







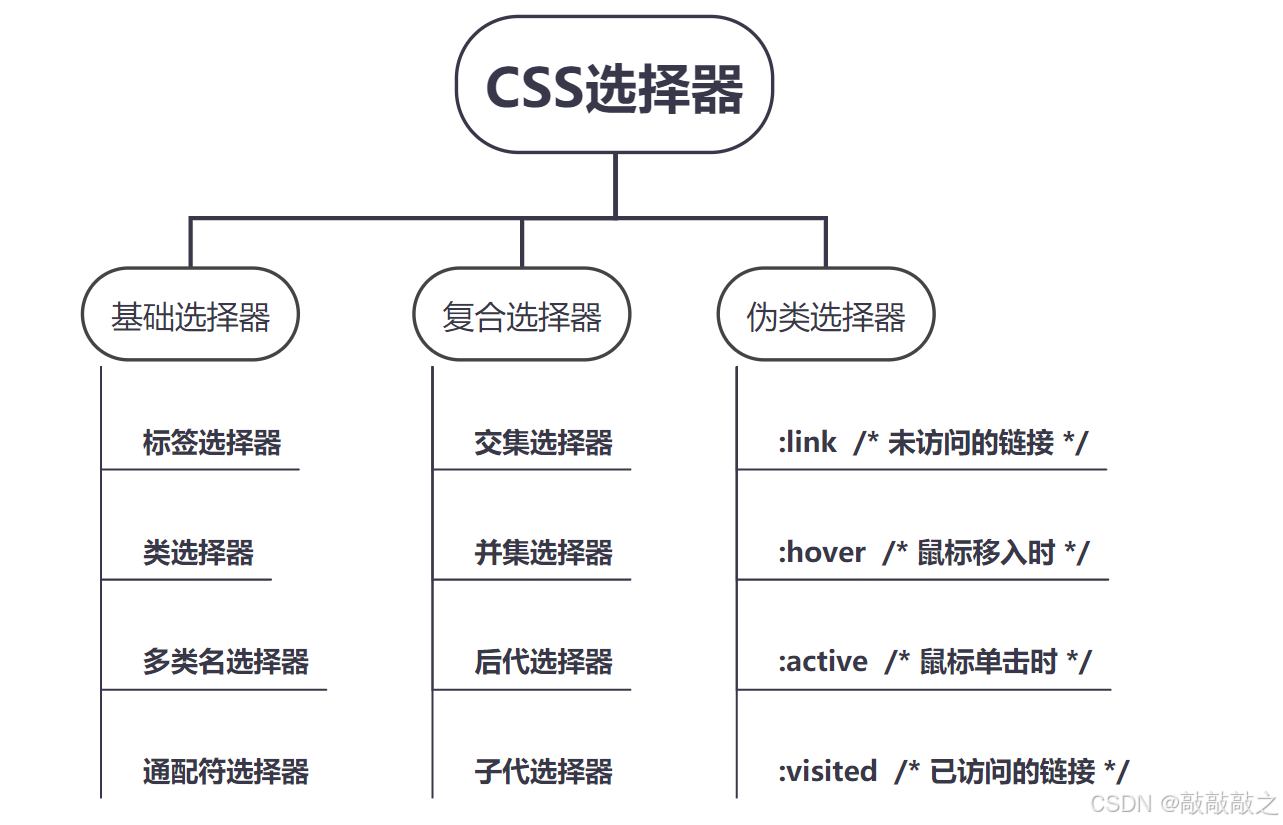
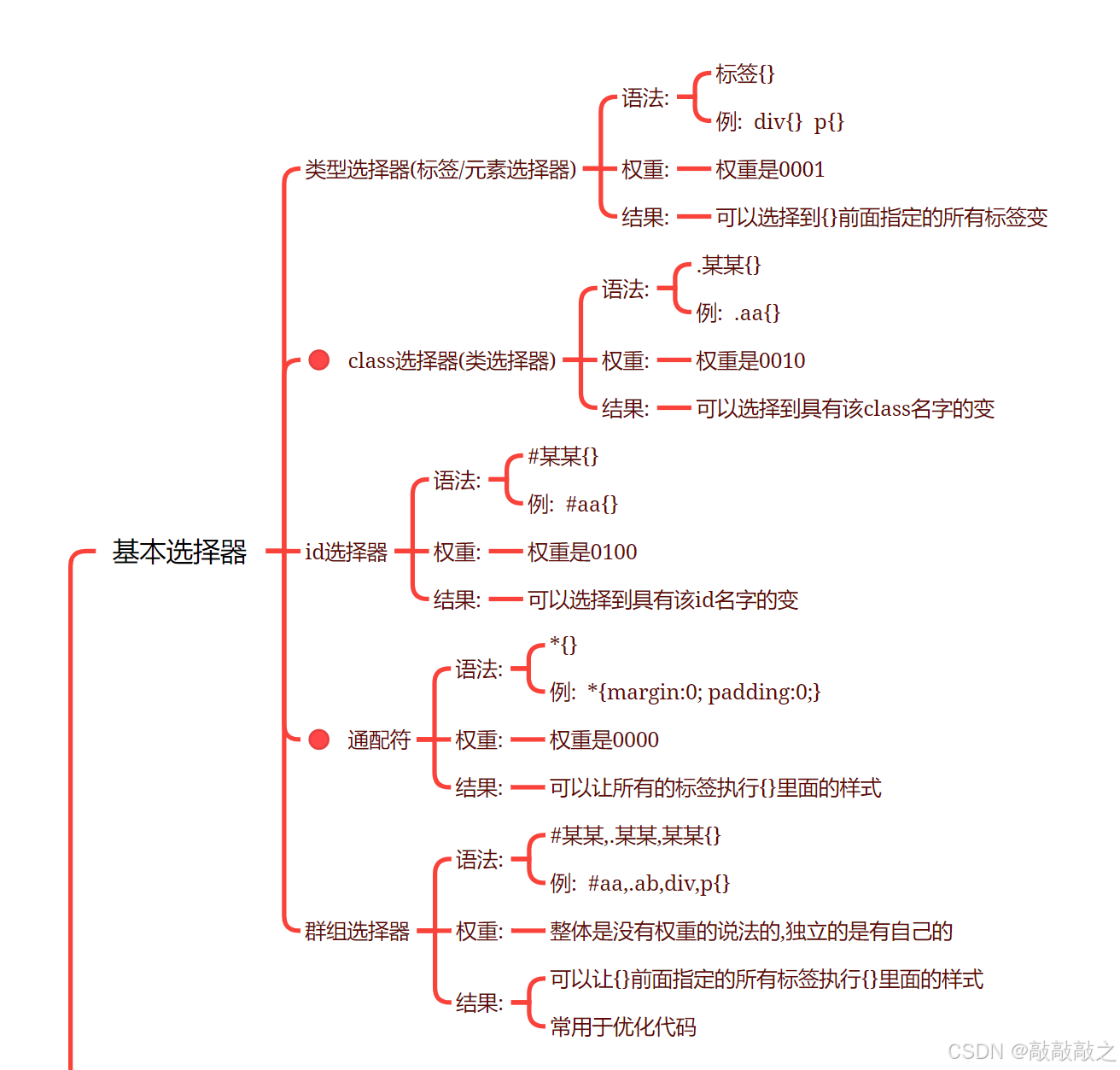
基础选择器
(1)、标签选择器(元素选择器)
标签选择器是指用HTML标签名称作为选择器,按标签名称分类,为页面中某一类标签指定统一的CSS样式。其基本语法格式如下:
标签名{属性1:属性值1; 属性2:属性值2; 属性3:属性值3; } 或者
元素名{属性1:属性值1; 属性2:属性值2; 属性3:属性值3; }
特点:
1. 标签选择器能快速为页面中同类型的标签统一样式,同时这也是他的缺点,不能设计差异化样式。
2. 标签选择器可以把某一类标签全部选择出来。
(2)、类选择器
类选择器使用“.”(英文点号)进行标识,后面紧跟类名,其基本语法格式如下:
.类名{属性1:属性值1; 属性2:属性值2; 属性3:属性值3; }
标签调用的时候用class=“类名”即可。
类选择器的优势:
1. 可以为元素对象定义单独或相同的样式。可以选择一个或者多个标签。
小技巧:
1.长名称或词组可以使用中横线来为选择器命名。 2.不建议使用“_”下划线来命名CSS选择器。 3.不要纯数字、中文等命名,尽量使用英文字母来表示。
(3)、多类名选择器
我们可以给标签指定多个类名,从而达到更多的选择目的。
