







 本文介绍了一种使用逻辑斯蒂回归进行信用卡欺诈检测的方法。通过详细步骤展示了数据预处理、模型训练及评估的过程,并讨论了逻辑斯蒂回归作为二分类算法的特点。
本文介绍了一种使用逻辑斯蒂回归进行信用卡欺诈检测的方法。通过详细步骤展示了数据预处理、模型训练及评估的过程,并讨论了逻辑斯蒂回归作为二分类算法的特点。
一、分类模型评价指标
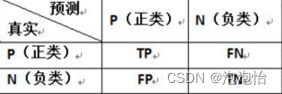

某一类的精准率precision—其实预测为该类并且预测正确的比例。
某一类的精准率recall—其实就是该类有多少被预测出来。
二、逻辑斯蒂回归
(一)、逻辑斯蒂回归叫回归,但实际上它是二分类算法;也可以实现多分类算法,也就是多次利用二分类算法实现多分类。
- 训练数据可以是离散型也可以是连续性特征。
- 逻辑斯蒂回归本质上也是线性分类器,就是线性函数曲线将超平面分成两部分;也可以实现非线性。
- 过拟合和线性回归同样办法。
- 出现欠拟合问题,处理增加新的特征变量,也可以增加多项式特征。
(二) 逻辑斯蒂回归函数
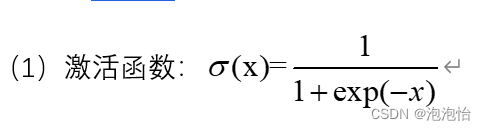
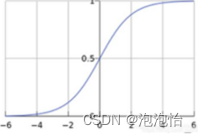
函数图像如图:
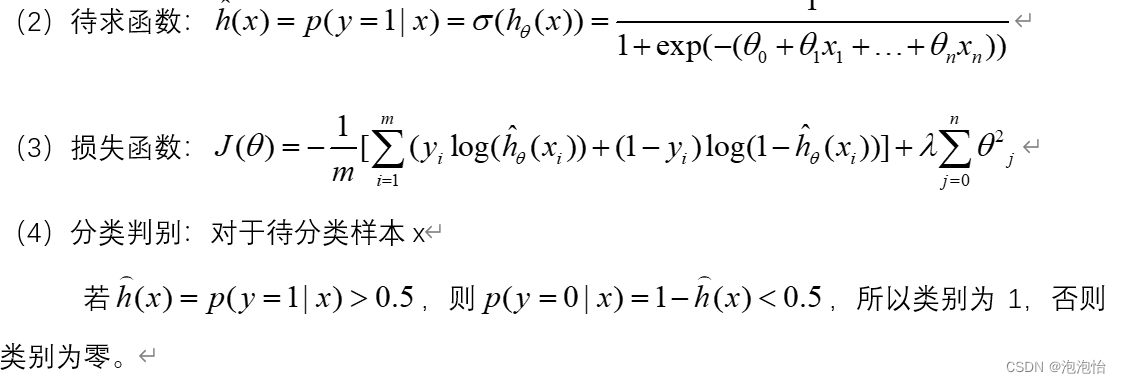
所以在最后的判别方法为:
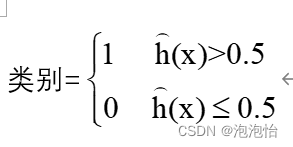
三、信用卡诈骗分类
首先介绍一下sklearn包中的分类器:
- from sklearn.linear_model import LogisticRegression 这个分类器可以设置正则化功能,但只能做L2正则化。
- from sklearn.linear_model import LogisticRegressionCV 带有参数遍历功能选择超参数alpha
- from sklearn.linear_model import SGDClassifier 可以设置正则化功能,并且是随机梯度分类器,数据量大的时候用这个
(1)导包
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
import imblearn
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split(2)读入数据AND数据预处理
data=pd.read_csv('./data_picture/chapter4/creditcard.csv')
X = data.drop('Class',axis=1)
y = data['Class']
X=X.drop('Time',axis=1)
X['Amount'] = (X['Amount'] - X['Amount'].min()) /(X['Amount'].max() - X['Amount'].min())
data.head()结果如图:
(3)分数据集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=1)(4)模型训练
from sklearn.linear_model import LogisticRegression,LogisticRegressionCV,SGDClassifier
model = LogisticRegression(penalty='l2',random_state=33)
model.fit(X_train, y_train) (5)模型评价
ypred1=model.predict(X_test) #预测测试集各样本的类别
ypred2=model.predict_proba(X_test) #预测测试集每个样本属于各类的概率
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
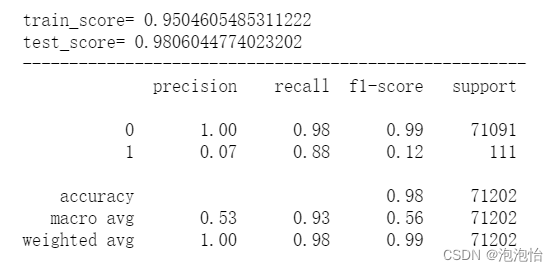
print('train_score=',train_score)
print('test_score=',test_score)
print('------------------------------------------------------')
y_predict=model.predict(X_test)
model_report=classification_report(y_test,y_predict)
print(model_report)结果如图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









