







 本文详细分析了Java并发容器中的ConcurrentSkipListMap,它基于跳表数据结构,提供了线程安全的高效并发Map实现。文章介绍了类的结构、成员变量、构造函数、静态代码部分以及其内部的构成和基本原理。ConcurrentSkipListMap使用CAS操作实现无锁插入、删除和查找,保证了高并发场景下的性能。同时,文章还讨论了其重要的方法,如get、put、remove等操作的实现细节。虽然size方法不是恒定时间,但其平均操作时间复杂度为log(n)。
本文详细分析了Java并发容器中的ConcurrentSkipListMap,它基于跳表数据结构,提供了线程安全的高效并发Map实现。文章介绍了类的结构、成员变量、构造函数、静态代码部分以及其内部的构成和基本原理。ConcurrentSkipListMap使用CAS操作实现无锁插入、删除和查找,保证了高并发场景下的性能。同时,文章还讨论了其重要的方法,如get、put、remove等操作的实现细节。虽然size方法不是恒定时间,但其平均操作时间复杂度为log(n)。
在java Concurrnet包中,还有另外一个Map,这就是ConcurrentSkipListMap。这是一种采用了跳表的数据结构,也是redis中最常用的数据结构,今天来分析下这个并发容器。
1.类的基本结构及其成员变量
1.1 类的基本结构
ConcurrentSkipListMap也是java并发包下面的重要容器,其类的继承结构如下:
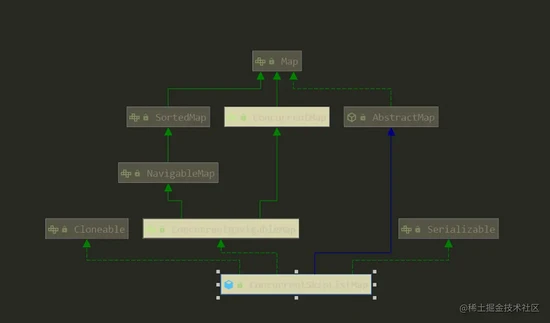
可以看到,ConcurrentSkipListMap的类的继承结构会比ConcurrentHashMap复杂一些。除了要继承AbstractMap类之外,还需要实现ConcurrentNavigableMap、Cloneable、Serializable等接口。ConcurrentNavigableMap接口是NavigableMap和ConcurrentMap功能的结合体,需要既能够实现线程安全,又能够提供导航搜素子Map视图的功能。
/**
* A scalable concurrent {@link ConcurrentNavigableMap} implementation.
* The map is sorted according to the {@linkplain Comparable natural
* ordering} of its keys, or by a {@link Comparator} provided at map
* creation time, depending on which constructor is used.
*
* <p>This class implements a concurrent variant of <a
* href="http://en.wikipedia.org/wiki/Skip_list" target="_top">SkipLists</a>
* providing expected average <i>log(n)</i> time cost for the
* {@code containsKey}, {@code get}, {@code put} and
* {@code remove} operations and their variants. Insertion, removal,
* update, and access operations safely execute concurrently by
* multiple threads.
*
* <p>Iterators and spliterators are
* <a href="package-summary.html#Weakly"><i>weakly consistent</i></a>.
*
* <p>Ascending key ordered views and their iterators are faster than
* descending ones.
*
* <p>All {@code Map.Entry} pairs returned by methods in this class
* and its views represent snapshots of mappings at the time they were
* produced. They do <em>not</em> support the {@code Entry.setValue}
* method. (Note however that it is possible to change mappings in the
* associated map using {@code put}, {@code putIfAbsent}, or
* {@code replace}, depending on exactly which effect you need.)
*
* <p>Beware that, unlike in most collections, the {@code size}
* method is <em>not</em> a constant-time operation. Because of the
* asynchronous nature of these maps, determining the current number
* of elements requires a traversal of the elements, and so may report
* inaccurate results if this collection is modified during traversal.
* Additionally, the bulk operations {@code putAll}, {@code equals},
* {@code toArray}, {@code containsValue}, and {@code clear} are
* <em>not</em> guaranteed to be performed atomically. For example, an
* iterator operating concurrently with a {@code putAll} operation
* might view only some of the added elements.
*
* <p>This class and its views and iterators implement all of the
* <em>optional</em> methods of the {@link Map} and {@link Iterator}
* interfaces. Like most other concurrent collections, this class does
* <em>not</em> permit the use of {@code null} keys or values because some
* null return values cannot be reliably distinguished from the absence of
* elements.