注意:
1. 样式显示效果跟HTML元素中的类名先后顺序没有关系,与CSS样式书写的上下顺序有关。
2. 各个类名中间用空格隔开。
多类名选择器在后期布局比较复杂的情况下,还是较多使用的。

(4)、id选择器
id选择器使用“#”进行标识,后面紧跟id名,其基本语法格式如下:
#id名{属性1:属性值1; 属性2:属性值2; 属性3:属性值3; }
该语法中,id名即为HTML元素的id属性值,大多数HTML元素都可以定义id属性,元素的id值是唯一的,只能对应于文档中某一个具体的元素。用法基本和类选择器相同。
id选择器和类选择器区别
W3C规定,在同一个页面不允许有相同名字的id对象出现,但是允许相同名字的class。
类选择器(class)好比人的名字,可以多次重复使用的,比如:张伟、王伟、李伟、李娜。
id选择器好比人的身份证号码,全中国是唯一的,不得重复。
id选择器和类选择器最大的不同在于使用次数上。
(5)、通配符选择器
通配符选择器用“*”号表示,他是所有选择器中作用范围最广的,能匹配页面中所有的元素。其基本语法格式如下:
* { 属性1:属性值1; 属性2:属性值2; 属性3:属性值3; }
例如下面的代码,使用通配符选择器定义CSS样式,清除所有HTML标记的默认边距。
* {
margin: 0; /* 定义外边距*/
