扩散”即可领取
Energy-Guided Optimization for Personalized Image Editing with Pretrained Text-to-Image Diffusion Models
文章解析
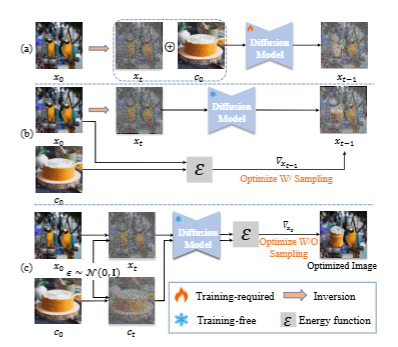
本文提出了一种无需训练的框架,通过将个性化内容编辑定义为在潜空间中优化编辑图像的问题,利用扩散模型作为参考文本-图像对条件下的能量函数指导。
该方法采用粗到细策略,结合点对点特征级图像能量引导和潜空间内容组合操作,实现目标对象的身份一致性与自然过渡。
创新点
首次将个性化图像编辑问题建模为基于扩散模型文本-图像能量引导的条件优化任务。
提出了一种能量引导优化框架(EGO-Edit),包含粗到细优化策略以及潜空间内容组合操作,提升稳定性与一致性。
能够在跨类别对象替换等困难场景中生成高质量的编辑结果。
研究方法
使用参考文本和图像作为查询,并以扩散模型作为条件能量函数进行优化。
设计基于替换的内容组合操作,将目标信息集成到潜变量中以提高身份一致性。
提出按降序调度扩散模型的时间步长,并仅在早期迭代中使用文本引导,以实现从粗到细的优化。
利用截断和平滑技术处理梯度,确保背景信息保留和目标对象的和谐融合。
研究结论
所提方法在对象交换和修复等个性化图像编辑任务中表现出色,尤其在困难案例中能够生成期望的编辑结果。
无需额外训练或倒置步骤即可实现高一致性和高质量的个性化编辑。
为解决任意对象和复杂场景中的个性化内容编辑挑战提供了有效解决方案。
DiT-Air:Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
文章解析
本文通过实证研究了用于文本到图像生成的扩散Transformer(DiT)的架构选择、文本条件策略和训练协议。研究表明,标准DiT在性能上与专门模型相当,并具有更高的参数效率;通过分层参数共享策略,进一步减少模型规模66%。
基于深入分析关键组件如文本编码器和VAE,提出DiT-Air和DiT-Air-Lite,分别在GenEval和T2I CompBench上达到SOTA性能。
创新点
发现标准DiT架构在性能上与专用模型相当且更高效。
引入DiT-Air和DiT-Air-Lite新型模型家族,直接处理拼接的文本和噪声输入。
采用分层参数共享策略,显著降低模型大小。
改进文本编码器和VAE设计以提升生成质量和对齐能力。
研究方法
对比分析vanilla DiT、PixArt-α和MMDiT,开发简化架构。
评估不同文本编码器(CLIP、LLM、T5)及因果与双向CLIP的层选择策略。
引入优化的VAE设计以保留细粒度视觉细节。
通过渐进训练方法提高模型性能。
研究结论
标准DiT架构在扩展后表现出优异的参数效率。
分层参数共享策略可显著减少模型大小而不影响性能。
DiT-Air和DiT-Air-Lite在GenEval和T2I CompBench上实现新的SOTA性能。
紧凑型模型DiT-Air-Lite仍能超越大多数现有模型。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