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @author Doug Lea
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
* @since 1.6
*/
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable {
}
复制代码
在类的开始部分,有大段的注释,其大意为:ConcurrnetSkipListMap是一个可扩展的并发Map的实现。其元素是根据Comparable的自然顺序进行排序的。排序或者由Comparator在创建map的时候提供。这取决于使用的构造函数。 这个类是SkipLists的并发版本实现,提供了平均时间复杂度为log(n)的containsKey、get、put和remove的操作及其变体,插入、访问、删除和更新操作以线程安全的方式在多线程的情况下执行。 Iterators和spliterators是弱一致性的,通过升序进行的迭代操作比降序要快。 所有Map.Entry类中的方法及其视图返回的对表示对Map操作时候的快照。他们不支持 Entry.setValue方法。但是请注意,可以使用put、putIfAbsent、replace更改关联Map中的映射。这取决于你需要的效果。 需要注意的是,与大多数集合操作不同的是,size方法不是一个恒定时间的操作。因为这些map的异步性,确定当前的数字的元素需要遍历所有元素,所以如果该集合在遍历的过程中被修改,则会导致size的结果不准确。 此外,批量操作putAll,equals、toArray、containsValue、clear是不能保证原子性的。例如,与putAll同时进行的迭代操作可能只能看到一些新添加的元素。 这个类及其视图和迭代器实现了Map和linkIterator接口的所有可选的方法,与大多数其他并发集合一样,这个类不允许使用null做为key和value,因为某些null返回值无法可靠的与缺少元素区分开。 这个类也是集合框架成员之一。 另外,在成员变量之前也有一大段注释:
/*
* This class implements a tree-like two-dimensionally linked skip
* list in which the index levels are represented in separate
* nodes from the base nodes holding data. There are two reasons
* for taking this approach instead of the usual array-based
* structure: 1) Array based implementations seem to encounter
* more complexity and overhead 2) We can use cheaper algorithms
* for the heavily-traversed index lists than can be used for the
* base lists. Here's a picture of some of the basics for a
* possible list with 2 levels of index:
*
* Head nodes Index nodes
* +-+ right +-+ +-+
* |2|---------------->| |--------------------->| |->null
* +-+ +-+ +-+
* | down | |
* v v v
* +-+ +-+ +-+ +-+ +-+ +-+
* |1|----------->| |->| |------>| |----------->| |------>| |->null
* +-+ +-+ +-+ +-+ +-+ +-+
* v | | | | |
* Nodes next v v v v v
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
* | |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
*
* The base lists use a variant of the HM linked ordered set
* algorithm. See Tim Harris, "A pragmatic implementation of
* non-blocking linked lists"
* http://www.cl.cam.ac.uk/~tlh20/publications.html and Maged
* Michael "High Performance Dynamic Lock-Free Hash Tables and
* List-Based Sets"
* http://www.research.ibm.com/people/m/michael/pubs.htm. The
* basic idea in these lists is to mark the "next" pointers of
* deleted nodes when deleting to avoid conflicts with concurrent
* insertions, and when traversing to keep track of triples
* (predecessor, node, successor) in order to detect when and how
* to unlink these deleted nodes.
*
* Rather than using mark-bits to mark list deletions (which can
* be slow and space-intensive using AtomicMarkedReference), nodes
* use direct CAS'able next pointers. On deletion, instead of
* marking a pointer, they splice in another node that can be
* thought of as standing for a marked pointer (indicating this by
* using otherwise impossible field values). Using plain nodes
* acts roughly like "boxed" implementations of marked pointers,
* but uses new nodes only when nodes are deleted, not for every
* link. This requires less space and supports faster
* traversal. Even if marked references were better supported by
* JVMs, traversal using this technique might still be faster
* because any search need only read ahead one more node than
* otherwise required (to check for trailing marker) rather than
* unmasking mark bits or whatever on each read.
*
* This approach maintains the essential property needed in the HM
* algorithm of changing the next-pointer of a deleted node so
* that any other CAS of it will fail, but implements the idea by
* changing the pointer to point to a different node, not by
* marking it. While it would be possible to further squeeze
* space by defining marker nodes not to have key/value fields, it
* isn't worth the extra type-testing overhead. The deletion
* markers are rarely encountered during traversal and are
* normally quickly garbage collected. (Note that this technique
* would not work well in systems without garbage collection.)
*
* In addition to using deletion markers, the lists also use
* nullness of value fields to indicate deletion, in a style
* similar to typical lazy-deletion schemes. If a node's value is
* null, then it is considered logically deleted and ignored even
* though it is still reachable. This maintains proper control of
* concurrent replace vs delete operations -- an attempted replace
* must fail if a delete beat it by nulling field, and a delete
* must return the last non-null value held in the field. (Note:
* Null, rather than some special marker, is used for value fields
* here because it just so happens to mesh with the Map API
* requirement that method get returns null if there is no
* mapping, which allows nodes to remain concurrently readable
* even when deleted. Using any other marker value here would be
* messy at best.)
*
* Here's the sequence of events for a deletion of node n with
* predecessor b and successor f, initially:
*
* +------+ +------+ +------+
* ... | b |------>| n |----->| f | ...
* +------+ +------+ +------+
*
* 1. CAS n's value field from non-null to null.
* From this point on, no public operations encountering
* the node consider this mapping to exist. However, other
* ongoing insertions and deletions might still modify
* n's next pointer.
*
* 2. CAS n's next pointer to point to a new marker node.
* From this point on, no other nodes can be appended to n.
* which avoids deletion errors in CAS-based linked lists.
*
* +------+ +------+ +------+ +------+
* ... | b |------>| n |----->|marker|------>| f | ...
* +------+ +------+ +------+ +------+
*
* 3. CAS b's next pointer over both n and its marker.
* From this point on, no new traversals will encounter n,
* and it can eventually be GCed.
* +------+ +------+
* ... | b |----------------------------------->| f | ...
* +------+ +---
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