padding: 0; /* 定义内边距*/}
注意:
这个通配符选择器,就像我们的电影明星中的梦中情人, 想想它就好了,但是它不会和你过日子。 我们一般不使用它。
层级选择器
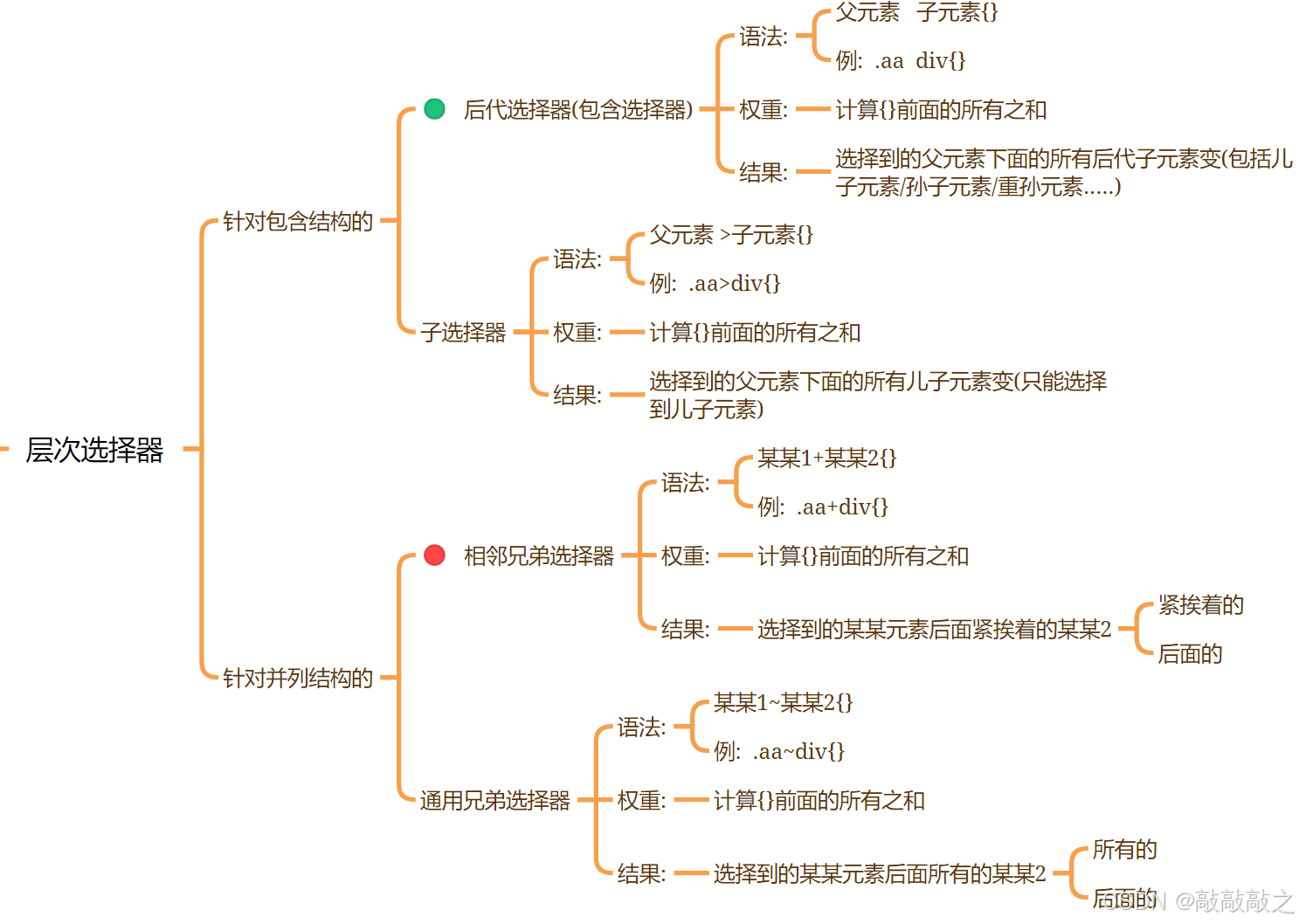
复合选择器(层次选择器)是由两个或多个基础选择器,通过不同的方式组合而成的,目的是为了可以选择更准确更精细的目标元素标签。
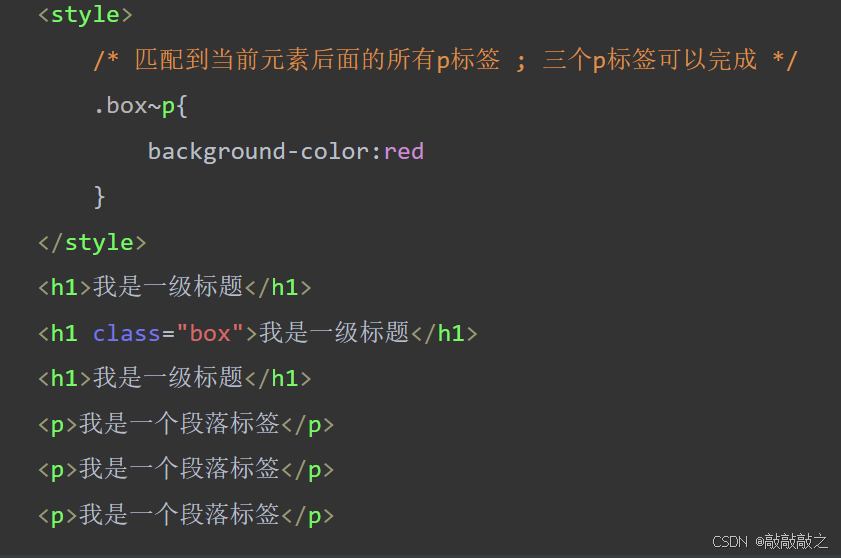
(1)、交集选择器
交集选择器由两个选择器构成,其中第一个为标签选择器,第二个为class选择器,两个选择器之间不能有空格,如h3.special。
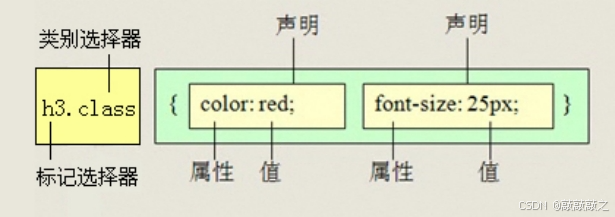
记忆技巧:交集选择器是并且的意思。 即...又...的意思
比如:p.one选择的是类名为.one的段落标签。
(2)、并集选择器
并集选择器(CSS选择器分组)是各个选择器通过逗号连接而成的,任何形式的选择器(包括标签选择器、class类选择器id选择器等),都可以作为并集选择器的一部分。如果某些选择器定义的样式完全相同,或部分相同,就可以利用并集选择器为它们定义相同的CSS样式。
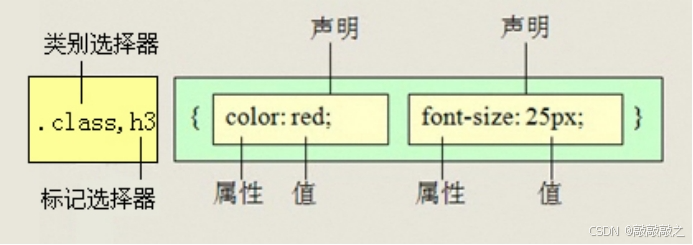
记忆技巧:并集选择器是和的意思,就是说,只要逗号隔开的,所有选择器都会执行后面样式。
比如:.one, p, #test{color: #F00;}表示.one和p和#test这三个选择器都会执行颜色为红色。通常用于集体声明。
(3)、后代选择器
后代选择器又称为包含选择器,用来选择元素或元素组的后代,其写法就是把外层标签写在前面,内层标签写在后面,中间用空格分隔。当标签发生嵌套时,内层标签就成为外层标签的后代。
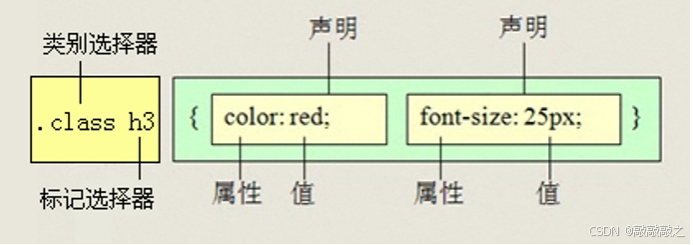
子孙后代都可以这么选择。 或者说,它能选择任何包含在内的标签。
(4)、子代选择器
子元素选择器只能选择作为某元素子元素的元素。其写法就是把父级标签写在前面,子级标签写在后面,中间跟一个>进行连接,注意,符号左右两侧各保留一个空格。
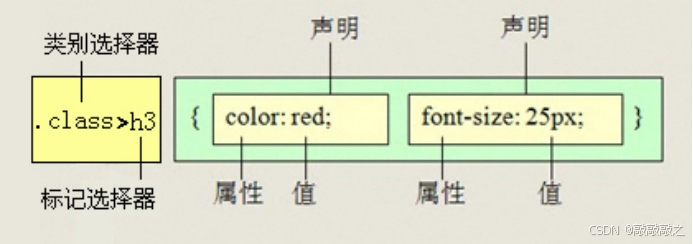
白话:这里的子,指的是亲儿子,不包含孙子、重孙子之类。
比如:.demo > h3 {color: red;}说明h3一定是demo亲儿子。demo元素包含着h3。
(5)相邻兄弟兄弟选择器
+
使用场景:想要修改某某1后面紧挨着的某某2
后面的紧挨着
语法:某某1+某某2{}

(6)通用兄弟选择器
~
使用场景:想要修改某某1后面所有的某某2
后面的所有的
语法:某某1~某某2{}
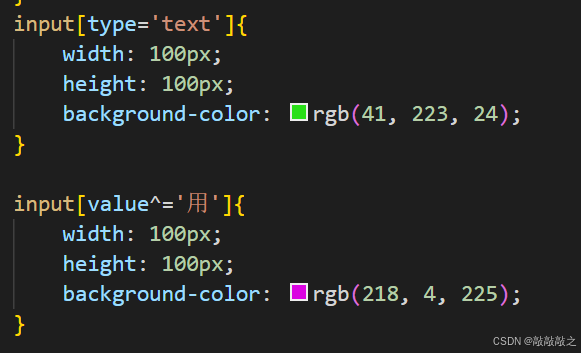
属性选择器

| [attribute] | [target] | 选择所有带有target属性元素 |
| [attribute=value] | [target=-blank] | 选择所有使用target="-blank"的元素 |
| [attribute~=value] | [title~=flower] | 选择标题属性包含单词"flower"的所有元素 |
| [attribute|=language] | [lang|=en] | 选择 lang 属性以 en- 为开头的所有元素(注意有个-) |
| [attribute^=value] | a[src^="https"] | 选择每一个src属性的值以"https"开头的元素 |
| [attribute$=value] | a[src$=".pdf"] | 选择每一个src属性的值以".pdf"结尾的元素 |
| [attribute*=value] | a[src*="runoob"] | 选择每一个src属性的值包含子字符串"runoob"的元素 |
伪类选择器
伪类选择器用于向某些选择器添加特殊的效果。比如给链接添加特殊效果,比如可以选择第1个,第n个元素。
为了和我们刚才学的类选择器相区别,类选择器是一个点,比如: .demo{}而我们的伪类用2个点就是冒号。比如:link{}
(1)、动态伪类选择器

:link /* 未访问的链接 */
:hover /* 鼠标移入时 */
:active /* 鼠标单击时 */
:visited /* 已访问的链接 */
:focus /*input获取焦点时*/
如果标签四个伪类的书写顺序不正确,会导致链接的四种状态显示效果错乱,或有的状态会无效,为了避免这种情况,我们在设置的时候,务必保证书写顺序是正确的如果错了需要清除缓存。也就是我们常说到的LVHA原则(大写字母就是它们的首字母)
标签伪类的书写顺序是a:link、a:visited、a:hover、a:active
(2)、结构伪类选择器
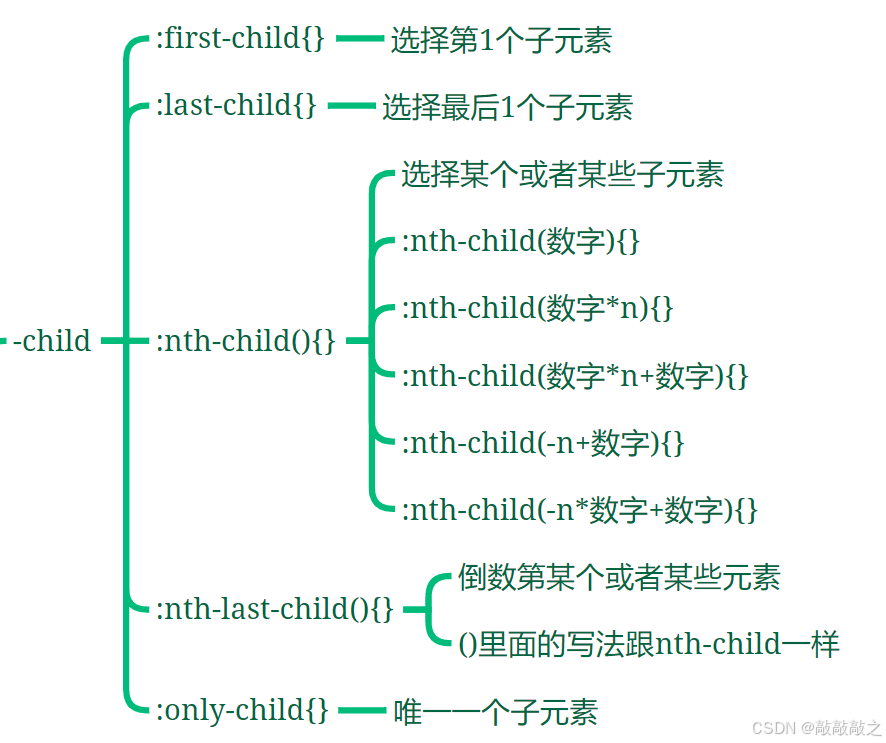



| :nth-child(n) | p:nth-child(2) | 选择每个p元素是其父级的第二个子元素 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 |
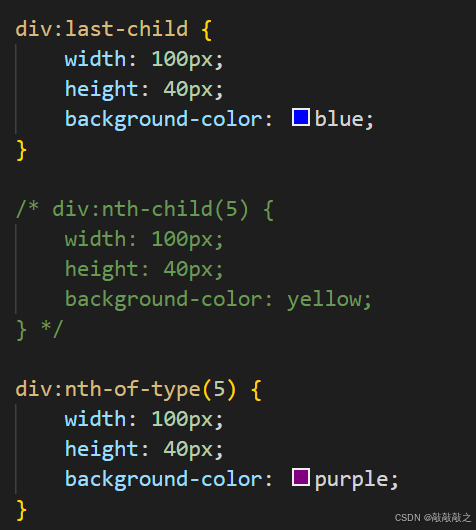
| :nth-of-type(n) | p:nth-of-type(2) | 选择每个p元素是其父级的第二个p元素 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 |
| :last-child | p:last-child | 指定只有选择每个p元素是其父级的最后一个子级。 |
| :first-child | p:first-child | 指定只有当 元素是其父级的第一个子级的样式 |
X:only-child这个伪类一般用的比较少,比如上述代码匹配的是div下的有且仅有一个的p,也就是说,如果div内有多个p,将不匹配。
X:root匹配文档的根元素。在HTML(标准通用标记语言下的一个应用)中,根元素永远是HTML
X:empty!匹配没有任何子元素(包括包含文本)的元素X
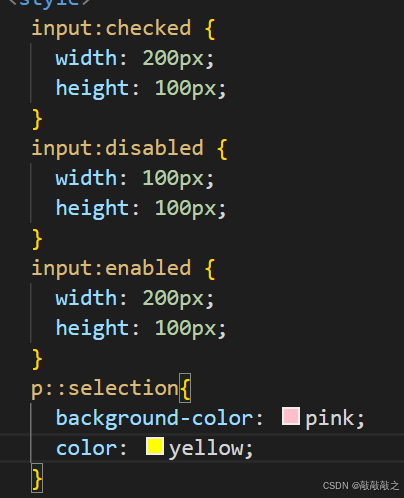
(3)、UI状态选择器

Ui元素状态伪类选择器
E:enabled匹配所有用户界面(form表单)中处于可用状态的E元素
E:disabled匹配所有用户界面(form表单)中处于不可用状态的E元素
E:checked匹配所有用户界面(form表单)中处于选中状态的元素E
E::selection匹配E元素中被用户选中或处于高亮状态的部分
(4)、否定伪类选择器

否定伪类选择器
E:not(s)(IE6-8浏览器不支持:not0选择器。)
匹配所有不匹配简单选择符s的元素E
(5)、目标伪类选择器

目标伪类选择器
E:target选择匹配E的所有元素,且匹配元素被相关URL指向
伪元素选择器
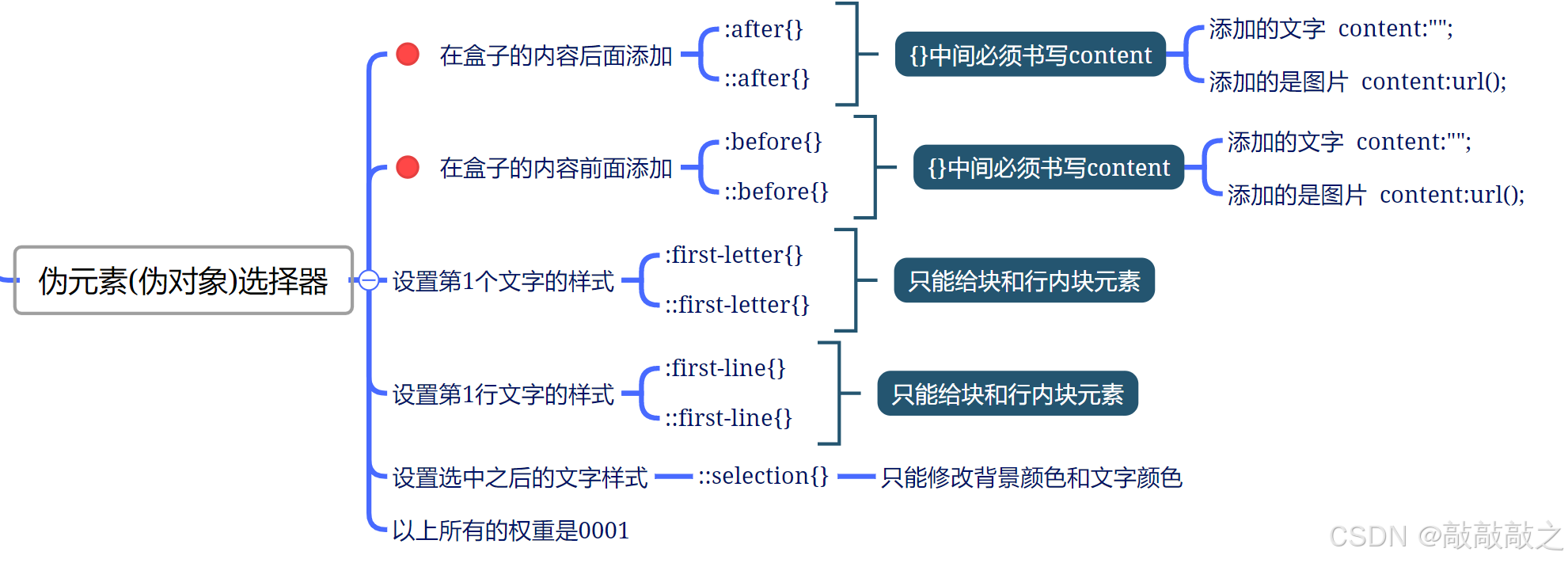

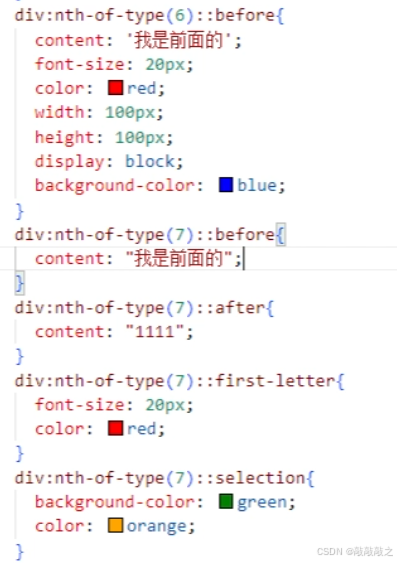
CSS3伪元素选择器
::after是在内容后边创建一个行内元素span,如果设置宽高需要转换成块:display:block
必须添加content,哪怕不设置内容,也需要content:””。
| ::first-letter | p::first-letter | 选择每一个 元素的第一个字母或者第一个汉字 |
| ::first-line | p::first-line | 选择每一个 元素的第一行 |
| ::before | p::before | 在每个 元素之前插入内容 |
| ::after | p::after | 在每个 元素之后插入内容 |
| ::selection | p::selection{} | 修改比如选中文字的颜色和背景色 |

















 5719
5719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









